|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese|
RESUMO DA AULA, CRIBS
Informática e tecnologias da informação. Folha de dicas: resumidamente, o mais importante
Diretório / Notas de aula, folhas de dicas Índice analítico
1. Informática. Em formação Representação e processamento/informação. Sistemas numéricos A informática está engajada em uma representação formalizada de objetos e estruturas de seus relacionamentos em vários campos da ciência, tecnologia e produção. Várias ferramentas formais são usadas para modelar objetos e fenômenos, como fórmulas lógicas, estruturas de dados, linguagens de programação, etc. Na ciência da computação, um conceito tão fundamental como a informação tem vários significados: 1) apresentação formal de formas externas de informação; 2) significado abstrato da informação, seu conteúdo interno, semântica; 3) relação da informação com o mundo real. Mas, via de regra, a informação é entendida como seu significado abstrato - semântica. Se queremos trocar informações, precisamos de visões consistentes para que a correção da interpretação não seja violada. Para isso, a interpretação da representação da informação é identificada com algumas estruturas matemáticas. Nesse caso, o processamento da informação pode ser realizado por métodos matemáticos rigorosos. Uma das descrições matemáticas da informação é sua representação como uma função y = f(x,t) onde t é o tempo, x é um ponto em algum campo onde o valor de y é medido. Dependendo dos parâmetros da função x e t, as informações podem ser classificadas. Se os parâmetros são grandezas escalares que assumem uma série contínua de valores, então a informação obtida desta forma é chamada de contínua (ou analógica). Se os parâmetros recebem uma determinada etapa de alteração, a informação é chamada de discreta. A informação discreta é considerada universal. Informação discreta é normalmente identificada com informação digital, que é um caso especial de informação simbólica de representação alfabética. Um alfabeto é um conjunto finito de símbolos de qualquer natureza. Muitas vezes na ciência da computação surge uma situação em que os caracteres de um alfabeto devem ser representados pelos caracteres de outro, ou seja, uma operação de codificação deve ser realizada. Como a prática mostrou, o alfabeto mais simples que permite codificar outros alfabetos é o binário, consistindo em dois caracteres, que geralmente são denotados por 0 e 1. Usando n caracteres do alfabeto binário, você pode codificar 2n caracteres, e isso é suficiente para codificar qualquer alfabeto. O valor que pode ser representado por um símbolo do alfabeto binário é chamado de unidade mínima de informação ou bit. Sequência de 8 bits - bytes. Um alfabeto contendo 256 sequências de 8 bits diferentes é chamado de alfabeto de bytes. Um sistema numérico é um conjunto de regras para nomear e escrever números. Existem sistemas numéricos posicionais e não posicionais. O sistema numérico é chamado posicional se o valor do dígito do número depende da localização do dígito no número. Caso contrário, é chamado de não posicional. O valor de um número é determinado pela posição desses dígitos no número. 2. Representação de números em computador. Conceito formalizado de um algoritmo Processadores de 32 bits podem trabalhar com até 232-1 RAM e endereços podem ser escritos no intervalo 00000000 - FFFFFFFF. No entanto, em modo real, o processador opera com memória até 220-1, e os endereços ficam na faixa 00000 - FFFFF. Bytes de memória podem ser combinados em campos de comprimento fixo e variável. Uma palavra é um campo de comprimento fixo que consiste em 2 bytes, uma palavra dupla é um campo de 4 bytes. Os endereços de campo podem ser pares ou ímpares, com endereços pares realizando operações mais rapidamente. Os números de ponto fixo são representados em computadores como números binários inteiros e seu tamanho pode ser de 1, 2 ou 4 bytes. Números binários inteiros são representados em complemento de dois. O código adicional de um número positivo é igual ao próprio número, e o código adicional de um número negativo pode ser obtido usando a seguinte fórmula: x = 10n - \x\, onde n é a profundidade de bits do número. No sistema de numeração binário, um código adicional é obtido invertendo bits, ou seja, substituindo unidades por zeros e vice-versa, e adicionando um ao bit menos significativo. O número de bits da mantissa determina a precisão da representação dos números, o número de bits da ordem de máquina determina o intervalo de representação dos números de ponto flutuante. Conceito formalizado de um algoritmo Um algoritmo só pode existir se, ao mesmo tempo, existir algum objeto matemático. O conceito formalizado de algoritmo está ligado ao conceito de funções recursivas, algoritmos normais de Markov, máquinas de Turing. Em matemática, uma função é chamada de valor único se, para qualquer conjunto de argumentos, existe uma lei pela qual um valor único da função é determinado. Um algoritmo pode atuar como tal lei; neste caso diz-se que a função é computável. Funções recursivas são uma subclasse de funções computáveis, e os algoritmos que definem a computação são chamados de algoritmos de funções recursivas complementares. Primeiro, as funções recursivas básicas são fixas, para as quais o algoritmo que as acompanha é trivial, não ambíguo; em seguida, três regras são introduzidas - operadores de substituição, recursão e minimização, com a ajuda dos quais funções recursivas mais complexas são obtidas com base em funções básicas. As funções básicas e seus algoritmos de acompanhamento podem ser: 1) uma função de n variáveis independentes, identicamente igual a zero. Então, se o sinal da função for φn, independentemente do número de argumentos, o valor da função deve ser igual a zero; 2) a função identidade de n variáveis independentes da forma Ψ ni. Então, se o sinal da função for Ψ ni, então o valor da função deve ser tomado como o valor do i-ésimo argumento, contando da esquerda para a direita; 3) Função λ de um argumento independente. Então, se o sinal da função for λ, então o valor da função deve ser tomado como o valor que segue o valor do argumento. 3. Introdução à linguagem Pascal Os símbolos básicos do idioma - letras, números e caracteres especiais - compõem seu alfabeto. A linguagem Pascal inclui o seguinte conjunto de símbolos básicos: 1) 26 letras minúsculas latinas e 26 letras maiúsculas latinas: 2) _ (sublinhado); 3) 10 dígitos: 0 1 2 3 4 5 6 7 8 9; 4) sinais de operação: + - O / = <> < > <= >= := @; 5) delimitadores:., ( ) [ ] (..) { } (* *).. : ; 6) especificadores: ^ # $; 7) palavras de serviço (reservadas): ABSOLUTO, ASSEMBLER, AND, ARRAY, ASM, BEGIN, CASE, CONST, CONSTRUCTOR, DESTRUCTOR, DIV, DO, DOWNTO, ELSE, END, EXPORT, EXTERNAL, FAR, FILE, FOR, FORWARD, FUNÇÃO, IR, SE, IMPLEMENTAÇÃO, EM, ÍNDICE, HERDADO, INLINE, INTERFACE, INTERROMPER, ETIQUETA, BIBLIOTECA, MOD, NOME, NIL, PERTO, NÃO, OBJETO, DE, OU, EMBALADO, PRIVADO, PROCEDIMENTO, PROGRAMAR, PÚBLICO, GRAVAR, REPETIR, RESIDENTE, DEFINIR, SHL, SHR, STRING, THEN, TO, TYPE, UNIT, ATÉ, USOS, VAR, VIRTUAL, ENQUANTO, COM, XOR. Além dos listados, o conjunto de caracteres básicos inclui um espaço. Existe uma regra em Pascal: o tipo é especificado explicitamente na declaração de uma variável ou função que antecede seu uso. O conceito de tipo Pascal tem as seguintes propriedades principais: 1) qualquer tipo de dado define um conjunto de valores ao qual pertence uma constante, que uma variável ou expressão pode assumir, ou uma operação ou função pode produzir; 2) o tipo de valor dado por uma constante, variável ou expressão pode ser determinado por sua forma ou descrição; 3) cada operação ou função requer argumentos de tipo fixo e produz um resultado de tipo fixo. Existem tipos de dados escalares e estruturados em Pascal. Os tipos escalares incluem tipos padrão e tipos definidos pelo usuário. Os tipos padrão incluem tipos inteiro, real, caractere, booleano e endereço. Os tipos inteiros definem constantes, variáveis e funções cujos valores são realizados pelo conjunto de inteiros permitidos em um determinado computador. Pascal tem a seguinte precedência de operador:
1) cálculos entre parênteses; 2) cálculo dos valores das funções; 3) operações unárias; 4) operações */div mod e; 5) operações + - ou xor; 6) operações de relação = <> < > <= >=. 4. Procedimentos e funções padrão Funções aritméticas 1.Função Abs(X); retorna o valor absoluto do parâmetro. 2. Função ArcTan(X: Estendido): Estendido; retorna o arco tangente do argumento. 3. Função Exp(X: Real): Real; retorna o expoente. 4.Frac(X: Real): Real; retorna a parte fracionária do argumento. 5. Função Int(X: Real): Real; retorna a parte inteira do argumento. 6. Função Ln(X: Real): Real; retorna o logaritmo natural (Ln e = 1) de uma expressão de tipo real x. 7.Função Pi: Estendido; retorna o valor Pi, que é definido como 3.1415926535. 8.Função Sin(X: Estendido): Estendido; retorna o seno do argumento. 9.Função Sqr(X: Estendido): Estendido; retorna o quadrado do argumento. 10.Função Sqrt(X: Estendido): Estendido; retorna a raiz quadrada do argumento. Procedimentos e funções de conversão de valor 1. Procedimento Str(X [: Largura [: Decimais]]; var S); converte o número X em uma representação de string. 2. Função Chr(X: Byte): Char; retorna o caractere com número de índice x na tabela ASCII. 3.Função Alta(X); retorna o maior valor no intervalo do parâmetro. 4.FunçãoBaixa(X); retorna o menor valor no intervalo do parâmetro. 5. FunctionOrd(X): LongInt; retorna o valor ordinal de uma expressão de tipo enumerado. 6. Função Round(X: Extended): LongInt; arredonda um valor real para um inteiro. 7. Função Trunc(X: Estendido): LongInt; trunca um valor de tipo real para um inteiro. 8. Procedimento Val(S; var V; var Código: Inteiro); converte um número de um valor de string S para uma representação numérica V. Procedimentos e funções para trabalhar com valores ordinais 1. Procedimento Dec(var X [; N: LongInt]); subtrai um ou N da variável X. 2. Procedimento Inc(var X [; N: LongInt]); adiciona um ou N à variável X. 3. Função Ímpar(X: LongInt): Booleano; retorna True se X for um número ímpar, False caso contrário. 4.FunçãoPred(X); retorna o valor anterior do parâmetro. 5 Função Succ(X); retorna o próximo valor do parâmetro. 5. Operadores da linguagem Pascal Operador condicional O formato da instrução condicional completa é definido da seguinte forma: Se B então S1 senão S2 onde B é uma condição de ramificação (tomada de decisão), uma expressão lógica ou uma relação; S1, S2 - uma instrução executável, simples ou composta. Ao executar uma instrução condicional, primeiro a expressão B é avaliada, depois seu resultado é analisado: se B for verdadeiro, então a instrução S1 é executada - a ramificação de then, e a instrução S2 é ignorada; se B for falso, então a instrução S2 - a ramificação else é executada e a instrução S1 é ignorada. Selecionar declaração A estrutura do operador é a seguinte: caso S de c1: instrução1; c2: instrução2; ... cn: instruçãoN; outra instrução end; onde S é uma expressão de tipo ordinal cujo valor está sendo calculado; c1, c2,..., on - constantes do tipo ordinal com as quais as expressões S são comparadas; instruçãol,..., instruçãoN - operadores dos quais é executado aquele cuja constante corresponde ao valor da expressão S; instrução - um operador que é executado se o valor da expressão S não corresponder a nenhuma das constantes c1, o2, on. Instrução de loop com parâmetro Quando a instrução for começa a ser executada, os valores inicial e final são determinados uma vez, e esses valores são retidos durante toda a execução da instrução for. A instrução contida no corpo da instrução for é executada uma vez para cada valor no intervalo entre os valores inicial e final. O contador de loops é sempre inicializado com um valor inicial. Instrução de loop com pré-condição Enquanto B faz S; onde B é uma condição lógica, cuja veracidade é verificada (é uma condição para encerrar o loop)$; S - corpo do loop - uma instrução. A expressão que controla a repetição de uma instrução deve ser do tipo Boolean. Ele é avaliado antes que a instrução interna seja executada. A instrução interna é executada repetidamente enquanto a expressão for avaliada como Trie. Se a expressão for avaliada como False desde o início, a instrução contida na instrução do loop de pré-condição não será executada. Instrução de loop com pós-condição repita S até B; onde B é uma condição lógica, cuja veracidade é verificada (é uma condição para encerrar o loop); S - uma ou mais instruções do corpo do loop. O resultado da expressão deve ser do tipo booleano. As instruções entre as palavras-chave repeat e until são executadas sequencialmente até que o resultado da expressão seja avaliado como True. A sequência de instruções será executada pelo menos uma vez porque a expressão é avaliada após cada execução da sequência de instruções. 6. O conceito de um algoritmo auxiliar O algoritmo de resolução de problemas é projetado decompondo todo o problema em subtarefas separadas. Normalmente, as subtarefas são implementadas como sub-rotinas. Uma sub-rotina é algum algoritmo auxiliar que é usado repetidamente no algoritmo principal com valores diferentes de algumas grandezas de entrada, chamadas de parâmetros. Uma sub-rotina em linguagens de programação é uma sequência de instruções que são definidas e escritas em apenas um local do programa, mas podem ser chamadas para execução a partir de um ou mais pontos do programa. Cada sub-rotina é identificada por um nome único. Existem dois tipos de sub-rotinas em Pascal, procedimentos e funções. Um procedimento e uma função são uma sequência nomeada de declarações e instruções. Ao usar procedimentos ou funções, o programa deve conter o texto do procedimento ou função e a chamada para o procedimento ou função. Os parâmetros especificados na descrição são chamados de formais, os especificados na chamada da sub-rotina são chamados de reais. Todos os parâmetros formais podem ser divididos nas seguintes categorias: 1) variáveis-parâmetros; 2) parâmetros constantes; 3) valores de parâmetros; 4) parâmetros de procedimento e parâmetros de função, ou seja, parâmetros de tipo de procedimento; 5) parâmetros de variáveis não tipadas. Os textos de procedimentos e funções são colocados nas descrições de procedimentos e funções. Passando nomes de procedimentos e funções como parâmetros Em muitos problemas, especialmente em matemática computacional, é necessário passar os nomes de procedimentos e funções como parâmetros. Para isso, o TURBO PASCAL introduziu um novo tipo de dado - procedimental ou funcional, dependendo do que for descrito. (Os tipos de procedimento e função são descritos na seção de declaração de tipo.) Uma função e um tipo de procedimento são definidos como o cabeçalho de um procedimento e uma função com uma lista de parâmetros formais, mas sem nome. É possível definir uma função ou tipo procedural sem parâmetros, por exemplo: tipo Proc = procedimento; Depois de declarar um tipo procedural ou funcional, ele pode ser usado para descrever parâmetros formais - os nomes de procedimentos e funções. Além disso, é necessário escrever aqueles procedimentos ou funções reais cujos nomes serão passados como parâmetros reais. 7. Procedimentos e funções em Pascal Procedimentos em Pascal A descrição do procedimento consiste em um cabeçalho e um bloco, que, com exceção da seção de conexão do módulo, não diferem do bloco de programa. O cabeçalho consiste na palavra-chave Procedure, no nome do procedimento e em uma lista opcional de parâmetros formais entre parênteses: Procedimento <nome> [(<lista de parâmetros formais>)]; Para cada parâmetro formal, seu tipo deve ser definido. Os grupos de parâmetros em uma descrição de procedimento são separados por ponto e vírgula. A estrutura do procedimento é quase completamente semelhante ao programa. No entanto, não há seção de conexão do módulo no bloco de procedimento. O bloco é composto por duas partes: descritiva e executiva. A parte descritiva contém uma descrição dos elementos do procedimento. E na parte executiva, as ações são indicadas com os elementos de programa disponíveis para o procedimento (por exemplo, variáveis globais e constantes), que permitem obter o resultado desejado. A seção de instruções de um procedimento difere da seção de instruções de um programa apenas porque a palavra-chave End que termina a seção é seguida por um ponto e vírgula em vez de um ponto. Uma instrução de chamada de procedimento é usada para chamar um procedimento. Ele consiste no nome do procedimento e uma lista de argumentos entre parênteses. As instruções a serem executadas quando o procedimento é executado estão contidas na parte de instruções do módulo de procedimento. Às vezes você quer que um procedimento chame a si mesmo. Essa maneira de chamar é chamada de recursão. A recursão é útil nos casos em que a tarefa principal pode ser dividida em subtarefas, cada uma delas implementada de acordo com um algoritmo que coincide com o principal. Funções em Pascal Uma declaração de função define a parte do programa na qual o valor é calculado e retornado. Uma descrição de função consiste em um cabeçalho e um bloco. O cabeçalho contém a palavra-chave Function, o nome da função, uma lista opcional de parâmetros formais entre parênteses e o tipo de retorno da função. A forma geral do cabeçalho da função é a seguinte: Função <nome> [(<lista de parâmetros formais>)]: <tipo de retorno>; Na implementação Borland do Turbo Pascal 7.0, o valor de retorno de uma função não pode ser do tipo composto. E a linguagem Object Pascal utilizada nos ambientes de desenvolvimento integrado Borland Delphi permite qualquer tipo de resultado de retorno, exceto o tipo de arquivo. Um bloco de função é um bloco local, semelhante em estrutura a um bloco de procedimento. O corpo de uma função deve conter pelo menos uma instrução de atribuição, no lado esquerdo da qual está o nome da função. É ela quem determina o valor retornado pela função. Se houver várias dessas instruções, o resultado da função será o valor da última instrução de atribuição executada. A função é ativada quando a função é chamada. Quando uma função é chamada, o identificador da função e quaisquer parâmetros necessários para avaliar a função são especificados. Uma chamada de função pode ser incluída em expressões como um operando. Quando a expressão é avaliada, a função é executada e o valor do operando passa a ser o valor retornado pela função. A parte do operador do bloco funcional especifica as instruções que devem ser executadas quando a função é ativada. Um módulo deve conter pelo menos uma instrução de atribuição que atribua um valor a um identificador de função. O resultado da função é o último valor atribuído. Se não houver tal instrução de atribuição ou se ela não tiver sido executada, o valor de retorno da função será indefinido. Se um identificador de função for usado ao chamar uma função dentro de um módulo - uma função, a função será executada recursivamente. 8. Encaminhar descrições e conexão de sub-rotinas. Diretiva Um programa pode conter várias sub-rotinas, ou seja, a estrutura do programa pode ser complicada. No entanto, essas sub-rotinas podem estar no mesmo nível de aninhamento, portanto, a declaração da sub-rotina deve vir primeiro e depois a chamada a ela, a menos que uma declaração especial de encaminhamento seja usada. Uma declaração de procedimento que contém uma diretiva de encaminhamento em vez de um bloco de instrução é chamada de declaração de encaminhamento. Em algum lugar após esta declaração, um procedimento deve ser definido por uma declaração de definição. Uma declaração de definição é aquela que usa o mesmo identificador de procedimento, mas omite a lista de parâmetros formais e inclui um bloco de instruções. A declaração de encaminhamento e a declaração de definição devem aparecer na mesma parte das declarações de procedimento e função. Entre eles, podem ser declarados outros procedimentos e funções que podem se referir ao procedimento de declaração de encaminhamento. Assim, a recursão mútua é possível. A descrição direta e a descrição de definição são a descrição completa do procedimento. O procedimento é considerado descrito usando a descrição direta. Se o programa contiver muitas sub-rotinas, o programa deixará de ser visual, será difícil navegar nele. Para evitar isso, algumas rotinas são armazenadas como arquivos fonte em disco e, se necessário, são conectadas ao programa principal na fase de compilação usando uma diretiva de compilação. Uma diretiva é um comentário especial que pode ser colocado em qualquer lugar em um programa, onde um comentário normal pode estar. No entanto, eles diferem porque a diretiva tem uma notação especial: imediatamente após o colchete de fechamento, sem espaço, o sinal $ é escrito e, novamente, sem espaço, a diretiva é indicada. Exemplo: 1) {$E+} - emular coprocessador matemático; 2) {$F+} - forma o tipo distante de procedimentos e funções de chamada; 3) {$N+} - usa coprocessador matemático; 4) {$R+} - verifique se os intervalos estão fora dos limites. Algumas opções de compilação podem conter um parâmetro, por exemplo: {$I file name} - inclui o arquivo nomeado no texto do programa compilado 9. Parâmetros do subprograma A descrição de um procedimento ou função especifica uma lista de parâmetros formais. Cada parâmetro declarado em uma lista de parâmetros formal é local para o procedimento ou função que está sendo descrito e pode ser referido no módulo associado a esse procedimento ou função por seu identificador. Existem três tipos de parâmetros: valor, variável e variável sem tipo. Eles são caracterizados da seguinte forma: 1. Um grupo de parâmetros sem uma palavra-chave precedente é uma lista de parâmetros de valor. 2. Um grupo de parâmetros precedido pela palavra-chave const e seguido por um tipo é uma lista de parâmetros constantes. 3. Um grupo de parâmetros precedido pela palavra-chave var e seguido por um tipo é uma lista de parâmetros de variáveis. Parâmetros de valor Um parâmetro de valor formal é tratado como uma variável local para o procedimento ou função, exceto que obtém seu valor inicial do parâmetro real correspondente quando o procedimento ou função é invocado. As alterações sofridas por um parâmetro de valor formal não afetam o valor do parâmetro real. O valor real correspondente do parâmetro value deve ser uma expressão e seu valor não deve ser um tipo de arquivo ou qualquer tipo de estrutura que contenha um tipo de arquivo. O parâmetro real deve ser de um tipo que seja compatível com a atribuição do tipo do parâmetro de valor formal. Se o parâmetro for do tipo string, o parâmetro formal terá um atributo size de 255. Parâmetros constantes No corpo de uma sub-rotina, o valor de um parâmetro constante não pode ser alterado. As constantes de parâmetros podem ser usadas para organizar aqueles parâmetros cujas mudanças na sub-rotina são indesejáveis e devem ser proibidas. Parâmetros variáveis Um parâmetro variável é usado quando um valor deve ser passado de uma sub-rotina para um bloco de chamada. Neste caso, quando a sub-rotina é chamada, o parâmetro formal é substituído pelo argumento variável e quaisquer alterações no parâmetro formal são refletidas no argumento. Variáveis de procedimento Após definir um tipo procedural, torna-se possível descrever variáveis desse tipo. Tais variáveis são chamadas de variáveis procedurais. Como uma variável inteira que pode receber um valor de um tipo inteiro, uma variável procedural pode receber um valor de um tipo procedural. Tal valor poderia, é claro, ser outra variável de procedimento, mas também poderia ser um identificador de procedimento ou função. Nesse contexto, a declaração de um procedimento ou função pode ser vista como uma descrição de um tipo especial de constante cujo valor é o procedimento ou função. Como em qualquer outra atribuição, os valores da variável do lado esquerdo e do lado direito devem ser compatíveis com a atribuição. Os tipos de procedimento, para serem compatíveis com atribuição, devem ter o mesmo número de parâmetros, e os parâmetros nas posições correspondentes devem ser do mesmo tipo. Os nomes de parâmetros em uma declaração de tipo procedural não têm efeito. Além disso, para garantir a compatibilidade de atribuição, um procedimento ou função, se for atribuído a uma variável de procedimento, não deve ser padrão ou aninhado. 10. Tipos de parâmetros de sub-rotina Parâmetros de valor Um parâmetro de valor formal é tratado como uma variável local; ele obtém seu valor inicial do parâmetro real correspondente quando o procedimento ou função é invocado. As alterações sofridas por um parâmetro de valor formal não afetam o valor do parâmetro real. O valor real correspondente do parâmetro value deve ser uma expressão e seu valor não deve ser de um tipo de arquivo. Parâmetros constantes Parâmetros constantes formais obtêm seu valor quando um procedimento ou função é invocado. Atribuições a um parâmetro constante formal não são permitidas. Um parâmetro constante formal não pode ser passado como um parâmetro real para outro procedimento ou função. Parâmetros variáveis Um parâmetro variável é usado quando um valor deve ser passado de um procedimento ou função para o programa de chamada. Quando ativado, a variável de parâmetro formal é substituída pela variável real, as alterações na variável de parâmetro formal são refletidas no parâmetro real. Parâmetros não digitados Quando o parâmetro formal é um parâmetro variável sem tipo, o parâmetro real correspondente pode ser uma referência variável ou constante. Um parâmetro sem tipo declarado com a palavra-chave var pode ser modificado, enquanto um parâmetro sem tipo declarado com a palavra-chave const é somente leitura. Variáveis de procedimento Após definir um tipo procedural, torna-se possível descrever variáveis desse tipo. Tais variáveis são chamadas de variáveis procedurais. Uma variável procedural pode receber um valor de um tipo procedural. O procedimento ou função em atribuição deve ser: 1) não padrão; 2) não aninhado; 3) não é um procedimento do tipo inline; 4) não pelo procedimento de interrupção. Parâmetros de tipo de procedimento Como os tipos procedurais podem ser usados em qualquer contexto, é possível descrever procedimentos ou funções que recebem procedimentos e funções como parâmetros. Os parâmetros de tipo de procedimento são especialmente úteis quando você precisa executar ações comuns em vários procedimentos ou funções. Se um procedimento ou função deve ser passado como parâmetro, ele deve seguir as mesmas regras de compatibilidade de tipo que a atribuição. Ou seja, tais procedimentos ou funções devem ser compilados com a diretiva far, não podem ser funções internas, não podem ser aninhadas e não podem ser descritas com os atributos inline ou interrupt. 11. Tipo de string em Pascal. Procedimentos e funções para variáveis do tipo string Uma sequência de caracteres de um determinado comprimento é chamada de string. As variáveis do tipo string são definidas especificando o nome da variável, a string de palavra reservada e, opcionalmente, mas não necessariamente, especificando o tamanho máximo, ou seja, o comprimento da string, entre colchetes. Se você não definir o tamanho máximo da string, por padrão será 255, ou seja, a string consistirá em 255 caracteres. Cada elemento de uma string pode ser referido pelo seu número. No entanto, strings são entradas e saídas como um todo, não elemento por elemento, como é o caso dos arrays. O número de caracteres inseridos não deve exceder o especificado no tamanho máximo da string, portanto, se ocorrer esse excesso, os caracteres "extras" serão ignorados. Procedimentos e funções para variáveis do tipo string 1. Cópia da Função(S: String; Índice, Contagem: Inteiro): String; Retorna uma substring de uma string. S é uma expressão do tipo String. Index e Count são expressões do tipo inteiro. A função retorna uma string contendo caracteres Count começando na posição Index. Se Index for maior que o comprimento de S, a função retornará uma string vazia. 2. Procedimento Delete(var S: String; Index, Count: Integer); Remove uma substring de caracteres de comprimento Count da string S, começando na posição Index. S é uma variável do tipo String. Index e Count são expressões do tipo inteiro. Se Index for maior que o comprimento de S, nenhum caractere será removido. 3. Inserção de Procedimento(Fonte: String; var S: String; Índice: Inteiro); Concatena uma substring em uma string, começando em uma posição especificada. Source é uma expressão do tipo String. S é uma variável do tipo String de qualquer comprimento. Índice é uma expressão do tipo inteiro. Insert insere Source em S, começando na posição S. 4. Comprimento da Função (S: String): Inteiro; Retorna o número de caracteres realmente usados na string S. Observe que, ao usar strings terminadas em nulo, o número de caracteres não é necessariamente igual ao número de bytes. 5. Função Pos(Substr: String; S: String): Integer; Procura uma substring em uma string. Pos procura por Substr dentro de S e retorna um valor inteiro que é o índice do primeiro caractere de Substr dentro de S. Se Substr não for encontrado, Pos retornará zero. 12. Gravações Um registro é uma coleção de um número limitado de componentes logicamente relacionados pertencentes a diferentes tipos. Os componentes de um registro são chamados de campos, cada um dos quais é identificado por um nome. Um campo de registro contém o nome do campo, seguido por dois pontos para indicar o tipo do campo. Os campos de registro podem ser de qualquer tipo permitido em Pascal, com exceção do tipo de arquivo. A descrição de um registro na linguagem Pascal é realizada utilizando a palavra de serviço RECORD, seguida da descrição dos componentes do registro. A descrição da entrada termina com a palavra de serviço END. Por exemplo, um bloco de anotações contém sobrenomes, iniciais e números de telefone, portanto, é conveniente representar uma linha separada em um bloco de anotações como a seguinte entrada: tipo Linha = Registro FIO: Sequência[20]; TEL: Sequência[7]; end; var str: Linha; As descrições de registro também são possíveis sem usar o nome do tipo, por exemplo: var str: Gravar FIO: Sequência[20]; TEL: Sequência[7]; end; A referência a um registro como um todo é permitida apenas em instruções de atribuição em que os nomes de registro do mesmo tipo são usados à esquerda e à direita do sinal de atribuição. Em todos os outros casos, campos separados de registros são operados. Para fazer referência a um componente de registro individual, você deve especificar o nome do registro e, por meio de um ponto, especificar o nome do campo desejado. Tal nome é chamado de nome composto. Um componente de registro também pode ser um registro; nesse caso, o nome distinto conterá não dois, mas mais nomes. A referência de componentes de registro pode ser simplificada usando o operador with append. Ele permite substituir os nomes compostos que caracterizam cada campo por apenas nomes de campo e definir o nome do registro no operador de acréscimo. Às vezes, o conteúdo de um registro individual depende do valor de um de seus campos. Na linguagem Pascal, é permitida uma descrição de registro, consistindo em partes comuns e variantes. A parte variante é especificada usando o caso P de construção, onde P é o nome do campo da parte comum do registro. Os valores possíveis aceitos por este campo são listados da mesma forma que na declaração de variantes. No entanto, em vez de especificar a ação a ser executada, como é feito em uma instrução variante, os campos variantes são especificados entre parênteses. A descrição da parte variante termina com o fim da palavra de serviço. O tipo de campo P pode ser especificado no cabeçalho da parte variante. Os registros são inicializados usando constantes tipadas. 13. Conjuntos O conceito de conjunto na linguagem Pascal é baseado no conceito matemático de conjuntos: é uma coleção limitada de diferentes elementos. Um tipo de dados enumerado ou de intervalo é usado para construir um tipo de conjunto concreto. O tipo de elementos que compõem um conjunto é chamado de tipo base. Um tipo múltiplo é descrito usando o conjunto de palavras de função, por exemplo: tipo M = Conjunto de B; onde M é o tipo plural, B é o tipo base. O pertencimento de variáveis a um tipo plural pode ser determinado diretamente na seção de declaração de variáveis. As constantes do tipo set são escritas como uma sequência entre colchetes de elementos ou intervalos do tipo base, separados por vírgulas. As operações de atribuição (:=), união (+), interseção (*) e subtração (-) são aplicáveis a variáveis e constantes de um tipo de conjunto. O resultado dessas operações é um valor do tipo plural: 1) ['A','B'] + ['A','D'] dará ['A','B','D']; 2) ['A'] * ['A','B','C'] dará ['A']; 3) ['A','B','C'] - ['A','B'] dará ['C'] As operações são aplicáveis a vários valores: identidade (=), não identidade (<>), contido em (<=), contém (>=). O resultado dessas operações tem um tipo booleano: 1) ['A','B'] = ['A','C'] dará FALSE; 2) ['A','B'] <> ['A','C'] dará TRUE; 3) ['B'] <= ['B','C'] dará TRUE; 4) ['C','D'] >= ['A'] dará FALSE. Além dessas operações, para trabalhar com valores de um tipo de conjunto, utiliza-se a operação in, que verifica se o elemento do tipo base à esquerda do sinal de operação pertence ao conjunto à direita do sinal de operação . O resultado desta operação é um booleano. Valores de um tipo múltiplo não podem ser elementos de uma lista de E/S. Em cada implementação concreta do compilador da linguagem Pascal, o número de elementos do tipo base sobre o qual o conjunto é construído é limitado. 14. Arquivos. Operações de arquivo O tipo de dados do arquivo define uma coleção ordenada de componentes do mesmo tipo. Ao trabalhar com arquivos, são realizadas operações de E/S. Uma operação de entrada é uma transferência de dados de um dispositivo externo para a memória, uma operação de saída é uma transferência de dados da memória para um dispositivo externo. Arquivos de texto Para descrever tais arquivos, existe um tipo de texto: var TF1, TF2: Texto; Arquivos de componentes Um componente ou arquivo tipado é um arquivo com o tipo declarado de seus componentes. tipo M = Arquivo de T; onde M é o nome do tipo de arquivo; T - tipo de componente. As operações são realizadas usando procedimentos. Escreva(f, X1,X2,...XK) Arquivos não digitados Arquivos não digitados permitem que você grave seções arbitrárias da memória do computador no disco e as leia. var f: Arquivo; 1. Procedimento Assign(var F; FileName: String); Ele mapeia um nome de arquivo para uma variável. 2. Procedimento Fechar(varF); Ele quebra o vínculo entre a variável de arquivo e o arquivo de disco externo e fecha o arquivo. 3.Função Eof(var F): Booleana; {Arquivos digitados ou não digitados} Função Eof[(var F: Text)]: Booleana; {arquivos de texto} Verifica o final de um arquivo. 4. Apagar Procedimento (var F); Exclui o arquivo externo associado a F. 5. Função FileSize(var F): Integer; Retorna o tamanho em bytes do arquivo F. 6.Função FilePos(varF): LongInt; Retorna a posição atual em um arquivo. 7. Procedimento Reset(var F [: File; RecSize: Word]); Abre um arquivo existente. 8. Procedimento Reescrever(var F: Arquivo [; Recsize: Word]); Cria e abre um novo arquivo. 9. Procura de Procedimento(var F; N: LongInt); Move a posição atual do arquivo para o componente especificado. 10. Anexo de Procedimento(var F: Texto); Adição. 11.Função Eoln[(var F: Text)]: Booleano; Verifica o final de uma string. 12. Procedimento Leitura(F, V1 [, V2..., Vn]); {Arquivos digitados e não digitados} Procedimento Ler([var F: Texto;] V1 [, V2..., Vn]); {arquivos de texto} Lê um componente de arquivo em uma variável. 13. Procedimento Readln([var F: Texto;] V1 [, V2..., Vn]); Lê uma sequência de caracteres no arquivo, incluindo o marcador de fim de linha, e move para o início do próximo. 14. Função SeekEof[(var F: Text)]: Booleano; Retorna o sinal de fim de arquivo. Usado apenas para arquivos de texto abertos. 15. Procedimento Writeln([var F: Texto;] [P1, P2..., Pn]); {arquivos de texto} Executa uma operação de gravação e, em seguida, coloca um marcador de fim de linha no arquivo. 15. Módulos. Tipos de módulos Uma unidade (UNIT) em Pascal é uma biblioteca de sub-rotinas especialmente projetada. Um módulo, ao contrário de um programa, não pode ser lançado sozinho, ele só pode participar da construção de programas e outros módulos. Um módulo em Pascal é uma unidade de programa armazenada separadamente e compilada independentemente. Todos os elementos do programa do módulo podem ser divididos em duas partes: 1) elementos de programa destinados ao uso por outros programas ou módulos, tais elementos são chamados de visíveis fora do módulo; 2) elementos de software que são necessários apenas para o funcionamento do próprio módulo, são chamados de invisíveis (ou ocultos). unidade <nome do módulo>; {título do módulo} interface {descrição dos elementos de programa visíveis do módulo} implementação {descrição dos elementos de programação ocultos do módulo} começar {instruções de inicialização do elemento do módulo} final. Para se referir a uma variável declarada em um módulo, você deve usar um nome composto que consiste no nome do módulo e no nome da variável, separados por um ponto. O uso recursivo de módulos é proibido. Vamos listar os tipos de módulos. 1. Módulo do SISTEMA. O módulo SYSTEM implementa rotinas de suporte de nível inferior para todos os recursos internos, como E/S, manipulação de strings, operações de ponto flutuante e alocação dinâmica de memória. 2. Módulo DOS. O módulo Dos implementa várias rotinas e funções Pascal que são equivalentes às chamadas DOS mais usadas, como GetTime, SetTime, DiskSize e assim por diante. 3. Módulo CRT. O módulo CRT implementa vários programas poderosos que fornecem controle total sobre os recursos do PC, como controle de modo de tela, códigos de teclado estendidos, cores, janelas e sons. 4. Módulo GRÁFICO. Usando os procedimentos e funções incluídos neste módulo, você pode criar vários gráficos na tela. 5. Módulo OVERLAY. O módulo OVERLAY permite reduzir os requisitos de memória de um programa DOS em modo real. 16. Tipo de dados de referência. memória dinâmica. variáveis dinâmicas. Trabalhando com memória dinâmica Uma variável estática (alocada estaticamente) é uma variável declarada explicitamente no programa, é referida pelo nome. O lugar na memória para colocar variáveis estáticas é determinado quando o programa é compilado. Ao contrário dessas variáveis estáticas, os programas Pascal podem criar variáveis dinâmicas. A principal propriedade das variáveis dinâmicas é que elas são criadas e a memória é alocada para elas durante a execução do programa. As variáveis dinâmicas são colocadas em uma área de memória dinâmica (área de heap). Uma variável dinâmica não é especificada explicitamente nas declarações de variáveis e não pode ser referenciada pelo nome. Tais variáveis são acessadas usando ponteiros e referências. Um tipo de referência (ponteiro) define um conjunto de valores que apontam para variáveis dinâmicas de um determinado tipo, chamado de tipo base. Uma variável de tipo de referência contém o endereço de uma variável dinâmica na memória. Se o tipo base for um identificador não declarado, ele deverá ser declarado na mesma parte da declaração de tipo que o tipo de ponteiro. A palavra reservada nil denota uma constante com um valor de ponteiro que não aponta para nada. Vamos dar um exemplo da descrição de variáveis dinâmicas. var p1, p2: ^real; p3, p4: ^ inteiro; ... Procedimentos e Funções de Memória Dinâmica 1. Procedimento Novo{var p: Ponteiro). Aloca espaço na área de memória dinâmica para acomodar a variável dinâmica p", e atribui seu endereço ao ponteiro p. 2. Procedimento Descarte(var p: Ponteiro). Libera a memória alocada para alocação de variável dinâmica pelo procedimento New, e o valor do ponteiro p fica indefinido. 3. Procedimento GetMem(var p: Ponteiro; tamanho: Word). Aloca uma seção de memória na área de heap, atribui o endereço de seu início ao ponteiro p, o tamanho da seção em bytes é especificado pelo parâmetro size. 4. Procedimento FreeMem(varp: Ponteiro; tamanho: Word). Libera a área de memória, cujo endereço inicial é especificado pelo ponteiro p e o tamanho é especificado pelo parâmetro size. O valor do ponteiro p torna-se indefinido. 5. O procedimento Mark{var p: Pointer) escreve no ponteiro p o endereço do início da seção de memória dinâmica livre no momento de sua chamada. 6. O procedimento Release(var p: Pointer) libera uma seção da memória dinâmica, a partir do endereço escrito no ponteiro p pelo procedimento Mark, ou seja, limpa a memória dinâmica que estava ocupada após a chamada ao procedimento Mark. 7. Função MaxAvail: Longint retorna o comprimento em bytes da maior seção livre de memória dinâmica. 8. Função MemAvail: Longint retorna a quantidade total de memória dinâmica livre em bytes. 9. A função auxiliar SizeOf(X):Word retorna o tamanho em bytes ocupado por X, onde X pode ser um nome de variável de qualquer tipo ou um nome de tipo. 17. Estruturas de dados abstratas Tipos de dados estruturados, como arrays, conjuntos e registros, são estruturas estáticas porque seus tamanhos não mudam durante toda a execução do programa. Muitas vezes, é necessário que as estruturas de dados mudem seus tamanhos no decorrer da resolução de um problema. Essas estruturas de dados são chamadas de dinâmicas. Estes incluem pilhas, filas, listas, árvores, etc. A descrição de estruturas dinâmicas com a ajuda de arrays, registros e arquivos leva ao desperdício de memória do computador e aumenta o tempo de resolução de problemas. Cada componente de qualquer estrutura dinâmica é um registro contendo pelo menos dois campos: um campo do tipo "ponteiro" e o segundo - para posicionamento de dados. Em geral, um registro pode conter não um, mas vários ponteiros e vários campos de dados. Um campo de dados pode ser uma variável, uma matriz, um conjunto ou um registro. Se a parte indicadora contiver o endereço de um elemento da lista, a lista será chamada de unidirecional (ou vinculada individualmente). Se contiver dois componentes, estará duplamente conectado. Você pode realizar várias operações em listas, por exemplo: 1) adicionar um elemento à lista; 2) remover um elemento da lista com uma determinada chave; 3) procurar um elemento com um determinado valor do campo chave; 4) ordenação dos elementos da lista; 5) divisão da lista em duas ou mais listas; 6) combinar duas ou mais listas em uma; 7) outras operações. No entanto, como regra, não surge a necessidade de todas as operações na resolução de vários problemas. Portanto, dependendo das operações básicas que precisam ser aplicadas, existem diferentes tipos de listas. Os mais populares são pilha e fila. 18. Pilhas Uma pilha é uma estrutura de dados dinâmica, a adição de um componente ao qual e a remoção de um componente do qual são feitas de uma extremidade, chamada de topo da pilha. A pilha funciona com o princípio LIFO (Last-In, First-Out) - "Last in, first out". Geralmente, há três operações executadas em pilhas: 1) formação inicial da pilha (registro do primeiro componente); 2) adicionar um componente à pilha; 3) seleção do componente (exclusão). Para formar uma pilha e trabalhar com ela, você deve ter duas variáveis do tipo "ponteiro", sendo que a primeira determina o topo da pilha e a segunda é auxiliar. Exemplo. Escreva um programa que forme uma pilha, adicione um número arbitrário de componentes a ela e depois leia todos os componentes. Programa PILHA; usa Crt; tipo Alfa = Cadeia[10]; PComp = ^Comp; Comp = registro SD: Alfa; pPróximo: PComp end; var pTopo: PComp; sc: Alfa; Create ProcedureStack(var pTop: PComp; var sC: Alfa); começar Novo(pTop); pTopo^.pPróximo:= NIL; pTop^.sD:= sC; end; Adicione ProcedureComp(var pTop: PComp; var sC: Alfa); var pAux:PComp; começar NOVO(pAux); pAux^.pNext:= pTop; pTop:=pAux; pTop^.sD:= sC; end; Procedimento DelComp(var pTop: PComp; var sC: ALFA); começar sC:=pTop^.sD; pTopo:= pTopo^.pPróximo; end; começar Clrscr; writeln(ENTER STRING); readln(sc); CreateStack(pTop, sc); repetir writeln(ENTER STRING); readln(sc); AddComp(pTop, sc); até sC = 'FIM'; 19. Filas Uma fila é uma estrutura de dados dinâmica onde um componente é adicionado em uma extremidade e recuperado na outra extremidade. A fila funciona segundo o princípio FIFO (First-In, First-Out) - "Primeiro a entrar, primeiro a ser servido". Exemplo. Escreva um programa que forme uma fila, adicione um número arbitrário de componentes a ela e depois leia todos os componentes. Programa FILA; usa Crt; tipo Alfa = Cadeia[10]; PComp = ^Comp; Comp = registro SD: Alfa; pPróximo:PComp; end; var pBegin, pEnd: PComp; sc: Alfa; Create ProcedureQueue(var pBegin,pEnd: PComp; var sc: Alfa); começar Novo(pBegin); pBegin^.pNext:= NIL; pInício^.sD:= sC; pEnd:=pBegin; end; Procedimento AddQueue(var pEnd: PComp; var sC: alfa); var pAux:PComp; começar Novo(pAux); pAux^.pPróximo:= NIL; pFim^.pPróximo:= pAux; pEnd:= pAux; pEnd^.sD:=sC; end; Procedimento DelQueue(var pBegin: PComp; var sC: alfa); começar sC:=pBegin^.sD; pBegin:= pBegin^.pNext; end; começar Clrscr; writeln(ENTER STRING); readln(sc); CreateQueue(pBegin, pEnd, sc); repetir writeln(ENTER STRING); readln(sc); AddQueue(pEnd, sc); até sC = 'FIM'; 20. Estruturas de Dados em Árvore Uma estrutura de dados em forma de árvore é um conjunto finito de elementos-nós entre os quais existem relações - a conexão entre a fonte e o gerado. Se usarmos a definição recursiva proposta por N. Wirth, então uma estrutura de dados de árvore com tipo base t é uma estrutura vazia ou um nó do tipo t, com o qual um conjunto finito de estruturas de árvore com tipo base t, chamado subárvores, é associado. A seguir, damos as definições usadas ao operar com estruturas em árvore. Se o nó y estiver localizado diretamente abaixo do nó x, então o nó y é chamado de descendente imediato do nó x, e x é o ancestral imediato do nó y, ou seja, se o nó x está no i-ésimo nível, então o nó y é correspondentemente localizado em (i + 1 ) -º nível. O nível máximo de um nó de árvore é chamado de altura ou profundidade da árvore. Um ancestral não possui apenas um nó da árvore - sua raiz. Os nós de árvore que não têm filhos são chamados de nós de folha (ou folhas de árvore). Todos os outros nós são chamados de nós internos. O número de filhos imediatos de um nó determina o grau desse nó, e o grau máximo possível de um nó em uma determinada árvore determina o grau da árvore. Ancestrais e descendentes não podem ser intercambiados, ou seja, a conexão entre o original e o gerado atua apenas em uma direção. Se você for da raiz da árvore para algum nó específico, o número de ramos da árvore que serão percorridos nesse caso é chamado de comprimento do caminho para esse nó. Se todos os ramos (nós) de uma árvore são ordenados, então a árvore é dita ordenada. Árvores binárias são um caso especial de estruturas de árvore. São árvores em que cada filho tem no máximo dois filhos, chamados de subárvores esquerda e direita. Assim, uma árvore binária é uma estrutura de árvore cujo grau é dois. A ordenação de uma árvore binária é determinada pela seguinte regra: cada nó tem seu próprio campo de chave, e para cada nó o valor da chave é maior que todas as chaves em sua subárvore esquerda e menor que todas as chaves em sua subárvore direita. Uma árvore cujo grau é maior que dois é chamada fortemente ramificada. 21. Operações em árvores Além disso, consideraremos todas as operações em relação às árvores binárias. I. Construindo uma árvore. Apresentamos um algoritmo para construir uma árvore ordenada. 1. Se a árvore estiver vazia, os dados serão transferidos para a raiz da árvore. Se a árvore não estiver vazia, um de seus ramos desce de tal forma que a ordem da árvore não seja violada. Como resultado, o novo nó se torna a próxima folha da árvore. 2. Para adicionar um nó a uma árvore já existente, você pode usar o algoritmo acima. 3. Ao excluir um nó da árvore, você deve ter cuidado. Se o nó a ser removido for uma folha ou tiver apenas um filho, a operação é simples. Se o nó a ser excluído tiver dois descendentes, será necessário encontrar um nó entre seus descendentes que possa ser colocado em seu lugar. Isso é necessário devido à exigência de que a árvore seja encomendada. Você pode fazer isso: troque o nó a ser removido pelo nó com o maior valor de chave na subárvore esquerda ou com o nó com o menor valor de chave na subárvore direita e exclua o nó desejado como uma folha. II. Procure um nó com um determinado valor de campo-chave. Ao realizar esta operação, é necessário percorrer a árvore. É necessário levar em conta as diferentes formas de escrever uma árvore: prefixo, infixo e pós-fixo. Surge a pergunta: como representar os nós da árvore para que seja mais conveniente trabalhar com eles? É possível representar uma árvore usando um array, onde cada nó é descrito por um valor do tipo combinado, que possui um campo de informação do tipo caractere e dois campos do tipo referência. Mas isso não é muito conveniente, pois as árvores possuem um grande número de nós que não são pré-determinados. Portanto, é melhor usar variáveis dinâmicas ao descrever uma árvore. Em seguida, cada nó é representado por um valor do mesmo tipo, que contém uma descrição de um determinado número de campos de informação, e o número de campos correspondentes deve ser igual ao grau da árvore. É lógico definir a ausência de descendentes pela referência nil. Então, em Pascal, a descrição de uma árvore binária pode ser assim: TIPO TreeLink = ^Árvore; árvore = registro; Inf: <tipo de dados>; Esquerda, Direita: TreeLink; End. 22. Exemplos de implementação de operações 1. Construa uma árvore de XNUMX nós de altura mínima, ou uma árvore perfeitamente equilibrada (o número de nós das subárvores esquerda e direita de tal árvore não deve diferir em mais de um). Algoritmo de construção recursiva: 1) o primeiro nó é tomado como raiz da árvore; 2) a subárvore esquerda de nl nós é construída da mesma forma; 3) a subárvore direita de nr nós é construída da mesma maneira; nr = n - nl - 1 Como um campo de informação, tomaremos os números dos nós inseridos no teclado. A função recursiva que implementa essa construção ficará assim: Árvore de Funções(n: Byte): TreeLink; Vart: TreeLink; nl,nr,x: Byte; Começar Se n = 0 então Árvore:= nil Outro Começar nl:= n div 2; nr = n - nl - 1; writeln('Digite o número do vértice); leia(x); novo(t); t^.inf:= x; t^.left:= Árvore(nl); t^.right:= Árvore(nr); Árvore:=t; End; {Árvore} End. 2. Na árvore ordenada binária, encontre o nó com o valor dado do campo-chave. Se não houver tal elemento na árvore, adicione-o à árvore. Procedimento de pesquisa(x: Byte; var t: TreeLink); Começar Se t = zero então Começar Novo(t); t^inf := x; t^.esquerda:= nil; t^.direita:= nil; Terminar Senão se x < t^.inf então Pesquisar(x, t^.esquerda) Caso contrário, se x > t^.inf então Pesquisar(x, t^.direita) Outro Começar {processo encontrado elemento} ... End; End. 23. O conceito de gráfico. Formas de representar um gráfico Um grafo é um par G = (V,E), onde V é um conjunto de objetos de natureza arbitrária, chamados vértices, e E é uma família de pares ei = (vil, vi2), vijOV, chamados arestas. No caso geral, o conjunto V e (ou) a família E podem conter um número infinito de elementos, mas consideraremos apenas grafos finitos, ou seja, grafos para os quais V e E são finitos. Se a ordem dos elementos incluídos em ei importa, então o gráfico é chamado direcionado, abreviado - dígrafo, caso contrário - não direcionado. As arestas de um dígrafo são chamadas de arcos. Se e = , então os vértices v e u são chamados de extremidades da aresta. Aqui dizemos que a aresta e é adjacente (incidente) a cada um dos vértices v e u. Os vértices v e e também são chamados de adjacentes (incidentes). No caso geral, arestas da forma e = ; tais arestas são chamadas de laços. O grau de um vértice do grafo é o número de arestas incidentes ao vértice dado, com laços contados duas vezes. O peso de um vértice é um número (real, inteiro ou racional) atribuído a um determinado vértice (interpretado como custo, rendimento, etc.). Um caminho em um grafo (ou uma rota em um dígrafo) é uma sequência alternada de vértices e arestas (ou arcos em um dígrafo) da forma v0, (v0,v1), v1,..., (vn -1, vn), vn. O número n é chamado de comprimento do caminho. Um caminho sem arestas repetidas é chamado de cadeia; um caminho sem vértices repetidos é chamado de cadeia simples. Um caminho fechado sem arestas repetidas é chamado de ciclo (ou contorno em um dígrafo); sem repetir vértices (exceto o primeiro e o último) - um ciclo simples. Um grafo é dito conectado se houver um caminho entre quaisquer dois de seus vértices, e desconectado caso contrário. Existem várias maneiras de representar gráficos. 1. Matriz de incidência. Esta é uma matriz retangular n x m, onde n é o número de vértices e m é o número de arestas. 2. Matriz de adjacência. Esta é uma matriz quadrada de dimensões n × n, onde n é o número de vértices. 3. Lista de adjacências (incidentes). Representa uma estrutura de dados que para cada vértice do grafo armazena uma lista de vértices adjacentes a ele. A lista é uma matriz de ponteiros, cujo i-ésimo elemento contém um ponteiro para a lista de vértices adjacentes ao i-ésimo vértice. 4. Lista de listas. É uma estrutura de dados semelhante a uma árvore na qual um ramo contém listas de vértices adjacentes a cada um. 24. Várias Representações Gráficas Para implementar um gráfico como uma lista de incidência, você pode usar o seguinte tipo: TipoLista = ^S; S=registro; informação: Byte; próximo: Lista; end; Então o gráfico é definido da seguinte forma: Vargr: array[1..n] da Lista; Agora vamos nos voltar para o procedimento de travessia do gráfico. Este é um algoritmo auxiliar que permite visualizar todos os vértices do gráfico, analisar todos os campos de informação. Se considerarmos uma travessia de grafos em profundidade, existem dois tipos de algoritmos: recursivos e não recursivos. Em Pascal, a travessia em profundidade ficaria assim: Procedimento Obhod(gr: Gráfico; k: Byte); Varg: Gráfico; l:Lista; Começar nov[k]:= falso; g:=gr; Enquanto g^.inf <> k faz g:= g^.próximo; eu:= g^.smeg; Enquanto l <> nil começam Se nov[l^.inf] então Obhod(gr, l^.inf); l:= l^.próximo; End; End; Representando um gráfico como uma lista de listas Um gráfico pode ser definido usando uma lista de listas da seguinte forma: TipoLista = ^Tlista; tlist=registro informação: Byte; próximo: Lista; end; Gráfico = ^TGpaph; TGpaph = registro informação: Byte; smeg: Lista; próximo: gráfico; end; Ao percorrer o grafo em largura, selecionamos um vértice arbitrário e examinamos todos os vértices adjacentes a ele de uma só vez. Aqui está um procedimento para percorrer um gráfico em largura em pseudocódigo: Procedimento Obhod2(v); Começar fila = O; fila <= v; nov[v] = Falso; Enquanto fila <> O do Começar p <= fila; Para u em spisok(p) faça Se novo[u] então Começar nov[u]:= Falso; fila <= u; End; End; End; 25. Tipo de objeto em Pascal. O conceito de um objeto, sua descrição e uso Uma linguagem de programação orientada a objetos é caracterizada por três propriedades principais: 1) encapsulamento. A combinação de registros com procedimentos e funções que manipulam os campos desses registros forma um novo tipo de dado - um objeto; 2) herança. Definição de um objeto e seu uso posterior para construir uma hierarquia de objetos filho com a capacidade de cada objeto filho relacionado à hierarquia acessar o código e os dados de todos os objetos pai; 3) polimorfismo. Dando a uma ação um único nome, que é então compartilhado para cima e para baixo na hierarquia de objetos, com cada objeto na hierarquia executando essa ação de uma forma adequada. Falando do objeto, apresentamos um novo tipo de dados - objeto. Um tipo de objeto é uma estrutura que consiste em um número fixo de componentes. Cada componente é um campo contendo dados de um tipo estritamente definido ou um método que executa operações em um objeto. Um tipo de objeto pode herdar componentes de outro tipo de objeto. Se o tipo T2 herda do tipo T1, o tipo T2 é filho do tipo G e o próprio tipo G é pai do tipo G2. O código-fonte a seguir fornece um exemplo de uma declaração de tipo de objeto. tipo ponto = objeto X, Y: inteiro; end; Rect = objeto A, B: Ponto T; procedimento Init(XA, YA, XB, YB: Inteiro); procedimento Copiar(var R: TRectangle); procedimento Move(DX, DY: Inteiro); procedimento Grow(DX, DY: Inteiro); procedimento Intersect(var R: TRectangle); procedimento União(var R: TRectangle); função Contém(P: Ponto): Booleano; end; Ao contrário de outros tipos, os tipos de objeto só podem ser declarados na seção de declaração de tipo no nível mais externo do escopo de um programa ou módulo. Assim, os tipos de objeto não podem ser declarados em uma seção de declaração de variável ou dentro de um bloco de procedimento, função ou método. Um tipo de componente de tipo de arquivo não pode ter um tipo de objeto ou qualquer tipo de estrutura contendo componentes de tipo de objeto. 26. Herança Herança é o processo de gerar novos tipos filho a partir de tipos pai existentes, enquanto o filho recebe (herda) do pai todos os seus campos e métodos. O tipo descendente, neste caso, é chamado de tipo herdeiro ou filho. E o tipo do qual o tipo filho herda é chamado de tipo pai. Os campos e métodos herdados podem ser usados inalterados ou redefinidos (modificados). N. Wirth em sua linguagem Pascal buscou a máxima simplicidade, de modo que não a complicou introduzindo a relação de herança. Portanto, os tipos em Pascal não podem herdar. No entanto, o Turbo Pascal 7.0 estende essa linguagem para oferecer suporte à herança. Uma dessas extensões é uma nova categoria de estrutura de dados relacionada a registros, mas muito mais poderosa. Os tipos de dados nesta nova categoria são definidos usando a nova palavra reservada Object. A sintaxe é muito semelhante à sintaxe para definir registros: Formato <nome do tipo> = Objeto [(<nome do tipo pai>)] ([<escopo>] <descrição dos campos e métodos>)+ end; O sinal "+" após uma construção de sintaxe entre parênteses significa que essa construção deve ocorrer uma ou mais vezes nesta descrição. O escopo é uma das seguintes palavras-chave: ▪ Privado; ▪ Protegido; ▪ Público. O escopo caracteriza para quais partes do programa estarão disponíveis os componentes cujas descrições seguem a palavra-chave que nomeia este escopo. Para obter mais informações sobre escopos de componentes, consulte a pergunta nº 28. A herança é uma ferramenta poderosa usada no desenvolvimento de programas. Permite implementar na prática a decomposição orientada a objetos do problema, utilizando a linguagem para expressar a relação entre objetos de tipos que formam uma hierarquia, e também promove a reutilização do código do programa. 27. Instanciar Objetos Uma instância de objeto é criada declarando uma variável ou constante de um tipo de objeto, ou aplicando o procedimento padrão New a uma variável do tipo "ponteiro para tipo de objeto". O objeto resultante é chamado de instância do tipo de objeto. Se um tipo de objeto contém métodos virtuais, as instâncias desse tipo de objeto devem ser inicializadas chamando um construtor antes de chamar qualquer método virtual. A atribuição de uma instância de um tipo de objeto não implica a inicialização da instância. Um objeto é inicializado pelo código gerado pelo compilador que é executado entre a invocação do construtor e o ponto em que a execução realmente atinge a primeira instrução no bloco de código do construtor. Se a instância do objeto não for inicializada e a verificação de intervalo estiver habilitada (pela diretiva {$R+}), a primeira chamada ao método virtual da instância do objeto dará um erro em tempo de execução. Se a verificação de intervalo estiver desativada pela diretiva {$R-}), a primeira chamada para um método virtual de um objeto não inicializado pode levar a um comportamento imprevisível. A regra de inicialização obrigatória também se aplica a instâncias que são componentes de tipos struct. Por exemplo: var Comentário: array [1..5] de TStrField; I: inteiro começar para I:= 1 a 5 faça Comentário [I].Init (1, I + 10, 40, 'first_name'); . . . para I:= 1 a 5 do Comentário [I].Done; end; Para instâncias dinâmicas, a inicialização geralmente é sobre o posicionamento e a limpeza é sobre a exclusão, que é obtida por meio da sintaxe estendida dos procedimentos padrão Novo e Descartar. Por exemplo: var SP: StrFieldPtr; começar New(SP, Init(1, 1, 25, 'nome_nome'); SP^.Put('Vladimir'); SP^.Exibir; . . . Descarte (SP, Feito); final. Um ponteiro para um tipo de objeto é uma atribuição compatível com um ponteiro para qualquer tipo de objeto pai, portanto, em tempo de execução, um ponteiro para um tipo de objeto pode apontar para uma instância desse tipo ou para uma instância de qualquer tipo filho. 28. Componentes e Escopo O escopo de um identificador de bean vai além do tipo de objeto. Além disso, o escopo de um identificador de bean se estende pelos blocos de procedimentos, funções, construtores e destruidores que implementam os métodos do tipo de objeto e seus descendentes. Com base nessas considerações, o identificador do componente deve ser exclusivo no tipo de objeto e em todos os seus descendentes, bem como em todos os seus métodos. Em uma declaração de tipo de objeto, um cabeçalho de método pode especificar os parâmetros do tipo de objeto que está sendo descrito, mesmo que a declaração ainda não esteja completa. Considere o esquema a seguir para uma declaração de tipo que contém componentes de todos os escopos válidos: Formato <nome do tipo> = Objeto [(<nome do tipo pai>)] Privado <descrições privadas de campos e métodos> Protegido <descrições de campos e métodos protegidos> Público <descrições públicas de campos e métodos> end; Os campos e métodos descritos na seção Private só podem ser usados dentro do módulo que contém suas declarações e em nenhum outro lugar. Campos e métodos protegidos, ou seja, aqueles descritos na seção Protegidos, são visíveis para o módulo onde o tipo está definido e para os descendentes desse tipo. Os campos e métodos da seção Public não possuem restrições de uso e podem ser usados em qualquer lugar do programa que tenha acesso a um objeto desse tipo. O escopo do identificador de componente descrito na parte privada da declaração de tipo é limitado ao módulo (programa) que contém a declaração de tipo de objeto. Em outras palavras, os beans identificadores privados atuam como identificadores públicos comuns dentro do módulo que contém a declaração do tipo de objeto, e fora do módulo quaisquer beans e identificadores privados são desconhecidos e inacessíveis. Ao colocar tipos de objetos relacionados no mesmo módulo, você pode ter certeza de que esses objetos podem acessar os componentes privados uns dos outros, e esses componentes privados serão desconhecidos para outros módulos. 29. Métodos Uma declaração de método dentro de um tipo de objeto corresponde a uma declaração de método forward (forward). Assim, em algum lugar depois de uma declaração de tipo de objeto, mas dentro do mesmo escopo que o escopo da declaração de tipo de objeto, um método deve ser implementado definindo sua declaração. Para métodos procedurais e funcionais, a declaração de definição assume a forma de um procedimento normal ou declaração de função, com a exceção de que, neste caso, o identificador de procedimento ou função é tratado como um identificador de método. A descrição de definição de um método sempre contém um parâmetro implícito com o identificador Self, correspondente a um parâmetro de variável formal que possui um tipo de objeto. Dentro de um bloco de método, Self representa a instância cujo componente de método foi especificado para invocar o método. Assim, quaisquer alterações nos valores dos campos Self são refletidas na instância. Métodos Virtuais Os métodos são estáticos por padrão, mas, exceto pelos construtores, eles podem ser virtuais (incluindo a diretiva virtual na declaração do método). O compilador resolve as referências a chamadas de métodos estáticos durante o processo de compilação, enquanto as chamadas de métodos virtuais são resolvidas em tempo de execução. Isso às vezes é chamado de ligação tardia. A substituição de um método estático é independente da alteração do cabeçalho do método. Por outro lado, uma substituição de método virtual deve preservar a ordem, os tipos e nomes de parâmetros e os tipos de resultado da função, se houver. Além disso, a redefinição deve incluir novamente a diretiva virtual. Métodos dinâmicos O Borland Pascal suporta métodos adicionais de ligação tardia chamados métodos dinâmicos. Os métodos dinâmicos diferem dos métodos virtuais apenas na maneira como são despachados em tempo de execução. Em todos os outros aspectos, os métodos dinâmicos são considerados equivalentes aos métodos virtuais. Uma declaração de método dinâmico é equivalente a uma declaração de método virtual, mas a declaração de método dinâmico deve incluir o índice de método dinâmico, que é especificado imediatamente após a palavra-chave virtual. O índice de um método dinâmico deve ser uma constante inteira entre 1 e 656535 e deve ser exclusivo entre os índices de outros métodos dinâmicos contidos no tipo de objeto ou em seus ancestrais. Por exemplo: procedimento FileOpen(var Msg: TMessage); 100 virtuais; Uma substituição de um método dinâmico deve corresponder à ordem, tipos e nomes dos parâmetros e corresponder exatamente ao tipo de resultado da função do método pai. A substituição também deve incluir uma diretiva virtual seguida pelo mesmo índice de método dinâmico que foi especificado no tipo de objeto ancestral. 30. Construtores e destruidores Construtores e destruidores são formas especializadas de métodos. Usado em conexão com a sintaxe estendida dos procedimentos padrão New e Dispose, construtores e destruidores têm a capacidade de colocar e remover objetos dinâmicos. Além disso, os construtores têm a capacidade de executar a inicialização necessária de objetos contendo métodos virtuais. Como todos os outros métodos, construtores e destruidores podem ser herdados e objetos podem conter qualquer número de construtores e destruidores. Construtores são usados para inicializar objetos recém-criados. Normalmente, a inicialização é baseada nos valores passados ao construtor como parâmetros. Um construtor não pode ser virtual porque o mecanismo de despacho de um método virtual depende do construtor que inicializou o objeto primeiro. Aqui estão alguns exemplos de construtores: construtor Field.Copy(var F: Field); começar Próprio:=F; end; A ação principal de um construtor de um tipo derivado (filho) é quase sempre chamar o construtor apropriado de seu pai imediato para inicializar os campos herdados do objeto. Após executar este procedimento, o construtor inicializa os campos do objeto que pertencem apenas ao tipo derivado. Os destruidores são o oposto dos construtores e são usados para limpar objetos depois de serem usados. Normalmente, a limpeza consiste em remover todos os campos de ponteiro do objeto. Nota Um destruidor pode ser virtual, e muitas vezes é. Um destruidor raramente tem parâmetros. Aqui estão alguns exemplos de destruidores: destruidor Campo Feito; começar FreeMem(Nome, Comprimento(Nome^) + 1); end; destruidor StrField.Done; começar FreeMem(Valor, Len); Campo Feito; end; O destruidor de um tipo filho, como o TSrField acima. Concluído, normalmente primeiro remove os campos de ponteiro introduzidos no tipo derivado e, em seguida, como última etapa, chama o destruidor de coletor apropriado do pai imediato para remover os campos de ponteiro herdados do objeto. 31. Destruidores O Borland Pascal fornece um tipo especial de método chamado coletor de lixo (ou destruidor) para limpar e excluir um objeto alocado dinamicamente. O destruidor combina a etapa de exclusão de um objeto com quaisquer outras ações ou tarefas necessárias para esse tipo de objeto. Você pode definir vários destruidores para um único tipo de objeto. Os destruidores podem ser herdados e podem ser estáticos ou virtuais. Como diferentes finalizadores tendem a exigir diferentes tipos de objetos, geralmente é recomendável que os destruidores sejam sempre virtuais para que o destruidor correto seja executado para cada tipo de objeto. O destruidor de palavras reservadas não precisa ser especificado para cada método de limpeza, mesmo que a definição de tipo do objeto contenha métodos virtuais. Destrutores realmente só funcionam em objetos alocados dinamicamente. Quando um objeto alocado dinamicamente é limpo, o destruidor executa uma função especial: ele garante que o número correto de bytes seja sempre liberado na área de memória alocada dinamicamente. Não pode haver preocupação em usar um destruidor com objetos alocados estaticamente; de fato, ao não passar o tipo do objeto para o destruidor, o programador priva um objeto desse tipo de todos os benefícios do gerenciamento dinâmico de memória no Borland Pascal. Destrutores realmente se tornam eles mesmos quando objetos polimórficos devem ser apagados e quando a memória que eles ocupam deve ser desalocada. Objetos polimórficos são aqueles objetos que foram atribuídos a um tipo pai devido às regras de compatibilidade de tipo estendida do Borland Pascal. O termo "polimórfico" é apropriado porque o código que processa um objeto "não sabe" exatamente em tempo de compilação que tipo de objeto ele precisará processar. A única coisa que ele sabe é que esse objeto pertence a uma hierarquia de objetos que são descendentes do tipo de objeto especificado. O próprio método destruidor pode estar vazio e executar apenas esta função: destructorAnObject.Done; começar end; O que é útil neste destruidor não é a propriedade do seu corpo, porém, o compilador gera o código do epílogo em resposta à palavra reservada do destruidor. É como um módulo que não exporta nada, mas faz algum trabalho invisível executando sua seção de inicialização antes de iniciar o programa. Toda a ação acontece nos bastidores. 32. Métodos Virtuais Um método se torna virtual se sua declaração de tipo de objeto for seguida pela nova palavra reservada virtual. Se um método em um tipo pai for declarado como virtual, todos os métodos com o mesmo nome em tipos filho também deverão ser declarados virtuais para evitar um erro do compilador. A seguir estão os objetos da folha de pagamento de exemplo, devidamente virtualizados: modelo PEfuncionário = ^TEFuncionário; Temployee = objeto Nome, Título: string[25]; Taxa: Reais; construtor Init(AName, ATitle: String; ARate: Real); função GetPayAmount: Real; virtual; função GetName: String; função GetTitle: String; função GetRate: Real; procedimento Mostrar; virtual; end; PHhourly = ^THourly; THourly = object(TEFuncionário); Hora: Inteiro; construtor Init(AName, ATitle: String; ARate: Real; Hora: Inteiro); função GetPayAmount: Real; virtual; função GetTime: Inteiro; end; PSAssalariado = ^TSAssalariado; TSalario = objeto(TEEmpregado); função GetPayAmount: Real; virtual; end; PComissionado = ^TComissionado; TComissionado = objeto(Assalariado); Comissão: Real; Valor das Vendas: Reais; construtor Init(AName, ATitle: String; ARate, AComissão, ASVendasValor: Real); função GetPayAmount: Real; virtual; end; Um construtor é um tipo especial de procedimento que faz algum trabalho de configuração para o mecanismo de método virtual. Além disso, o construtor deve ser chamado antes de qualquer método virtual ser chamado. Chamar um método virtual sem primeiro chamar o construtor pode bloquear o sistema e não há como o compilador verificar a ordem na qual os métodos são chamados. Todo tipo de objeto que possui métodos virtuais deve ter um construtor. O construtor deve ser chamado antes de qualquer outro método virtual ser chamado. Chamar um método virtual sem uma chamada anterior ao construtor pode causar um bloqueio do sistema e o compilador não pode verificar a ordem em que os métodos são chamados. 33. Campos de dados de objetos e parâmetros de métodos formais A implicação do fato de que métodos e seus objetos compartilham um escopo comum é que os parâmetros formais de um método não podem ser idênticos a nenhum dos campos de dados do objeto. Esta não é uma nova limitação imposta pela programação orientada a objetos, mas sim as mesmas velhas regras de escopo que Pascal sempre teve. Isso é o mesmo que proibir os parâmetros formais de um procedimento de serem idênticos às variáveis locais do procedimento. Considere um exemplo que ilustra esse erro para um procedimento: procedimento CrunchIt(Crunchee: MyDataRec, Crunchby, Código de Erro: inteiro); var A, B: caractere; Código de erro: inteiro; começar . . . end; Ocorre um erro na linha que contém a declaração da variável local ErrorCode. Isso ocorre porque os identificadores do parâmetro formal e da variável local são os mesmos. As variáveis locais de um procedimento e seus parâmetros formais compartilham um escopo comum e, portanto, não podem ser idênticos. Você receberá uma mensagem "Erro 4: identificador duplicado" se tentar compilar algo assim. O mesmo erro ocorre ao tentar atribuir um parâmetro de método formal ao nome do campo do objeto ao qual esse método pertence. As circunstâncias são um pouco diferentes, pois colocar um cabeçalho de sub-rotina dentro de uma estrutura de dados é um aceno para uma inovação no Turbo Pascal, mas os princípios básicos do escopo do Pascal não mudaram. Você ainda precisa respeitar uma cultura específica ao escolher identificadores de variáveis e parâmetros. Alguns estilos de programação oferecem maneiras de nomear campos de tipo para reduzir o risco de identificadores duplicados. Por exemplo, a notação húngara sugere que os nomes dos campos comecem com um prefixo "m". 34. Encapsulamento A combinação de código e dados em um objeto é chamada de encapsulamento. Em princípio, é possível fornecer métodos suficientes para que o usuário de um objeto nunca acesse diretamente os campos do objeto. Algumas outras linguagens orientadas a objetos, como Smalltalk, requerem encapsulamento obrigatório, mas o Borland Pascal tem uma escolha. Por exemplo, os objetos TEmployee e THourly são escritos de tal forma que não há absolutamente nenhuma necessidade de acessar diretamente seus campos de dados internos: tipo Temployee = objeto Nome, Título: string[25]; Taxa: Reais; procedimento Init(AName, ATitle: string; ARate: Real); função GetName: String; função GetTitle: String; função GetRate: Real; função GetPayAmount: Real; end; THourly = object(TEFuncionário) Hora: Inteiro; procedimento Init(AName, ATitle: string; ARate: Real, Atime: Inteiro); função GetPayAmount: Real; end; Existem apenas quatro campos de dados aqui: Nome, Título, Taxa e Tempo. Os métodos GetName e GetTitle exibem o sobrenome e a posição do trabalhador, respectivamente. O método GetPayAmount usa Rate, e no caso de um trabalho THourly e Time para calcular o valor dos pagamentos ao trabalho. Não há mais necessidade de se referir diretamente a esses campos de dados. Assumindo a existência de uma instância AnHourly do tipo THourly, poderíamos usar um conjunto de métodos para manipular os campos de dados do AnHourly, assim: com um fazer de hora em hora começar Init (Aleksandr Petrov, operador de empilhadeira' 12.95, 62); {Exibe o sobrenome, cargo e valor pagamentos} Exposição; end; Deve-se notar que o acesso aos campos de um objeto é realizado apenas com a ajuda de métodos desse objeto. 35. Objetos em expansão Se um tipo derivado for definido, os métodos do tipo pai serão herdados, mas poderão ser substituídos, se desejado. Para substituir um método herdado, simplesmente declare um novo método com o mesmo nome do método herdado, mas com um corpo diferente e (se necessário) um conjunto de parâmetros diferente. Vamos definir um tipo filho de TEmployee que representa um funcionário que recebe uma taxa horária no exemplo a seguir: const Períodos de Pagamento = 26; { períodos de pagamento } Limite de horas extras = 80; { para o período de pagamento } Fator Hora Extra = 1.5; { taxa horária } tipo THourly = object(TEFuncionário) Hora: Inteiro; procedimento Init(AName, ATitle: string; ARate: Real, Atime: Inteiro); função GetPayAmount: Real; end; procedimento THourly.Init(AName, ATitle: string; ARate: Real, Atime: Inteiro); começar TEmployee.Init(ANome, ATitle, ARate); Hora:= A Hora; end; função THourly.GetPayAmount: Real; var Horas extras: Inteiro; começar Horas Extras:= Horas - Limite de Horas Extras; se Horas extras > 0 então GetPayAmount:= RoundPay(Limite de Horas Extras * Taxa + RateOverTime * OvertimeFactor *Avaliar) outro GetPayAmount:= RoundPay(Tempo * Taxa) end; Ao chamar um método substituído, você deve ter certeza de que o tipo de objeto derivado inclui a funcionalidade do pai. Além disso, qualquer alteração no método pai afeta automaticamente todos os métodos filho. Observação importante: Embora os métodos possam ser substituídos, os campos de dados não podem ser substituídos. Depois que um campo de dados é definido em uma hierarquia de objetos, nenhum tipo filho pode definir um campo de dados com exatamente o mesmo nome. 36. Compatibilidade de tipos de objetos A herança modifica as regras de compatibilidade de tipo do Borland Pascal até certo ponto. Um descendente herda a compatibilidade de tipo de todos os seus ancestrais. Essa compatibilidade de tipo estendida assume três formas: 1) entre implementações de objetos; 2) entre ponteiros para implementações de objetos; 3) entre parâmetros formais e reais. A compatibilidade de tipo se estende apenas do filho ao pai. Por exemplo, TSalaried é filho de TEmployee e TCommissioned é filho de TSalaried. Considere as seguintes descrições: var UmFuncionário: TEFuncionário; AAssalariado: TAssalariado; PComissionado: TComissionado; TEemployeePtr: ^TEemployee; TSalariedPtr: ^TSalariado; TComissionadoPtr: ^TComissionado; Sob essas descrições, os seguintes operadores de atribuição são válidos: AnFuncionário:=ASAssalariado; AAssalariado:= AComissionado; TCommissionedPtr:= AComissionado; Em geral, a regra de compatibilidade de tipo é formulada da seguinte forma: a fonte deve ser capaz de preencher completamente o receptor. Os tipos derivados contêm tudo o que seus tipos pai contêm devido à propriedade de herança. Portanto, o tipo derivado tem um tamanho não menor que o tamanho do pai. Atribuir um objeto pai a um objeto filho pode deixar alguns campos do objeto pai indefinidos, o que é perigoso e, portanto, ilegal. Nas instruções de atribuição, apenas os campos comuns a ambos os tipos serão copiados da origem para o destino. No operador de atribuição: AnFuncionário:= AComissionado; Somente os campos Nome, Título e Taxa de ACommissioned serão copiados para AnEmployee, pois esses são os únicos campos compartilhados entre TCommissioned e TEmployee. A compatibilidade de tipo também funciona entre ponteiros para tipos de objeto e segue as mesmas regras gerais das implementações de objeto. Um ponteiro para um filho pode ser atribuído a um ponteiro para o pai. Dadas as definições anteriores, as seguintes atribuições de ponteiro são válidas: TSalariedPtr:= TCommissionedPtr; TEmployeePtr:= TSalariedPtr; TEmployeePtr:= PComissionedPtr; Um parâmetro formal (um valor ou um parâmetro de variável) de um determinado tipo de objeto pode ter como parâmetro real um objeto de seu próprio tipo ou objetos de todos os tipos filho. Se você definir um cabeçalho de procedimento como este: procedimento CalcFedTax(Vítima: TSalaried); então os tipos de parâmetros reais podem ser TSalaried ou TCommissioned, mas não TEmployee. A vítima também pode ser um parâmetro variável. Nesse caso, as mesmas regras de compatibilidade são seguidas. O parâmetro value é um ponteiro para o objeto real que está sendo enviado como parâmetro e o parâmetro variable é uma cópia do parâmetro real. Essa cópia inclui apenas os campos que fazem parte do tipo do parâmetro de valor formal. Isso significa que o parâmetro real é convertido no tipo do parâmetro formal. 37. Sobre a montadora Antigamente, assembler era uma linguagem sem saber que era impossível fazer um computador fazer algo útil. Aos poucos a situação mudou. Surgiram meios de comunicação mais convenientes com um computador. Mas, ao contrário de outras linguagens, o assembler não morreu; além disso, não poderia fazer isso em princípio. Por quê? Em busca de uma resposta, tentaremos entender o que é a linguagem assembly em geral. Em suma, a linguagem assembly é uma representação simbólica da linguagem de máquina. Todos os processos na máquina no nível mais baixo de hardware são acionados apenas por comandos (instruções) da linguagem de máquina. A partir disso fica claro que, apesar do nome comum, a linguagem assembly para cada tipo de computador é diferente. Isso também se aplica à aparência de programas escritos em assembler e às ideias das quais essa linguagem é um reflexo. Realmente resolver problemas relacionados a hardware (ou, ainda mais, relacionados a hardware, como melhorar a velocidade do programa) é impossível sem o conhecimento do montador. Um programador ou qualquer outro usuário pode usar qualquer ferramenta de alto nível até programas para construir mundos virtuais e, talvez, nem mesmo suspeitar que o computador está realmente executando não os comandos da linguagem em que seu programa está escrito, mas sua representação transformada na forma de uma sequência de comandos chata e maçante de uma linguagem completamente diferente - linguagem de máquina. Agora imagine que tal usuário tenha um problema fora do padrão. Por exemplo, seu programa deve funcionar com algum dispositivo incomum ou realizar outras ações que exijam conhecimento dos princípios do hardware do computador. Não importa quão boa seja a linguagem em que o programador escreveu seu programa, ele não pode prescindir de conhecer o montador. E não é por acaso que quase todos os compiladores de linguagens de alto nível contêm meios de conectar seus módulos com módulos em assembler ou suportam acesso ao nível de programação em assembler. Um computador é composto de vários dispositivos físicos, cada um conectado a uma única unidade chamada de unidade do sistema. 38. Modelo de software do microprocessador No mercado de computadores de hoje, há uma grande variedade de diferentes tipos de computadores. Portanto, é possível supor que o consumidor terá uma dúvida - como avaliar as capacidades de um determinado tipo (ou modelo) de um computador e suas características distintivas de computadores de outros tipos (modelos). Considerar apenas o diagrama de blocos de um computador não é suficiente para isso, pois fundamentalmente difere pouco em máquinas diferentes: todos os computadores têm RAM, um processador e dispositivos externos. Diferentes são as formas, meios e recursos utilizados pelos quais o computador funciona como um único mecanismo. Para reunir todos os conceitos que caracterizam um computador em termos de suas propriedades funcionais controladas por programa, existe um termo especial - arquitetura de computador. Pela primeira vez, o conceito de arquitetura de computadores começou a ser mencionado com o advento das máquinas de terceira geração para sua avaliação comparativa. Faz sentido começar a aprender a linguagem assembly de qualquer computador somente depois de descobrir qual parte do computador fica visível e disponível para programação nessa linguagem. Este é o chamado modelo de programa de computador, parte do qual é o modelo de programa do microprocessador, que contém 32 registros que estão mais ou menos disponíveis para uso do programador. Esses registradores podem ser divididos em dois grandes grupos: 1) 16 cadastros de usuários; 2) 16 registros do sistema. Programas em linguagem assembly usam registradores muito fortemente. A maioria dos registradores tem um propósito funcional específico. Além dos registradores listados acima, os desenvolvedores de processadores introduzem registradores adicionais no modelo de software projetado para otimizar certas classes de cálculos. Assim, na família de processadores Pentium Pro (MMX) da Intel Corporation, foi introduzida a extensão MMX da Intel. Ele inclui 8 (MM0-MM7) registradores de 64 bits e permite que você execute operações inteiras em pares de vários novos tipos de dados: 1) oito bytes compactados; 2) quatro palavras embaladas; 3) duas palavras duplas; 4) palavra quádrupla; Em outras palavras, com uma instrução de extensão MMX, o programador pode, por exemplo, somar duas palavras duplas. Fisicamente, nenhum novo registro foi adicionado. MM0-MM7 são mantissas (64 bits inferiores) de uma pilha de registradores FPU (unidade de ponto flutuante - coprocessador) de 80 bits. Além disso, no momento existem as seguintes extensões do modelo de programação - 3DNOW! da AMD; SSE, SSE2, SSE3, SSE4. As últimas 4 extensões são suportadas pelos processadores AMD e Intel. 39. Registros de usuários Como o nome indica, os registros de usuário são chamados porque o programador pode usá-los ao escrever seus programas. Esses registros incluem: 1) oito registradores de 32 bits que podem ser usados por programadores para armazenar dados e endereços (também chamados de registradores de propósito geral (RON)): ▪ eax/ax/ah/al; ▪ ebx/bx/bh/bl; ▪ edx/dx/dh/dl; ▪ ecx/cx/ch/cl; ▪ eb/pb; ▪ esi/si; ▪ edi/di; ▪ esp/sp. 2) seis registradores de segmento: ▪ cs; ▪ ds; ▪ ss; ▪ es; ▪fs; ▪gs; 3) registros de status e controle: ▪ flags registram eflags/flags; ▪ registro de ponteiro de comando eip/ip. A figura a seguir mostra os principais registros do microprocessador: Registros de uso geral
40. Registros gerais Todos os registros deste grupo permitem acessar suas partes "inferiores". Apenas as partes inferiores de 16 e 8 bits desses registradores podem ser usadas para auto-endereçamento. Os 16 bits superiores desses registradores não estão disponíveis como objetos independentes. Vamos listar os registradores pertencentes ao grupo de registradores de uso geral. Como esses registradores estão fisicamente localizados no microprocessador dentro da unidade lógica aritmética (ALU), eles também são chamados de registradores ALU: 1) eax/ax/ah/al (Registro do acumulador) - bateria. Usado para armazenar dados intermediários. Em alguns comandos, o uso deste registro é obrigatório; 2) ebx/bx/bh/bl (base cadastral) - base cadastral. Usado para armazenar o endereço base de algum objeto na memória; 3) ecx/cx/ch/cl (registro de contagem) - registro de contador. É usado em comandos que executam algumas ações repetitivas. Seu uso é muitas vezes implícito e oculto no algoritmo do comando correspondente. Por exemplo, o comando de organização de loop, além de transferir o controle para um comando localizado em determinado endereço, analisa e decrementa o valor do registrador ecx/cx em um; 4) edx/dx/dh/dl (registro de dados) - registro de dados. Assim como o registrador eax/ax/ah/al, ele armazena dados intermediários. Alguns comandos requerem seu uso; para alguns comandos isso acontece implicitamente. Os dois registradores a seguir são usados para suportar as chamadas operações em cadeia, ou seja, operações que processam sequencialmente cadeias de elementos, cada um dos quais pode ter 32, 16 ou 8 bits de comprimento: 1) esi/si (registro de índice de origem) - índice de origem. Este registro em operações de cadeia contém o endereço atual do elemento na cadeia de origem; 2) edi/di (registro de índice de destino) - índice do receptor (destinatário). Este registrador em operações de cadeia contém o endereço atual na cadeia de destino. Na arquitetura do microprocessador no nível de hardware e software, uma estrutura de dados como uma pilha é suportada. Para trabalhar com a pilha no sistema de instruções do microprocessador, existem comandos especiais e, no modelo de software do microprocessador, existem registros especiais para isso: 1) esp/sp (registrador de ponteiro de pilha) - registrador de ponteiro de pilha. Contém um ponteiro para o topo da pilha no segmento de pilha atual. 2) ebp/bp (registrador de ponteiro de base) - registrador de ponteiro de base de quadro de pilha. Projetado para organizar o acesso aleatório aos dados dentro da pilha. O uso de hard pining de registradores para algumas instruções permite que sua representação de máquina seja codificada de forma mais compacta. Conhecer esses recursos, se necessário, economizará pelo menos alguns bytes de memória ocupados pelo código do programa. 41. Registros de segmento Existem seis registradores de segmento no modelo de software do microprocessador: cs, ss, ds, es, gs, fs. Sua existência se deve às especificidades da organização e uso da RAM pelos microprocessadores Intel. Está no fato de que o hardware do microprocessador suporta a organização estrutural do programa na forma de três partes, chamadas de segmentos. Assim, tal organização de memória é chamada de segmentada. A fim de indicar os segmentos aos quais o programa tem acesso em um determinado momento, são pretendidos os registradores de segmento. De fato (com uma pequena correção) esses registradores contêm os endereços de memória a partir dos quais os segmentos correspondentes começam. A lógica de processamento de uma instrução de máquina é construída de tal forma que ao buscar uma instrução, acessar dados do programa ou acessar a pilha, endereços em registradores de segmento bem definidos são usados implicitamente. O microprocessador suporta os seguintes tipos de segmentos. 1. Segmento de código. Contém comandos do programa. Para acessar este segmento, é utilizado o registrador cs (registro de segmento de código) - o registrador de código de segmento. Ele contém o endereço do segmento com instruções de máquina às quais o microprocessador tem acesso (ou seja, essas instruções são carregadas no pipeline do microprocessador). 2. Segmento de dados. Contém os dados processados pelo programa. Para acessar este segmento, é utilizado o registro ds (registro de segmento de dados) - um registro de dados de segmento que armazena o endereço do segmento de dados do programa atual. 3. Empilhe o segmento. Este segmento é uma região da memória chamada pilha. O microprocessador organiza o trabalho com a pilha de acordo com o seguinte princípio: o último elemento escrito nesta área é selecionado primeiro. Para acessar este segmento, é usado o registrador ss (stack segment register) - o registrador de segmento de pilha que contém o endereço do segmento de pilha. 4. Segmento de dados adicional. Implicitamente, os algoritmos para executar a maioria das instruções de máquina assumem que os dados que processam estão localizados no segmento de dados, cujo endereço está no registrador do segmento ds. Se o programa não tiver um segmento de dados suficiente, ele terá a oportunidade de usar mais três segmentos de dados adicionais. Mas, diferentemente do segmento de dados principal, cujo endereço está contido no registrador de segmento ds, ao usar segmentos de dados adicionais, seus endereços devem ser especificados explicitamente usando prefixos especiais de redefinição de segmento no comando. Endereços de segmentos de dados adicionais devem estar contidos nos registros es, gs, fs (registros de segmentos de dados de extensão). 42. Registros de status e controle O microprocessador inclui vários registradores que contêm constantemente informações sobre o estado do próprio microprocessador e do programa cujas instruções estão atualmente carregadas no pipeline. Esses registros incluem: 1) bandeiras/bandeiras de registro de bandeiras; 2) registro de ponteiro de comando eip/ip. Usando esses registradores, você pode obter informações sobre os resultados da execução do comando e influenciar o estado do próprio microprocessador. Vamos considerar com mais detalhes a finalidade e o conteúdo desses registros. 1. eflags/flags (registro de bandeira) - registro de bandeira. A profundidade de bits de eflags/flags é de 32/16 bits. Bits individuais deste registrador têm um propósito funcional específico e são chamados de sinalizadores. A parte inferior deste registro é completamente análoga ao registro de flags para i8086. Dependendo de como são utilizadas, as bandeiras do registro eflags/flags podem ser divididas em três grupos: 1) oito sinalizadores de status. Esses sinalizadores podem mudar após a execução das instruções de máquina. Os flags de status do registrador eflags refletem as especificidades do resultado da execução de operações aritméticas ou lógicas. Isso torna possível analisar o estado do processo computacional e responder a ele usando comandos de salto condicionais e chamadas de sub-rotinas. 2) uma bandeira de controle. Denotado df (Sinalizador de Diretório). Ele está localizado no bit 10 do registrador eflags e é usado por comandos encadeados. O valor do sinalizador df determina a direção do processamento elemento a elemento nestas operações: do início da string ao final (df = 0) ou vice-versa, do final da string ao seu início (df = 1). Existem comandos especiais para trabalhar com o sinalizador df: cld (remover o sinalizador df) e std (definir o sinalizador df). O uso desses comandos permite ajustar o sinalizador df de acordo com o algoritmo e garantir que os contadores sejam incrementados ou decrementados automaticamente ao realizar operações em strings. 3) cinco sinalizadores do sistema. Controla E/S, interrupções mascaráveis, depuração, alternância de tarefas e modo virtual 8086. Não é recomendado que programas aplicativos modifiquem esses sinalizadores desnecessariamente, pois isso fará com que o programa seja encerrado na maioria dos casos. 2. eip/ip (registrador de ponteiro de instrução) - registrador de ponteiro de instrução. O registrador eip/ip tem 32/16 bits de largura e contém o deslocamento da próxima instrução a ser executada em relação ao conteúdo do registrador de segmento cs no segmento de instrução atual. Esse registrador não é acessível diretamente ao programador, mas seu valor é carregado e alterado por vários comandos de controle, que incluem comandos para saltos condicionais e incondicionais, chamada de procedimentos e retorno de procedimentos. A ocorrência de interrupções também modifica o registrador eip/ip. 43. Registros do sistema microprocessado O próprio nome desses registradores sugere que eles desempenham funções específicas no sistema. O uso de registros do sistema é estritamente regulamentado. São eles que fornecem o modo protegido. Eles também podem ser considerados como parte da arquitetura do microprocessador, que é deliberadamente deixado visível para que um programador de sistema qualificado possa executar as operações de nível mais baixo. Os registradores do sistema podem ser divididos em três grupos: 1) quatro registros de controle; O grupo de registros de controle inclui 4 registros: ▪ cr0; ▪ cr1; ▪ cr2; ▪ cr3; 2) quatro registradores de endereço do sistema (também chamados de registradores de gerenciamento de memória); Os registros de endereço do sistema incluem os seguintes registros: ▪ registro de tabela de descritores globais gdtr; ▪ registro da tabela de descritores locais Idtr; ▪ registro da tabela do descritor de interrupção idtr; ▪ registrador de tarefas tr de 16 bits; 3) oito registradores de depuração. Esses incluem: ▪ dr0; ▪ dr1; ▪ dr2; ▪ dr3; ▪ dr4; ▪ dr5; ▪ dr6; ▪ dr7. O conhecimento dos registradores do sistema não é necessário para escrever programas em Assembler, pois eles são usados principalmente para operações de nível mais baixo. No entanto, as tendências atuais no desenvolvimento de software (especialmente à luz dos recursos de otimização significativamente aumentados dos compiladores modernos de linguagens de alto nível, que geralmente geram código com eficiência superior ao código humano) estão estreitando o escopo do Assembler para resolver os problemas mais baixos. problemas de nível hierárquico, onde o conhecimento dos registradores acima pode ser muito útil. 44. Registros de controle O grupo de registros de controle inclui quatro registros: cr0, cr1, cr2, cr3. Esses registradores são para controle geral do sistema. Os registros de controle estão disponíveis apenas para programas com nível de privilégio 0. Embora o microprocessador tenha quatro registros de controle, apenas três deles estão disponíveis - cr1 é excluído, cujas funções ainda não estão definidas (está reservada para uso futuro). O registrador cr0 contém sinalizadores do sistema que controlam os modos de operação do microprocessador e refletem seu estado globalmente, independentemente das tarefas específicas que estão sendo executadas. Objetivo dos sinalizadores do sistema: 1) pe (Protect Enable), bit 0 - habilita o modo protegido. O estado desse sinalizador indica em qual dos dois modos - real (pe = 0) ou protegido (pe = 1) - o microprocessador está operando em um determinado momento; 2) mp (Math Present), bit 1 - a presença de um coprocessador. Sempre 1; 3) ts (Task Switched), bit 3 - alternância de tarefas. O processador define esse bit automaticamente quando alterna para outra tarefa; 4) am (Máscara de Alinhamento), bit 18 - máscara de alinhamento. Este bit habilita (am = 1) ou desabilita (am = 0) o controle de alinhamento; 5) cd (Cache Disable), bit 30 - desabilita a memória cache. Usando este bit, você pode desabilitar (cd = 1) ou habilitar (cd = 0) o uso do cache interno (o cache de primeiro nível); 6) pg (PaGing), bit 31 - habilitar (pg = 1) ou desabilitar (pg = 0) paginação. O sinalizador é usado no modelo de paginação de organização de memória. O registrador cr2 é usado na paginação da RAM para registrar a situação em que a instrução atual acessou o endereço contido em uma página de memória que atualmente não está na memória. Em tal situação, uma exceção número 14 ocorre no microprocessador e o endereço linear de 32 bits da instrução que causou essa exceção é escrito no registrador cr2. Com esta informação, o manipulador de exceção 14 determina a página desejada, troca-a na memória e retoma a operação normal do programa; O registrador cr3 também é usado para paginar a memória. Este é o chamado registro de diretório de páginas de primeiro nível. Ele contém o endereço base físico de 20 bits do diretório de páginas da tarefa atual. Este diretório contém 1024 descritores de 32 bits, cada um dos quais contém o endereço da tabela de páginas de segundo nível. Por sua vez, cada uma das tabelas de página de segundo nível contém 1024 descritores de 32 bits que endereçam quadros de página na memória. O tamanho do quadro de página é de 4 KB. 45. Registros de endereços do sistema Esses registradores também são chamados de registradores de gerenciamento de memória. Eles são projetados para proteger programas e dados no modo multitarefa do microprocessador. Ao operar no modo protegido por microprocessador, o espaço de endereço é dividido em: 1) global - comum a todas as tarefas; 2) local - separado para cada tarefa. Essa separação explica a presença dos seguintes registros de sistema na arquitetura do microprocessador: 1) o registrador da tabela global de descritores gdtr (Global Descriptor Table Register), com tamanho de 48 bits e contendo um endereço base de 32 bits (bits 16-47) da tabela global de descritores GDT e um endereço base de 16 bits (bits 0-15) XNUMX-XNUMX) valor limite, que é o tamanho em bytes da tabela GDT; 2) o registrador de tabela de descritores local ldtr (Registro de Tabela de Descritores Local), que possui um tamanho de 16 bits e contém o chamado seletor de descritores da tabela de descritores locais LDT. Este seletor é um ponteiro para o GDT que descreve o segmento que contém a tabela de descritores locais LDT; 3) o registro da tabela de descritores de interrupção idtr (Interrupt Descriptor Table Register), tendo um tamanho de 48 bits e contendo um endereço base de 32 bits (bits 16-47) da tabela de descritores de interrupção IDT e um endereço de 16 bits (bits 0-15) valor limite, que é o tamanho em bytes da tabela IDT; 4) registrador de tarefa de 16 bits tr (Task Register), que, como o registrador ldtr, contém um seletor, ou seja, um ponteiro para um descritor na tabela GDT. Este descritor descreve o Status do Segmento de Tarefa (TSS) atual. Este segmento é criado para cada tarefa no sistema, possui uma estrutura estritamente regulada e contém o contexto (estado atual) da tarefa. O principal objetivo dos segmentos TSS é salvar o estado atual de uma tarefa no momento de alternar para outra tarefa. 46. Registros de depuração Este é um grupo muito interessante de registradores destinados à depuração de hardware. As ferramentas de depuração de hardware apareceram pela primeira vez no microprocessador i486. Em hardware, o microprocessador contém oito registradores de depuração, mas apenas seis deles são realmente usados. Os registros dr0, dr1, dr2, dr3 têm largura de 32 bits e são projetados para definir endereços lineares de quatro pontos de interrupção. O mecanismo utilizado neste caso é o seguinte: qualquer endereço gerado pelo programa atual é comparado com os endereços dos registradores dr0... dr3, e se houver correspondência, é gerada uma exceção de depuração com número 1. O registro dr6 é chamado de registro de status de depuração. Os bits neste registro são definidos de acordo com os motivos que causaram a ocorrência da última exceção número 1. Listamos esses bits e sua finalidade: 1) b0 - se este bit estiver em 1, então a última exceção (interrupção) ocorreu como resultado de atingir o checkpoint definido no registro dr0; 2) b1 - semelhante a b0, mas para um checkpoint no registro dr1; 3) b2 - semelhante a b0, mas para um checkpoint no registro dr2; 4) b3 - semelhante a b0, mas para um checkpoint no registro dr3; 5) bd (bit 13) - serve para proteger os registradores de depuração; 6) bs (bit 14) - definido como 1 se a exceção 1 foi causada pelo estado da flag tf = 1 no registrador eflags; 7) bt (bit 15) é definido como 1 se a exceção 1 foi causada por uma mudança para uma tarefa com o bit trap definido no TSS t = 1. Todos os outros bits neste registro são preenchidos com zeros. O manipulador de exceção 1, com base no conteúdo de dr6, deve determinar o motivo da ocorrência da exceção e tomar as ações necessárias. O registro dr7 é chamado de registro de controle de depuração. Ele contém campos para cada um dos quatro registradores de ponto de interrupção de depuração que permitem especificar as seguintes condições sob as quais uma interrupção deve ser gerada: 1) local de registro do checkpoint - apenas na tarefa atual ou em qualquer tarefa. Esses bits ocupam os 8 bits inferiores do registro dr7 (2 bits para cada ponto de interrupção (na verdade, um ponto de interrupção) definido pelos registros dr0, drl, dr2, dr3, respectivamente). O primeiro bit de cada par é a chamada resolução local; configurá-lo informa ao ponto de interrupção para entrar em vigor se estiver dentro do espaço de endereço da tarefa atual. O segundo bit em cada par define a permissão global, que indica que o ponto de interrupção fornecido é válido dentro dos espaços de endereço de todas as tarefas que residem no sistema; 2) o tipo de acesso pelo qual a interrupção é iniciada: somente ao buscar um comando, ao escrever ou ao escrever/ler dados. Os bits que determinam essa natureza da ocorrência de uma interrupção estão localizados na parte superior desse registro. A maioria dos registros do sistema é acessível por meio de programação. 47. A estrutura do programa em assembler Um programa em linguagem assembly é uma coleção de blocos de memória chamados segmentos de memória. Um programa pode consistir em um ou mais desses segmentos de blocos. Cada segmento contém uma coleção de sentenças de linguagem, cada uma das quais ocupa uma linha separada de código de programa. As instruções de montagem são de quatro tipos. Comandos ou instruções que são contrapartes simbólicas das instruções de máquina. Durante o processo de tradução, as instruções de montagem são convertidas nos comandos correspondentes do conjunto de instruções do microprocessador. Uma instrução Assembler, via de regra, corresponde a uma instrução de microprocessador, o que, em geral, é típico para linguagens de baixo nível. Aqui está um exemplo de uma instrução que incrementa o número binário armazenado no registrador eax em um: Inc. ▪ macrocomandos - frases do texto do programa formatadas de uma determinada maneira, substituídas durante a transmissão por outras frases. Um exemplo de macro é a seguinte macro de fim de programa: sair da macro movex,4c00h Int 21h fim ▪ diretivas, que são instruções para o tradutor montador executar determinadas ações. As diretivas não têm contrapartida na representação da máquina; Como exemplo, aqui está a diretiva TITLE que define o título do arquivo de listagem: %TITLE "Listing 1" ▪ linhas de comentários contendo quaisquer caracteres, incluindo letras do alfabeto russo. Os comentários são ignorados pelo tradutor. Exemplo: ; esta linha é um comentário 48. Sintaxe de Montagem As frases que compõem um programa podem ser uma construção sintática correspondente a um comando, macro, diretiva ou comentário. Para que o tradutor montador os reconheça, eles devem ser formados de acordo com certas regras sintáticas. Para fazer isso, é melhor usar uma descrição formal da sintaxe da linguagem, como as regras da gramática. As maneiras mais comuns de descrever uma linguagem de programação dessa maneira são diagramas de sintaxe e formulários Backus-Naur estendidos. Ao trabalhar com diagramas de sintaxe, preste atenção à direção de passagem, indicada pelas setas. Os diagramas de sintaxe refletem a lógica do tradutor ao analisar as sentenças de entrada do programa. Caracteres válidos: 1) todas as letras latinas: A - Z, a - z; 2) números de 0 a 9; 3) sinais? @, $, &; 4) separadores. Os tokens são os seguintes. 1. Identificadores - sequências de caracteres válidos usados para designar códigos de operação, nomes de variáveis e nomes de rótulos. Um identificador não pode começar com um número. 2. Cadeias de caracteres - sequências de caracteres entre aspas simples ou duplas. 3. Números inteiros. Possíveis tipos de instruções do montador. 1. Operadores aritméticos. Esses incluem: 1) unário "+" e "-"; 2) binário "+" e "-"; 3) multiplicação "*"; 4) divisão inteira "/"; 5) obtenção do restante da divisão “mod”. 2. Os operadores de deslocamento deslocam a expressão pelo número especificado de bits. 3. Os operadores de comparação (retornam "true" ou "false") são projetados para formar expressões lógicas. 4. Os operadores lógicos realizam operações bit a bit em expressões. 5. Operador de índice []. 6. O operador de redefinição de tipo ptr é usado para redefinir ou qualificar o tipo de um rótulo ou variável definido por uma expressão. 7. O operador de redefinição de segmento ":" (dois pontos) faz com que o endereço físico seja calculado em relação ao componente de segmento especificado. 8. Operador de nomenclatura do tipo de estrutura "." (ponto) também faz com que o compilador execute determinados cálculos se ocorrer em uma expressão. 9. O operador para obter o componente de segmento do endereço da expressão seg retorna o endereço físico do segmento para a expressão, que pode ser um rótulo, variável, nome de segmento, nome de grupo ou algum nome simbólico. 10. O operador para obter o deslocamento da expressão deslocamento permite obter o valor do deslocamento da expressão em bytes em relação ao início do segmento em que a expressão está definida. 49. Diretrizes de segmentação A segmentação faz parte de um mecanismo mais geral relacionado ao conceito de programação modular. Envolve a unificação do design dos módulos de objetos criados pelo compilador, incluindo aqueles de diferentes linguagens de programação. Isso permite combinar programas escritos em diferentes idiomas. É para a implementação de várias opções para tal união que se destinam os operandos da diretiva SEGMENT. Vamos considerá-los em mais detalhes. 1. O atributo de alinhamento do segmento (tipo de alinhamento) informa ao vinculador para garantir que o início do segmento seja colocado no limite especificado: 1) BYTE - o alinhamento não é realizado; 2) WORD - o segmento inicia em um endereço que é múltiplo de dois, ou seja, o último (menos significativo) bit do endereço físico é 0 (alinhado ao limite da palavra); 3) DWORD - o segmento inicia em um endereço múltiplo de quatro; 4) PARA - o segmento inicia em um endereço múltiplo de 16; 5) PAGE - o segmento inicia em um endereço múltiplo de 256; 6) MEMPAGE - o segmento inicia em um endereço múltiplo de 4 KB. 2. O atributo combine segment (tipo combinatório) informa ao vinculador como combinar segmentos de módulos diferentes que têm o mesmo nome: 1) PRIVADO - o segmento não será combinado com outros segmentos de mesmo nome fora deste módulo; 2) PÚBLICO - força o linker a conectar todos os segmentos com o mesmo nome; 3) COMUM - tem todos os segmentos com o mesmo nome no mesmo endereço; 4) AT xxxx - localiza o segmento no endereço absoluto do parágrafo; 5) PILHA - definição de um segmento de pilha. 3. Um atributo de classe de segmento (tipo de classe) é uma string entre aspas que ajuda o vinculador a determinar a ordem de segmento apropriada ao montar um programa a partir de vários segmentos de módulo. 4. Atributo de tamanho do segmento: 1) USE16 - significa que o segmento permite endereçamento de 16 bits; 2) USE32 - o segmento será de 32 bits. Tem que haver alguma forma de compensar a impossibilidade. controlar diretamente o posicionamento e a combinação de segmentos. Para fazer isso, eles começaram a usar a diretiva para especificar o modelo de memória MODEL. Esta diretiva vincula segmentos, que no caso de usar diretivas de segmentação simplificadas, têm nomes predefinidos, com registradores de segmento (embora você ainda precise inicializar ds explicitamente). O parâmetro obrigatório da diretiva MODEL é o modelo de memória. Este parâmetro define o modelo de segmentação de memória para a POU. Supõe-se que um módulo de programa pode ter apenas certos tipos de segmentos, que são definidos pelas diretivas simplificadas de descrição de segmento que mencionamos anteriormente. 50. Estrutura de instrução da máquina Um comando de máquina é uma indicação ao microprocessador, codificado de acordo com certas regras, para realizar alguma operação ou ação. Cada comando contém elementos que definem: 1) o que fazer? 2) objetos sobre os quais algo precisa ser feito (esses elementos são chamados de operandos); 3) como fazer? O comprimento máximo de uma instrução de máquina é de 15 bytes. 1. Prefixos. Elementos de instrução de máquina opcionais, cada um dos quais é de 1 byte ou pode ser omitido. Na memória, os prefixos precedem o comando. A finalidade dos prefixos é modificar a operação realizada pelo comando. Um aplicativo pode usar os seguintes tipos de prefixos: 1) prefixo de substituição de segmento; 2) o prefixo de comprimento de bit de endereço especifica o comprimento de bit do endereço (32 bits ou 16 bits); 3) o prefixo da largura do bit do operando é semelhante ao prefixo da largura do bit do endereço, mas indica o comprimento do bit do operando (32 ou 16 bits) com o qual o comando trabalha; 4) O prefixo de repetição é usado com comandos encadeados. 2. Código de operação. Elemento obrigatório que descreve a operação realizada pelo comando. 3. Modo de endereçamento byte modr/m. O valor deste byte determina a forma de endereço do operando utilizada. Os operandos podem estar na memória em um ou dois registradores. Se o operando estiver na memória, o byte modr/m especifica os componentes (registros de deslocamento, base e índice) usado para calcular seu endereço efetivo. O byte modr/m consiste em três campos: 1) o campo mod determina o número de bytes ocupados na instrução pelo endereço do operando; 2) o campo reg/cop determina ou o registrador localizado no comando no lugar do primeiro operando, ou uma possível extensão do opcode; 3) o campo r/m é usado em conjunto com o campo mod e determina o registrador localizado no comando no local do primeiro operando (se mod = 11), ou os registradores base e índice usados para calcular o endereço efetivo ( juntamente com o campo de deslocamento no comando). 4. Escala de bytes - índice - base (byte sib). Usado para expandir as possibilidades de endereçamento de operandos. O byte sib consiste em três campos: 1) campos de escala ss. Este campo contém o fator de escala para o índice do componente index, que ocupa os próximos 3 bits do byte sib; 2) campos de índice. Usado para armazenar o número do registro de índice que é usado para calcular o endereço efetivo do operando; 3) campos de base. Usado para armazenar o número do registrador base, que também é usado para calcular o endereço efetivo do operando. 5. Campo de deslocamento no comando. Um inteiro com sinal de 8, 16 ou 32 bits que representa, no todo ou em parte (sujeito às considerações acima), o valor do endereço efetivo do operando. 6. O campo do operando imediato. Um campo opcional representando 8-, Operando imediato de 16 ou 32 bits. A presença deste campo é, obviamente, refletida no valor do byte modr/m. 51. Métodos para especificar operandos de instrução O operando é definido implicitamente no nível de firmware Nesse caso, a instrução explicitamente não contém operandos. O algoritmo de execução do comando usa alguns objetos padrão (registros, sinalizadores em eflags, etc.). O operando é especificado na própria instrução (operando imediato) O operando está no código de instrução, ou seja, faz parte dele. Para armazenar tal operando, um campo de até 32 bits é alocado na instrução. O operando imediato só pode ser o segundo operando (origem). O operando destino pode estar na memória ou em um registrador. O operando está em um dos registradores.Os operandos de registrador são especificados pelos nomes dos registradores. Os registros podem ser usados: 1) registradores de 32 bits EAX, EBX, ECX, EDX, ESI, EDI, ESP, EBP; 2) registradores de 16 bits AX, BX, CX, DX, SI, DI, SP, BP; 3) registradores de 8 bits AH, AL, BH, BL, CH, CL, DH, DL; 4) registradores de segmento CS, DS, SS, ES, FS, GS. Por exemplo, o comando add ax,bx adiciona o conteúdo dos registradores ax e bx e grava o resultado em bx. O comando dec si diminui o conteúdo de si em 1. O operando está na memória Esta é a maneira mais complexa e ao mesmo tempo mais flexível de especificar operandos. Ele permite que você implemente os dois tipos principais de endereçamento a seguir: direto e indireto. Por sua vez, o endereçamento indireto tem as seguintes variedades: 1) endereçamento indireto de base; seu outro nome é endereçamento indireto de registro; 2) endereçamento indireto de base com offset; 3) endereçamento de índice indireto com offset; 4) endereçamento indireto do índice base; 5) endereçamento indireto do índice base com offset. O operando é uma porta de E/S Além do espaço de endereço de RAM, o microprocessador mantém um espaço de endereço de E/S, que é usado para acessar dispositivos de E/S. O espaço de endereço de E/S é de 64 KB. Os endereços são alocados para qualquer dispositivo de computador neste espaço. Um valor de endereço específico dentro desse espaço é chamado de porta de E/S. Fisicamente, a porta de E/S corresponde a um registrador de hardware (não confundir com um registrador de microprocessador), que é acessado usando instruções de montagem especiais de entrada e saída. O operando está na pilha As instruções podem não ter nenhum operando, podem ter um ou dois operandos. A maioria das instruções requer dois operandos, um dos quais é o operando de origem e o outro é o operando de destino. É importante que um operando possa estar localizado em um registrador ou memória, e o segundo operando em um registrador ou diretamente na instrução. Um operando imediato só pode ser um operando de origem. Em uma instrução de máquina de dois operandos, as seguintes combinações de operandos são possíveis: 1) cadastro - cadastro; 2) registrador - memória; 3) memória - registro; 4) operando imediato - registrador; 5) operando imediato - memória. 52. Métodos de endereçamento Endereçamento direto Esta é a forma mais simples de endereçar um operando na memória, pois o endereço efetivo está contido na própria instrução e nenhuma fonte ou registrador adicional é usado para formá-lo. O endereço efetivo é obtido diretamente do campo de deslocamento da instrução de máquina, que pode ser de 8, 16, 32 bits. Esse valor identifica exclusivamente o byte, palavra ou palavra dupla localizada no segmento de dados. O endereçamento direto pode ser de dois tipos. Endereçamento direto relativo Usado para instruções de salto condicional para indicar o endereço de salto relativo. A relatividade de tal transição reside no fato de que o campo de deslocamento da instrução de máquina contém um valor de 8, 16 ou 32 bits, que, como resultado da operação da instrução, será adicionado ao conteúdo da instrução de máquina. o registrador de ponteiro de instrução ip/eip. Como resultado desta adição, é obtido o endereço para o qual a transição é realizada. Endereçamento direto absoluto Neste caso, o endereço efetivo faz parte da instrução de máquina, mas este endereço é formado apenas a partir do valor do campo offset na instrução. Para formar o endereço físico do operando na memória, o microprocessador soma este campo com o valor do registrador de segmento deslocado em 4 bits. Várias formas deste endereçamento podem ser usadas em uma instrução assembler. Endereçamento básico indireto (registro) Com este endereçamento, o endereço efetivo do operando pode estar em qualquer um dos registradores de uso geral, exceto sp/esp e bp/ebp (estes são registradores específicos para trabalhar com um segmento de pilha). Sintaticamente em um comando, este modo de endereçamento é expresso colocando o nome do registrador entre colchetes []. Endereçamento indireto de base (registro) com offset Este tipo de endereçamento é uma adição ao anterior e é projetado para acessar dados com um deslocamento conhecido em relação a algum endereço base. Este tipo de endereçamento é conveniente para acessar os elementos das estruturas de dados, quando o deslocamento dos elementos é conhecido antecipadamente, na fase de desenvolvimento do programa, e o endereço base (inicial) da estrutura deve ser calculado dinamicamente, no a fase de execução do programa. Endereçamento de índice indireto com deslocamento Este tipo de endereçamento é muito semelhante ao endereçamento de base indireto com deslocamento. Aqui, também, um dos registradores de uso geral é usado para formar o endereço efetivo. Mas o endereçamento de índice tem um recurso interessante que é muito conveniente para trabalhar com arrays. Ele está conectado com a possibilidade do chamado dimensionamento do conteúdo do registro de índice. Endereçamento de índice base indireto Com este tipo de endereçamento, o endereço efetivo é formado pela soma do conteúdo de dois registradores de uso geral: base e índice. Esses registradores podem ser quaisquer registradores de uso geral, e o dimensionamento do conteúdo de um registrador de índice é frequentemente usado. Endereçamento de índice base indireto com deslocamento Este tipo de endereçamento é o complemento do endereçamento indexado indireto. O endereço efetivo é formado pela soma de três componentes: o conteúdo do registrador base, o conteúdo do registrador de índice e o valor do campo de deslocamento no comando. 53. Comandos de transferência de dados Comandos gerais de transferência de dados Este grupo inclui os seguintes comandos: 1) mov é o principal comando de transferência de dados; 2) xchg - usado para transferência de dados bidirecional. Comandos de E/S da porta Fundamentalmente, é fácil gerenciar dispositivos diretamente por meio de portas: 1) no acumulador, número da porta - entrada no acumulador da porta com o número da porta; 2) porta de saída, acumulador - envia o conteúdo do acumulador para a porta com o número da porta. Comandos de conversão de dados Muitas instruções de microprocessadores podem ser atribuídas a este grupo, mas a maioria delas possui certas características que requerem que sejam atribuídas a outros grupos funcionais. Comandos de pilha Este grupo é um conjunto de comandos especializados focados em organizar o trabalho flexível e eficiente com a pilha. A pilha é uma área de memória especialmente alocada para armazenamento temporário de dados do programa. A pilha tem três registradores: 1) ss - registrador de segmento de pilha; 2) sp/esp - registrador de ponteiro de pilha; 3) bp/ebp - registrador de ponteiro de base de quadro de pilha. Para organizar o trabalho com a pilha, existem comandos especiais para escrita e leitura. 1. push source - escrevendo o valor de origem no topo da pilha. 2. atribuição de pop - escrever o valor do topo da pilha para o local especificado pelo operando de destino. O valor é assim "removido" do topo da pilha. 3. pusha - um comando de gravação de grupo na pilha. 4. pushaw é quase sinônimo do comando pusha. O atributo bitness pode ser use16 ou use32. R 5. pushad - executado de forma semelhante ao comando pusha, mas existem algumas particularidades. Os três comandos a seguir executam o inverso dos comandos acima: 1) papa; 2) pipoca; 3) pop. O grupo de instruções descrito abaixo permite que você salve o registrador de flag na pilha e escreva uma palavra ou palavra dupla na pilha. 1. pushf - salva o registro de flags na pilha. 2. pushfw - salvando um registro de flags do tamanho de uma palavra na pilha. Sempre funciona como pushf com o atributo use16. 3. pushfd - salvando os flags ou flags eflags registrados na pilha dependendo do atributo de largura de bits do segmento (ou seja, o mesmo que pushf). Da mesma forma, os três comandos a seguir executam o inverso das operações discutidas acima: 1) popf; 2) popfw; 3) popfd. 54. Instruções aritméticas Esses comandos funcionam com dois tipos: 1) números binários inteiros, ou seja, com números codificados no sistema de numeração binário. Os números decimais são um tipo especial de representação de informações numéricas, que se baseia no princípio de codificar cada dígito decimal de um número por um grupo de quatro bits. O microprocessador realiza a adição de operandos de acordo com as regras de adição de números binários. Existem três instruções de adição binária no conjunto de instruções do microprocessador: 1) operando inc - aumenta o valor do operando; 2) adicionar operando1, operando2 - adição; 3) adc operando1, operando2 - adição, levando em consideração o carry flag cf. Subtração de números binários sem sinal Se o minuendo for maior que o subtraendo, então a diferença é positiva. Se o minuendo for menor que o subtraído, há um problema: o resultado é menor que 0, e este já é um número com sinal. Depois de subtrair números sem sinal, você precisa analisar o estado do sinalizador CF. Se for definido como 1, o bit mais significativo foi emprestado e o resultado está no código de complemento de dois. Subtração de números binários com sinal Mas para subtração por meio de adição de números com sinal em um código adicional, é necessário representar ambos os operandos - tanto o minuendo quanto o subtraendo. O resultado também deve ser tratado como um valor de complemento de dois. Mas aqui surgem as dificuldades. Em primeiro lugar, eles estão relacionados ao fato de que o bit mais significativo do operando é considerado um bit de sinal. De acordo com o conteúdo do sinalizador de estouro de. Defini-lo como 1 indica que o resultado está fora do intervalo de números com sinal (ou seja, o bit mais significativo foi alterado) para um operando desse tamanho e o programador deve tomar medidas para corrigir o resultado. O princípio de subtração de números com uma faixa de representação que excede as grades de bits padrão dos operandos é o mesmo da adição, ou seja, o sinalizador de transporte cf é usado. Você só precisa imaginar o processo de subtração em uma coluna e combinar corretamente as instruções do microprocessador com a instrução sbb. O comando para multiplicar números sem sinal é mul fator_1 O comando para multiplicar números com um sinal é [imul operando_1, operando_2, operando_3] O comando div divisor é para dividir números não assinados. O comando idiv divisor é para dividir números com sinal. 55. Comandos lógicos De acordo com a teoria, as seguintes operações lógicas podem ser executadas em instruções (em bits). 1. Negação (NOT lógico) - uma operação lógica em um operando, cujo resultado é o recíproco do valor do operando original. 2. Adição lógica (OR inclusivo lógico) - uma operação lógica em dois operandos, cujo resultado é "verdadeiro" (1) se um ou ambos os operandos forem verdadeiros (1), e "falso" (0) se ambos os operandos forem falso (0). 3. Multiplicação lógica (AND lógico) - uma operação lógica em dois operandos, cujo resultado é verdadeiro (1) somente se ambos os operandos forem verdadeiros (1). Em todos os outros casos, o valor da operação é "false" (0). 4. Adição exclusiva lógica (OR exclusivo lógico) - uma operação lógica em dois operandos, cujo resultado é "verdadeiro" (1), se apenas um dos dois operandos for verdadeiro (1), e falso (0), se ambos os operandos são falsos (0) ou verdadeiros (1). 4. Adição exclusiva lógica (OR exclusivo lógico) - uma operação lógica em dois operandos, cujo resultado é "verdadeiro" (1), se apenas um dos dois operandos for verdadeiro (1), e falso (0), se ambos os operandos são falsos (0) ou verdadeiros (1). O seguinte conjunto de comandos que suportam trabalhar com dados lógicos: 1) e operando_1, operando_2 - operação lógica de multiplicação; 2) ou operando_1, operando_2 - operação lógica de adição; 3) xor operando_1, operando_2 - operação de adição lógica exclusiva; 4) test operando_1, operando_2 - operação "teste" (por multiplicação lógica) 5) não operando - operação de negação lógica. a) para definir determinados dígitos (bits) para 1, é usado o comando ou operando_1, operando_2; b) para redefinir determinados dígitos (bits) para 0, utiliza-se o comando e operando_1, operando_2; c) comando xor operando_1, operando_2 é aplicado: ▪ descobrir quais bits no operando_1 e no operando_2 são diferentes; ▪ inverter o estado dos bits especificados em operando_1. O comando test operando_1, operando_2 (verificar operando_1) é utilizado para verificar o estado dos bits especificados. O resultado do comando é definir o valor do sinalizador zero zf: 1) se zf = 0, então, como resultado da multiplicação lógica, obteve-se um resultado zero, ou seja, um bit unitário da máscara, que não correspondeu ao bit unitário correspondente do operando1; 2) se zf = 1, então a multiplicação lógica resultou em um resultado diferente de zero, ou seja, pelo menos um bit unitário da máscara coincidiu com o bit correspondente do operando1. Todas as instruções de deslocamento movem bits no campo do operando para a esquerda ou para a direita, dependendo do código de operação. Todas as instruções de deslocamento têm a mesma estrutura - operando policial, contador de deslocamento. 56. Comandos de Transferência de Controle Qual instrução de programa deve ser executada em seguida, o microprocessador aprende com o conteúdo do cs: (e) par de registradores ip: 1) cs - registrador de segmento de código, que contém o endereço físico do segmento de código atual; 2) eip/ip - registrador de ponteiro de instrução, contém o valor de offset na memória da próxima instrução a ser executada. Saltos incondicionais O que precisa ser modificado depende de: 1) sobre o tipo de operando na instrução de desvio incondicional (próximo ou distante); 2) de especificar um modificador antes do endereço de transição; neste caso, o próprio endereço de salto pode estar diretamente na instrução (salto direto) ou em um registrador de memória (salto indireto). Valores do modificador: 1) near ptr - transição direta para o rótulo; 2) far ptr - transição direta para um rótulo em outro segmento de código; 3) palavra ptr - transição indireta para o rótulo; 4) dword ptr - transição indireta para um rótulo em outro segmento de código. jmp instrução de salto incondicional jmp [modificador] jump_address Um procedimento ou sub-rotina é a unidade funcional básica da decomposição de alguma tarefa. Um procedimento é um grupo de comandos. Saltos condicionais O microprocessador possui 18 instruções de salto condicional. Esses comandos permitem que você verifique: 1) a relação entre operandos assinados (“mais é menos”); 2) relação entre operandos sem sinal ("superior inferior"); 3) estados das bandeiras aritméticas ZF, SF, CF, OF, PF (mas não AF). As instruções de salto condicional têm a mesma sintaxe: jcc jump label O comando cmp compare tem uma maneira interessante de funcionar. É exatamente o mesmo que o comando de subtração - sub operando_1, operando_2. O comando cmp, como o subcomando, subtrai operandos e define sinalizadores. A única coisa que não faz é escrever o resultado da subtração no lugar do primeiro operando. A sintaxe do comando cmp - cmp operando_1, operando_2 (comparar) - compara dois operandos e define sinalizadores com base nos resultados da comparação. Organização de ciclos Você pode organizar a execução cíclica de uma determinada seção do programa, por exemplo, usando a transferência condicional de comandos de controle ou o comando de salto incondicional jmp: 1) rótulo de transição de loop (Loop) - repita o loop. O comando permite organizar loops semelhantes aos for loops em linguagens de alto nível com decremento automático do contador de loops; 2) etiqueta de salto loope/loopz Os comandos loope e loopz são sinônimos absolutos; 3) etiqueta de salto loopne/loopnz Os comandos loopne e loopnz também são sinônimos absolutos. Os comandos loope/loopz e loopne/loopnz são recíprocos em sua operação. Autor: Tsvetkova A.V.
▪ Traumatologia e ortopedia. Notas de aula
Couro artificial para emulação de toque
15.04.2024 Areia para gatos Petgugu Global
15.04.2024 A atratividade de homens atenciosos
14.04.2024
▪ Armazenamento SSD de 12 TB AKITiO Thunder2 Quad Mini ▪ Iogurtes são bons para o coração e a saúde vascular ▪ Quebrando o recorde de comprimento de uma linha de comunicação quântica ▪ Salsa por mil euros por cacho
▪ seção do site para o designer de rádio amador. Seleção de artigos ▪ artigo Ri melhor quem ri por último. expressão popular ▪ artigo Quantos magos vieram adorar Jesus? Resposta detalhada
Página principal | Biblioteca | Artigos | Mapa do Site | Revisões do site
www.diagrama.com.ua |


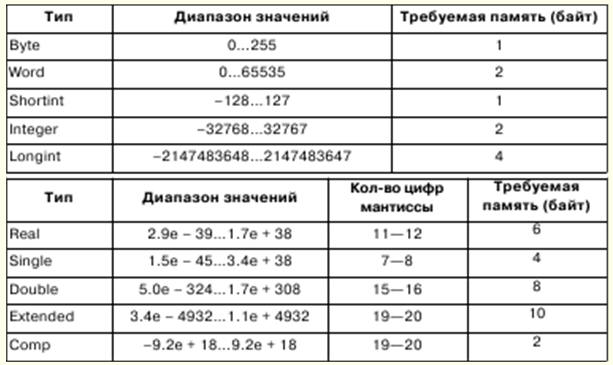

 Veja outros artigos seção
Veja outros artigos seção 