|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese|
RESUMO DA AULA, CRIBS
Base de dados. Linguagem SQL (mais importante)
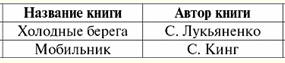
Diretório / Notas de aula, folhas de dicas Índice (expandir) Aula nº 6. Linguagem SQL Vamos primeiro dar um pouco de pano de fundo histórico. A linguagem SQL, projetada para interagir com bancos de dados, surgiu em meados da década de 1970. (primeiras publicações datam de 1974) e foi desenvolvido pela IBM como parte de um projeto experimental de sistema de gerenciamento de banco de dados relacional. O nome original da linguagem é SEQUEL (Structured English Query Language) - refletiu apenas parcialmente a essência dessa linguagem. Inicialmente, imediatamente após sua invenção e durante o período primário de operação da linguagem SQL, seu nome era uma abreviação da frase Structured Query Language, que se traduz como "Structured Query Language". Claro, a linguagem foi focada principalmente na formulação de consultas a bancos de dados relacionais que sejam convenientes e compreensíveis para os usuários. Mas, na verdade, quase desde o início, era uma linguagem de banco de dados completa, fornecendo, além dos meios de formulação de consultas e manipulação de bancos de dados, os seguintes recursos: 1) meios de definir e manipular o esquema do banco de dados; 2) meios para definir restrições e gatilhos de integridade (que serão mencionados posteriormente); 3) meios de definição de visualizações de banco de dados; 4) meios de definição de estruturas de camadas físicas que suportem a execução eficiente das requisições; 5) meio de autorização de acesso às relações e seus domínios. A linguagem não tinha os meios de sincronizar explicitamente o acesso a objetos de banco de dados do lado de transações paralelas: desde o início, assumiu-se que a sincronização necessária era realizada implicitamente pelo sistema de gerenciamento de banco de dados. Atualmente, SQL não é mais uma abreviação, mas o nome de uma linguagem independente. Além disso, atualmente, a linguagem de consulta estruturada é implementada em todos os sistemas comerciais de gerenciamento de banco de dados relacional e em quase todos os SGBDs que não foram originalmente baseados em uma abordagem relacional. Todas as empresas de manufatura afirmam que sua implementação está em conformidade com o padrão SQL e, de fato, os dialetos implementados da Structured Query Language são muito próximos. Isso não foi alcançado imediatamente. Uma característica dos sistemas de gerenciamento de banco de dados comerciais mais modernos que dificulta a comparação dos dialetos existentes do SQL é a falta de uma descrição uniforme da linguagem. Normalmente, a descrição está espalhada por vários manuais e misturada com uma descrição de recursos de linguagem específicos do sistema que não estão diretamente relacionados à linguagem de consulta estruturada. No entanto, pode-se dizer que o conjunto básico de instruções SQL, incluindo instruções para determinar o esquema do banco de dados, buscar e manipular dados, autorizar o acesso a dados, suporte para embutir SQL em linguagens de programação e instruções SQL dinâmicas, está bem estabelecido no mercado comercial. implementações e mais ou menos em conformidade com o padrão. Com o tempo e o trabalho na Structured Query Language, foi possível alcançar um padrão para uma padronização clara da sintaxe e semântica de instruções de recuperação de dados, manipulação de dados e correção de restrições de integridade do banco de dados. Foram especificados meios para definir as chaves primárias e estrangeiras de relacionamentos e as chamadas restrições de verificação de integridade, que são um subconjunto de restrições de integridade SQL verificadas imediatamente. As ferramentas para definir chaves estrangeiras facilitam a formulação dos requisitos da chamada integridade referencial de bancos de dados (sobre a qual falaremos mais adiante). Esse requisito, comum em bancos de dados relacionais, também poderia ser formulado com base no mecanismo geral de restrições de integridade SQL, mas a formulação baseada no conceito de chave estrangeira é mais simples e compreensível. Assim, levando em conta tudo isso, atualmente, a linguagem de consulta estruturada não é apenas o nome de uma linguagem, mas o nome de toda uma classe de linguagens, pois, apesar dos padrões existentes, vários dialetos da linguagem de consulta estruturada são implementados em vários sistemas de gerenciamento de banco de dados, que, é claro, têm uma base comum. 1. A instrução Select é a instrução básica da Structured Query Language O lugar central na linguagem de consulta estruturada SQL é ocupado pela instrução Select, que implementa a operação mais demandada ao trabalhar com bancos de dados - consultas. O operador Select avalia expressões de álgebra relacional e pseudo-relacional. Neste curso, consideraremos a implementação apenas das operações unárias e binárias da álgebra relacional que já abordamos, bem como a implementação de consultas usando as chamadas subconsultas. A propósito, deve-se notar que no caso de trabalhar com operações de álgebra relacional, tuplas duplicadas podem aparecer nas relações resultantes. Não há proibição estrita contra a presença de linhas duplicadas em relações nas regras da linguagem de consulta estruturada (diferentemente da álgebra relacional comum), portanto, não é necessário excluir duplicatas do resultado. Então, vamos ver a estrutura básica da instrução Select. É bastante simples e inclui as seguintes frases obrigatórias padrão: Selecione ... A partir de ... Onde... ; No lugar das reticências em cada linha devem estar as relações, atributos e condições de um determinado banco de dados e tarefas para ele. No caso mais geral, a estrutura básica Select deve ser assim: Selecionar selecione alguns atributos De de tal relacionamento Onde com tais e tais condições para amostragem de tuplas Assim, selecionamos atributos do esquema de relacionamento (títulos de algumas colunas), indicando de quais relacionamentos (e, como você pode ver, pode haver vários) fazemos nossa seleção e, finalmente, com base em quais condições paramos nossa escolha em certas tuplas. É importante observar que as referências de atributos são feitas usando seus nomes. Assim, obtém-se o seguinte algoritmo de trabalho esta instrução Select básica: 1) as condições para selecionar tuplas da relação são lembradas; 2) é verificado quais tuplas satisfazem as propriedades especificadas. Tais tuplas são lembradas; 3) os atributos listados na primeira linha da estrutura básica da instrução Select com seus valores são gerados. (Se falarmos sobre a forma tabular do relacionamento, serão exibidas essas colunas da tabela, cujos títulos foram listados como atributos necessários; é claro que as colunas não serão exibidas completamente, em cada uma delas apenas essas tuplas que satisfizeram as condições mencionadas permanecerão.) Considere um exemplo. Seja dada a seguinte relação r1, como um fragmento de algum banco de dados de livrarias:
Suponha que também tenhamos a seguinte expressão com a instrução Select: Selecionar Título do livro, Autor do livro De r1 Onde Preço do livro > 200; O resultado deste operador será o seguinte fragmento de tupla: (Telefone móvel, S. Rei). (A seguir, consideraremos muitos exemplos de implementações de consulta usando essa estrutura básica e estudaremos sua aplicação detalhadamente.) 2. Operações unárias na linguagem de consulta estruturada Nesta seção, consideraremos como as já familiares operações unárias de seleção, projeção e renomeação são implementadas na linguagem de consulta estruturada usando o operador Select. É importante notar que, se antes pudéssemos trabalhar apenas com operações individuais, mesmo um único operador Select no caso geral nos permite definir uma expressão de álgebra relacional inteira, e não apenas uma única operação. Então, passemos diretamente à análise da representação de operações unárias na linguagem de consultas estruturadas. 1. Operação de amostragem. A operação de seleção em SQL é implementada pela instrução Select da seguinte forma: Selecionar todos os atributos De nome da relação Onde condição de seleção; Aqui, em vez de escrever "todos os atributos", você pode usar o sinal "*". Na teoria da Linguagem de Consulta Estruturada, este ícone significa selecionar todos os atributos do esquema de relação. A condição de seleção aqui (e em todas as outras implementações de operações) é escrita como uma expressão lógica com conectivos padrão não (não) e (e) ou (ou). Os atributos de relacionamento são referidos por seus nomes. Considere um exemplo. Vamos definir o seguinte esquema de relação: performance acadêmica (Número do boletim de notas, semestre, código da disciplina, Classificação, Data); Aqui, como mencionado anteriormente, os atributos sublinhados formam a chave de relação. Vamos compor uma instrução Select da seguinte forma, que implementa a operação de seleção unária: Selecione * Do desempenho acadêmico Onde Boletim nº = 100 e Semestre = 6; É claro que, como resultado dessa declaração, a máquina exibirá o progresso de um aluno com número recorde cem para o sexto semestre. 2. Operação de projeção. A operação de projeção em Structured Query Language é ainda mais fácil de implementar do que a operação de busca. Lembre-se de que ao aplicar a operação de projeção, não são selecionadas linhas (como ao aplicar a operação de seleção), mas colunas. Portanto, basta listar os cabeçalhos das colunas desejadas (ou seja, nomes de atributos), sem especificar condições estranhas. No total, obtemos um operador da seguinte forma: Selecionar lista de nomes de atributos De nome da relação; Após aplicar esta instrução, a máquina retornará aquelas colunas da tabela de relações cujos nomes foram especificados na primeira linha desta instrução Select. Como mencionamos anteriormente, não é necessário excluir linhas e colunas duplicadas da relação resultante. Mas se em um pedido ou em uma tarefa for necessário eliminar duplicatas, você deve usar uma opção especial da linguagem de consulta estruturada - distinto. Esta opção define a eliminação automática de tuplas duplicadas da relação. Com esta opção aplicada, a instrução Select ficará assim: Selecionar lista distinta de nomes de atributos De nome da relação; Em SQL, existe uma notação especial para elementos opcionais de expressões - colchetes [...]. Portanto, na sua forma mais geral, a operação de projeção ficará assim: Selecionar [distinta] lista de nomes de atributos De nome da relação; No entanto, se o resultado da aplicação da operação for garantido para não conter duplicatas, ou duplicatas ainda são admissíveis, então a opção distinto é melhor não especificar para não sobrecarregar o registro, ou seja, por motivos de desempenho do operador. Vamos considerar um exemplo que ilustra a possibilidade de XNUMX% de confiança na ausência de duplicatas. Seja dado o esquema de relações já conhecido por nós: performance acadêmica (Número do boletim de notas, semestre, código da disciplina, Classificação, Data). Seja a seguinte instrução Select: Selecionar Número do boletim de notas, semestre, código da disciplina De performance acadêmica; Aqui, é fácil ver que os três atributos retornados pelo operador formam a chave da relação. Por isso a opção distinto torna-se redundante, porque é garantido que não haverá duplicatas. Isso decorre de um requisito nas chaves chamado de restrição exclusiva. Consideraremos essa propriedade com mais detalhes posteriormente, mas se o atributo for chave, não haverá duplicatas nele. 3. Renomear operação. A operação de renomear atributos na linguagem de consulta estruturada é bastante simples. Ou seja, é incorporado na realidade pelo seguinte algoritmo: 1) na lista de nomes de atributos da frase Selecionar, são listados os atributos que precisam ser renomeados; 2) a palavra-chave especial adicionada a cada atributo especificado; 3) após cada ocorrência da palavra as, é indicado o nome do atributo correspondente, ao qual é necessário alterar o nome original. Assim, levando em conta todo o exposto, a instrução correspondente à operação de renomeação de atributos ficará assim: Selecionar nome do atributo 1 como novo nome do atributo 1,... De nome da relação; Vamos mostrar como esse operador funciona com um exemplo. Seja dado o esquema de relacionamento que já nos é familiar: performance acadêmica (Número do boletim de notas, semestre, código da disciplina,Classificação, Data); Vamos ter uma ordem para alterar os nomes de alguns atributos, ou seja, em vez de "Número do livro de contas" deve haver "Número da conta" e em vez de "Pontuação" - "Pontuação". Vamos escrever como será a instrução Select que implementa essa operação de renomeação: Selecionar livro de registro como número de registro, semestre, código da disciplina, nota como pontuação, data De performance acadêmica; Assim, o resultado da aplicação deste operador será um novo esquema de relacionamento que difere do esquema de relacionamento original "Conquista" pelos nomes de dois atributos. 3. Operações binárias na linguagem de consultas estruturadas Assim como as operações unárias, as operações binárias também têm sua própria implementação na linguagem de consulta estruturada ou SQL. Então, vamos considerar a implementação nesta linguagem das operações binárias que já passamos, ou seja, as operações de união, interseção, diferença, produto cartesiano, junção natural, junção interna e esquerda, direita, junção externa completa. 1. Operação sindical. Para implementar a operação de combinação de duas relações, é necessário utilizar dois operadores Select simultaneamente, cada um dos quais correspondendo a um dos operandos-relações originais. E uma operação especial precisa ser aplicada a essas duas instruções Select básicas União. Considerando todos os itens acima, vamos escrever como será a operação de união usando a semântica da linguagem de consulta estruturada: Selecionar listar nomes de atributos da relação 1 De nome da relação 1 União Selecionar listar nomes de atributos da relação 2 De nome da relação 2; É importante observar que as listas de nomes de atributos dos dois relacionamentos que estão sendo unidos devem se referir a atributos de tipos compatíveis e ser listadas em ordem consistente. Se este requisito não for atendido, sua solicitação não poderá ser atendida e o computador exibirá uma mensagem de erro. Mas o que é interessante notar é que os próprios nomes de atributos nesses relacionamentos podem ser diferentes. Nesse caso, a relação resultante recebe os nomes de atributo especificados na primeira instrução Select. Você também precisa saber que o uso da operação Union exclui automaticamente todas as tuplas duplicadas da relação resultante. Portanto, se você precisar que todas as linhas duplicadas sejam preservadas no resultado final, em vez da operação União, você deve usar uma modificação desta operação - a operação União tudo. Nesse caso, a operação de combinar duas relações ficará assim: Selecionar listar nomes de atributos da relação 1 De nome da relação 1 União tudo Selecionar listar nomes de atributos da relação 2 De nome da relação 2; Neste caso, as tuplas duplicadas não serão removidas da relação resultante. Usando a notação mencionada anteriormente para elementos opcionais e opções em instruções Select, escrevemos a forma mais geral da operação de unir duas relações na linguagem de consulta estruturada: Selecionar listar nomes de atributos da relação 1 De nome da relação 1 União [Todos] Selecionar listar nomes de atributos da relação 2 De nome da relação 2; 2. Operação de interseção. A operação de interseção e a operação de diferença de duas relações na linguagem de consulta estruturada são implementadas de forma semelhante (consideramos o método de representação mais simples, pois quanto mais simples o método, mais econômico, mais relevante e, portanto, mais em demanda). Assim, vamos analisar a maneira de implementar a operação de interseção usando de chaves. Este método envolve a participação de duas construções Select, mas elas não são iguais (como na representação da operação de união), uma delas é, por assim dizer, uma "subconstrução", "subciclo". Esse operador é geralmente chamado subconsulta. Então, digamos que temos dois esquemas de relacionamento (R1 e R2), definido mais ou menos assim: R1 (chave,...) e R2 (chave,...); Ao gravar esta operação, também usaremos a opção especial in, que literalmente significa "em" ou (como neste caso específico) "contido em". Assim, levando em conta todo o exposto, a operação de intersecção de duas relações utilizando a linguagem de consulta estruturada será escrita da seguinte forma: Selecionar * De R1 Onde digite (Selecionar pista De R2); Assim, vemos que a subconsulta neste caso será o operador entre parênteses. Esta subconsulta em nosso caso retorna uma lista de valores chave da relação R2. E, como segue de nossa notação de operadores, da análise da condição de seleção, somente aquelas tuplas da relação R cairão na relação resultante1, cuja chave está contida na lista de chaves da relação R2. Ou seja, na relação final, se relembrarmos a definição da interseção de duas relações, apenas permanecerão as tuplas que pertencem a ambas as relações. 3. Operação de diferença. Como mencionado anteriormente, a operação unária da diferença de duas relações é implementada de forma semelhante à operação de interseção. Aqui, além da consulta principal com o operador Select, uma segunda consulta auxiliar é usada - a chamada subconsulta. Mas ao contrário da implementação da operação anterior, ao implementar a operação de diferença, é necessário usar outra palavra-chave, a saber não em, que em tradução literal significa "não em" ou (como é apropriado traduzir no nosso caso em consideração) - "não está contido em". Então, vamos, como no exemplo anterior, temos dois esquemas de relacionamento (R1 e R2), aproximadamente dado por: R1 (chave,...) e R2 (chave,...); Como você pode ver, os atributos-chave são novamente definidos entre os atributos dessas relações. Assim, obtemos a seguinte forma para representar a operação de diferença na linguagem de consulta estruturada: Selecione * De R1 Onde pista não em (Selecionar pista De R2); Assim, apenas aquelas tuplas da relação R1, cuja chave não está contida na lista de chaves da relação R2. Se considerarmos a notação literalmente, então realmente acontece que da relação R1 "subtraiu" a razão R2. A partir daqui concluímos que a condição de seleção neste operador está escrita corretamente (afinal, a definição da diferença de duas relações é realizada) e o uso de chaves, como no caso da implementação da operação de interseção, é totalmente justificado . Os dois usos do "método chave" que vimos são os mais comuns. Isso conclui o estudo do uso de chaves na construção de operadores que representam relações. Todas as operações binárias restantes da álgebra relacional são escritas de outras maneiras. 4. Operação do produto cartesiano Como lembramos das aulas anteriores, o produto cartesiano de dois operandos-relação é composto como um conjunto de todos os pares possíveis de valores nomeados de tuplas em atributos. Portanto, na linguagem de consulta estruturada, a operação do produto cartesiano é implementada usando uma junção cruzada, denotada pela palavra-chave junção cruzada, que se traduz literalmente como "junção cruzada" ou "junção cruzada". Existe apenas um operador Select na estrutura que representa a operação do produto cartesiano na linguagem de consulta estruturada e tem a seguinte forma: Selecione * De R1 junção cruzada R2 Aqui r1 e R2 - nomes dos operandos-relações iniciais. Opção junção cruzada garante que a relação resultante conterá todos os atributos (todos, pois a primeira linha do operador contém o sinal "*") correspondente a todos os pares de tuplas das relações R1 e R2. É muito importante lembrar uma característica da implementação da operação do produto cartesiano. Esta característica é consequência da definição da operação binária do produto cartesiano. Lembre-se: r4(S4) = r1(S1)xr2(S2) = {t(S1 ∪S2) | t[S1] ∈ r1 &t(S2) ∈ r2}, S1 ∩S2=∅; Como pode ser visto na definição acima, os pares de tuplas são formados com esquemas de relacionamento necessariamente sem interseção. Portanto, ao trabalhar na linguagem de consulta estruturada SQL, é invariavelmente estipulado que as relações de operandos iniciais não devem ter nomes de atributos correspondentes. Mas se essas relações ainda tiverem os mesmos nomes, a situação atual pode ser facilmente resolvida usando a operação de renomeação de atributos, ou seja, nesses casos, basta usar a opção as, que foi mencionado anteriormente. Vamos considerar um exemplo no qual precisamos encontrar o produto cartesiano de duas relações que têm alguns de seus nomes de atributos correspondentes. Então, dadas as seguintes relações: R1 (A,B), R2 (B,C); Vemos que os atributos R1.B e R2.B têm os mesmos nomes. Com isso em mente, a instrução Select que implementa essa operação de produto cartesiana na linguagem de consulta estruturada ficará assim: Selecionar A, R1.B as B1,R2.B as B2,C De R1 junção cruzada R2; Assim, utilizando a opção renomear como, a máquina não terá "dúvidas" sobre os nomes correspondentes das duas relações de operandos originais. 5. Operações de junção interna À primeira vista, pode parecer estranho considerarmos a operação de junção interna antes da operação de junção natural, pois quando passamos pelas operações binárias, tudo era o contrário. Mas analisando a expressão das operações na linguagem de consulta estruturada, pode-se chegar à conclusão de que a operação de junção natural é um caso especial da operação de junção interna. É por isso que é racional considerar essas operações apenas nessa ordem. Então, primeiro, vamos relembrar a definição da operação de junção interna pela qual passamos anteriormente: r1(S1)x P r2(S2) = σ (r1 xr2),S1 ∩ S2 =∅. Para nós, nesta definição, é especialmente importante que os esquemas de relações-operandos S considerados1 e S2 não deve se cruzar. Para implementar a operação de junção interna na linguagem de consulta estruturada, existe uma opção especial junção interna, que é traduzido literalmente do inglês como "inner join" ou "inner join". A instrução Select no caso de uma operação de junção interna ficará assim: Selecione * De R1 junção interna R2; Aqui, como antes, R1 e R2 - nomes dos operandos-relações iniciais. Ao implementar esta operação, os esquemas de operandos de relação não devem ser cruzados. 6. Operação de junção natural Como já dissemos, a operação de junção natural é um caso especial da operação de junção interna. Por quê? Sim, porque durante a ação de uma junção natural, as tuplas das relações dos operandos originais são unidas de acordo com uma condição especial. Ou seja, pela condição de igualdade de tuplas na interseção de operandos-relações, enquanto com a ação da operação de junção interna, tal situação não poderia ser permitida. Como a operação de junção natural que estamos considerando é um caso especial da operação de junção interna, a mesma opção é usada para implementá-la como para a operação considerada anteriormente, ou seja, a opção junção interna. Mas como, ao compilar o operador Select para a operação de junção natural, também é necessário levar em consideração a condição de igualdade das tuplas dos operandos-relações iniciais na interseção de seus esquemas, então, além da opção indicada, a palavra-chave é aplicada on. Traduzido do inglês, significa literalmente "on", e em relação ao nosso significado, pode ser traduzido como "sujeito a". A forma geral da instrução Select para realizar uma operação de junção natural é a seguinte: Selecione * De nome da relação 1 junção interna nome da relação 2 on condição de igualdade de tupla; Considere um exemplo. Sejam dadas duas relações: R1 (A,B,C), R2 (B, C, D); A operação de junção natural dessas relações pode ser implementada usando o seguinte operador: Selecionar A, R1.B,R1.CD De R1 junção interna R2 on R1.B=R2.B e R1.C=R2.C Como resultado desta operação, os atributos especificados na primeira linha do operador Select, correspondentes às tuplas iguais na interseção especificada, serão exibidos no resultado. Deve-se notar que aqui estamos nos referindo aos atributos comuns B e C, não apenas pelo nome. Isso deve ser feito não pelo mesmo motivo que no caso da implementação da operação cartesiana de produtos, mas porque, caso contrário, não ficará claro a qual relação eles se referem. Curiosamente, o texto usado da condição de junção (R1.B=R2.B e R1.C=R2.C) assume que os atributos compartilhados das relações de valor nulo unidas não são permitidos. Isso está embutido no sistema Structured Query Language desde o início. 7. Operação de junção externa esquerda A expressão da linguagem de consulta estruturada SQL da operação de junção externa esquerda é obtida da implementação da operação de junção natural substituindo a palavra-chave interior por palavra-chave exterior esquerdo. Assim, na linguagem de consultas estruturadas, essa operação será escrita da seguinte forma: Selecione * De nome da relação 1 junção externa esquerda nome da relação 2 on condição de igualdade de tupla; 8. Operação de junção externa direita A expressão para uma operação de junção externa direita na linguagem de consulta estruturada é obtida executando uma operação de junção natural substituindo a palavra-chave interior por palavra-chave direito externo. Assim, obtemos que na linguagem de consulta estruturada SQL, a operação da junção externa direita será escrita da seguinte forma: Selecione * De nome da relação 1 junção externa direita nome da relação 2 on condição de igualdade de tupla; 9. Operação de junção externa completa A expressão Structured Query Language para uma operação de junção externa completa é obtida, como nos dois casos anteriores, da expressão para uma operação de junção natural substituindo a palavra-chave interior por palavra-chave exterior completo. Assim, na linguagem de consultas estruturadas, esta operação será escrita da seguinte forma: Selecione * De nome da relação 1 junção externa completa nome da relação 2 on condição de igualdade de tupla; É muito conveniente que essas opções sejam incorporadas à semântica da linguagem de consulta estruturada SQL, porque, caso contrário, cada programador teria que produzi-las independentemente e inseri-las em cada novo banco de dados. 4. Usando subconsultas Como pode ser entendido a partir do material abordado, o conceito de "subconsulta" na linguagem de consulta estruturada é um conceito básico e bastante aplicável (às vezes, aliás, também são chamadas de consultas SQL. De fato, a prática de programação e trabalhar com banco de dados mostra que compilar um sistema de subconsultas para resolver várias tarefas relacionadas - uma atividade muito mais gratificante em comparação com alguns outros métodos de trabalhar com informações estruturadas. Portanto, vamos considerar um exemplo para entender melhor as ações com subconsultas, sua compilação E use. Seja o seguinte fragmento de um determinado banco de dados, que pode ser utilizado em qualquer instituição de ensino: Itens (Código do item, Nome do item); Alunos (número do livro de registro, Nome completo); Sessão (Código da disciplina, número do livro de notas, Avaliar); Vamos formular uma consulta SQL que retorna uma instrução indicando o número do livro de notas do aluno, o sobrenome e as iniciais e a nota da disciplina chamada "Bancos de dados". As universidades precisam receber essas informações sempre e em tempo hábil, portanto, a consulta a seguir talvez seja a unidade de programação mais popular usando esses bancos de dados. Por conveniência, vamos supor adicionalmente que os atributos "Last Name", "First Name" e "Patronymic" não permitem valores Null e não estão vazios. Esse requisito é bastante compreensível e lógico, pois os primeiros dados de um novo aluno inseridos no banco de dados de qualquer instituição de ensino são os dados sobre seu sobrenome, nome e patronímico. E nem é preciso dizer que não pode haver uma entrada em tal banco de dados que contenha dados sobre um aluno, mas ao mesmo tempo seu nome é desconhecido. Observe que o atributo "Nome do item" do esquema de relacionamento "Itens" é uma chave, portanto, conforme segue a definição (mais sobre isso posteriormente), todos os nomes de itens são exclusivos. Isso também é compreensível sem explicar a representação da chave, porque todas as disciplinas ensinadas em uma instituição de ensino devem ter e ter nomes diferentes. Agora, antes de começarmos a compilar o texto do próprio operador, apresentaremos duas funções que nos serão úteis à medida que prosseguirmos. Primeiro vamos precisar da função aparar, é escrito Trim ("string"), ou seja, o argumento para esta função é uma string. O que essa função faz? Eles retornam o próprio argumento sem espaços no início e no final desta linha, ou seja, esta função é utilizada, por exemplo, nos casos: Trim ("Bogucharnikov") ou Trim ("Maksimenko"), quando argumentos após ou antes são vale alguns espaços extras. E em segundo lugar, também é necessário considerar a função Esquerda, que se escreve Esquerda (string, número), ou seja, uma função de já dois argumentos, um dos quais é, como antes, uma string. Seu segundo argumento é um número, ele indica quantos caracteres do lado esquerdo da string devem ser exibidos no resultado. Por exemplo, o resultado da operação: Esquerda ("Mikhail, 1") + "." + Esquerda ("Zinovievich, 1") serão as iniciais "M.Z." É para exibir as iniciais dos alunos que usaremos essa função em nossa consulta. Então, vamos começar a compilar a consulta desejada. Primeiro, vamos fazer uma pequena consulta auxiliar, que usamos na consulta principal, principal: Selecionar Número do boletim de notas, Grau De Sessão Onde Código do item = (Selecionar Código do item De objetos Onde Nome do item = "Bancos de dados") as "Estimativas" Bases de Dados "; Usar a opção as aqui significa que apelidamos essa consulta de "Estimativas de banco de dados". Fizemos isso para facilitar o trabalho adicional com essa solicitação. Em seguida, nesta consulta, uma subconsulta: Selecionar Código do item De objetos Onde Nome do item = "Bancos de dados"; permite selecionar na relação "Sessão" aquelas tuplas que se relacionam com o assunto em consideração, ou seja, bancos de dados. Curiosamente, essa subconsulta interna só pode retornar um valor, pois o atributo "Nome do item" é a chave do relacionamento "Itens", ou seja, todos os seus valores são únicos. E toda a consulta "Pontuações "Banco de dados" permite selecionar na relação "Sessão" dados sobre os alunos (seus números e notas do boletim de notas) que atendem à condição especificada na subconsulta, ou seja, informações sobre o assunto chamado "Banco de dados". Agora faremos a requisição principal, utilizando os resultados já recebidos. Selecionar Alunos. número do livro de registro, aparar (Sobrenome) + " " + Esquerdo (Nome, 1) + "." + Esquerdo (Patronímico, 1) + "."as Nome completo, Estimativas "Bancos de dados". Avaliar De Alunos junção interna ( Selecionar Número do boletim de notas, Grau De Sessão Onde Código do item = (Selecionar Código do item De objetos Onde Nome do item = "Bancos de dados") ) Como "Estimativas" Bases de Dados ". on Alunos. Boletim # = Notas do "Banco de dados". Número do livro de registro. Então, primeiro listamos os atributos que precisarão ser exibidos após a conclusão da consulta. Deve-se mencionar que o atributo "Número da Caderneta" é da relação Alunos, daí - os atributos "Sobrenome", "Nome" e "Patronímico". É verdade que os dois últimos atributos não são totalmente deduzidos, mas apenas as primeiras letras. Também mencionamos o atributo 'Score' da consulta 'Database Score' que inserimos anteriormente. Selecionamos todos esses atributos da junção interna da relação "Alunos" e da consulta "Notas do banco de dados". Essa junção interna, como podemos ver, é feita por nós sob a condição de igualdade dos números do livro de registro. Como resultado dessa operação de junção interna, as notas são adicionadas à relação Alunos. Deve-se notar que, como os atributos "Sobrenome", "Nome" e "Patronímico" por condição não permitem valores nulos e não são vazios, a fórmula de cálculo que retorna o atributo "Nome" (aparar (Sobrenome) + " " + Esquerdo (Nome, 1) + "." + Esquerdo (Patronímico, 1) + "."as Nome completo), respectivamente, não requer verificações adicionais, é simplificado. << Voltar: Álgebra relacional. Operações binárias (Operações de união, intersecção, diferença. Operações de produto cartesiano e junção natural. Propriedades das operações binárias. Variantes de operações de junção. Operações derivadas. Expressões de álgebra relacional) >> Encaminhar: Relacionamentos Básicos (Tipos de dados básicos. Tipo de dados personalizados. Valores padrão. Atributos virtuais. Conceito de chaves)
▪ Estatísticas médicas. Notas de aula ▪ Psicologia do trabalho. Berço ▪ Terapia Hospitalar. Notas de aula
A existência de uma regra de entropia para o emaranhamento quântico foi comprovada
09.05.2024 Mini ar condicionado Sony Reon Pocket 5
09.05.2024 Energia do espaço para Starship
08.05.2024
▪ Sistema de fotossíntese artificial ▪ Defesa aérea a laser Skyranger 30 HEL ▪ RDIMMs VLP DDR4 de 64 GB Virtium ▪ Imunidade das mulheres grávidas reage ao sexo da criança
▪ seção do site Plantas cultivadas e silvestres. Seleção de artigos ▪ artigo de Jean de La Bruyère. Aforismos famosos ▪ artigo Quem são os irmãos Vasiliev? Resposta detalhada ▪ Artigo Zira. Lendas, cultivo, métodos de aplicação ▪ artigo Lubrificação de arneses e arneses. receitas simples e dicas
Página principal | Biblioteca | Artigos | Mapa do Site | Revisões do site
www.diagrama.com.ua |


 Veja outros artigos seção
Veja outros artigos seção 