|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese|
RESUMO DA AULA, CRIBS
Base de dados. Notas de aula: resumidamente, o mais importante
Diretório / Notas de aula, folhas de dicas Índice analítico
Aula No. 1. Introdução 1. Sistemas de gerenciamento de banco de dados Sistemas de gerenciamento de banco de dados (DBMS) são produtos de software especializados que permitem: 1) armazenar permanentemente grandes quantidades de dados arbitrariamente grandes (mas não infinitas); 2) extrair e modificar esses dados armazenados de uma forma ou de outra, usando as chamadas consultas; 3) criar novos bancos de dados, ou seja, descrever estruturas lógicas de dados e definir sua estrutura, ou seja, fornecer uma interface de programação; 4) acessar dados armazenados por vários usuários ao mesmo tempo (ou seja, fornecer acesso ao mecanismo de gerenciamento de transações). Por conseguinte, o bases de dados são conjuntos de dados sob o controle de sistemas de gerenciamento. Agora, os sistemas de gerenciamento de banco de dados são os produtos de software mais complexos do mercado e formam sua base. No futuro, está planejado realizar desenvolvimentos em uma combinação de sistemas convencionais de gerenciamento de banco de dados com programação orientada a objetos (OOP) e tecnologias da Internet. Inicialmente, os SGBDs eram baseados em hierárquico и modelos de dados de rede, ou seja, permitido trabalhar apenas com estruturas de árvore e grafos. Em processo de desenvolvimento em 1970, havia sistemas de gerenciamento de banco de dados propostos por Codd (Codd), baseados em modelo de dados relacional. 2. Bancos de dados relacionais O termo "relacional" vem da palavra inglesa "relation" - "relationship". No sentido matemático mais geral (como pode ser lembrado do curso clássico de álgebra de conjuntos) atitudes - é um conjunto R = {(x1,...,xn) | x1 ∈ UMA1,...,xn ∈ An}, onde um1,...,An são os conjuntos que formam o produto cartesiano. Nesse caminho, razão R é um subconjunto do produto cartesiano de conjuntos: A1 x... xAn : R ⊆ UMA 1 x... xAn. Por exemplo, considere relações binárias de ordem estrita "maior que" e "menor que" no conjunto de pares ordenados de números A 1 = A2 = {3, 4, 5}: R> = {(3, 4), (4, 5), (3, 5)} ⊂ A1 xA2; R< = {(5, 4), (4, 3), (5, 3)} ⊂ UMA1 xA2. Esses relacionamentos podem ser apresentados na forma de tabelas. Razão "maior que">:
Razão "menor que" R<:
Assim, vemos que nos bancos de dados relacionais, uma grande variedade de dados é organizada na forma de relacionamentos e pode ser apresentada na forma de tabelas. Deve-se notar que essas duas relações R> e R< não são equivalentes entre si, ou seja, as tabelas correspondentes a essas relações não são iguais entre si. Assim, as formas de representação de dados em bancos de dados relacionais podem ser diferentes. Como essa possibilidade de representação diferente se manifesta em nosso caso? Relações R> e R< - estes são conjuntos, e um conjunto é uma estrutura não ordenada, o que significa que nas tabelas correspondentes a esses relacionamentos, as linhas podem ser trocadas. Mas, ao mesmo tempo, os elementos desses conjuntos são conjuntos ordenados, no nosso caso - pares ordenados de números 3, 4, 5, o que significa que as colunas não podem ser trocadas. Assim, mostramos que a representação de uma relação (no sentido matemático) na forma de uma tabela com uma ordem arbitrária de linhas e um número fixo de colunas é uma forma aceitável e correta de representação de relações. Mas se considerarmos as relações R> e R< do ponto de vista das informações neles embutidas, é claro que são equivalentes. Portanto, em bancos de dados relacionais, o conceito de "relacionamento" tem um significado ligeiramente diferente do que a relação na matemática geral. Ou seja, não está relacionado à ordenação por colunas em uma forma de apresentação tabular. Em vez disso, os chamados esquemas de relacionamento "linha - cabeçalho de coluna" são introduzidos, ou seja, cada coluna recebe um cabeçalho, após o qual elas podem ser trocadas livremente. É assim que nosso relacionamento R será> e R< em um banco de dados relacional. Uma relação de ordem estrita (em vez da relação R>):
Uma relação de ordem estrita (em vez da relação R<):
Ambas as relações de tabelas recebem uma nova (neste caso, a mesma, pois ao introduzir cabeçalhos adicionais apagamos as diferenças entre as relações R> e R<) título. Então, vemos que com a ajuda de um truque tão simples como adicionar os cabeçalhos necessários às tabelas, chegamos à conclusão de que as relações R> e R< tornam-se equivalentes entre si. Assim, concluímos que o conceito de "relacionamento" no sentido geral matemático e relacional não coincide completamente, eles não são idênticos. Atualmente, os sistemas de gerenciamento de banco de dados relacional formam a base do mercado de tecnologia da informação. Mais pesquisas estão sendo conduzidas na direção de combinar vários graus do modelo relacional. Aula nº 2. Dados ausentes Dois tipos de valores são descritos em sistemas de gerenciamento de banco de dados para detectar dados ausentes: vazios (ou valores vazios) e indefinidos (ou valores nulos). Em algumas literaturas (principalmente comerciais), os valores nulos às vezes são chamados de valores vazios ou nulos, mas isso é incorreto. O significado dos significados vazio e indefinido é fundamentalmente diferente, por isso é necessário monitorar cuidadosamente o contexto de uso de um determinado termo. 1. Valores vazios (Valores vazios) valor vazio é simplesmente um dos muitos valores possíveis para algum tipo de dado bem definido. Listamos os mais "naturais", imediatos valores vazios (ou seja, valores vazios que poderíamos alocar por conta própria sem ter nenhuma informação adicional): 1) 0 (zero) - valor nulo está vazio para tipos de dados numéricos; 2) false (errado) - é um valor vazio para um tipo de dado booleano; 3) B'' - cadeia de bits vazia para cadeias de comprimento variável; 4) "" - string vazia para strings de caracteres de comprimento variável. Nos casos acima, você pode determinar se um valor é nulo ou não comparando o valor existente com a constante nula definida para cada tipo de dados. Mas os sistemas de gerenciamento de banco de dados, devido aos esquemas implementados neles para armazenamento de dados de longo prazo, só podem funcionar com strings de comprimento constante. Por causa disso, uma sequência vazia de bits pode ser chamada de sequência de zeros binários. Ou uma string consistindo de espaços ou qualquer outro caractere de controle é uma string vazia de caracteres. Aqui estão alguns exemplos de strings vazias de comprimento constante: 1) B'0'; 2) B'000'; 3)''. Como você pode saber se uma string está vazia nesses casos? Em sistemas de gerenciamento de banco de dados, uma função lógica é usada para testar a vacuidade, ou seja, o predicado IsEmpty(<expressão>), que literalmente significa "comer vazio". Esse predicado geralmente é incorporado ao sistema de gerenciamento de banco de dados e pode ser aplicado a qualquer tipo de expressão. Se não houver tal predicado em sistemas de gerenciamento de banco de dados, você mesmo poderá escrever uma função lógica e incluí-la na lista de objetos do banco de dados que está sendo projetado. Considere outro exemplo em que não é tão fácil determinar se temos um valor vazio. Dados do tipo data. Qual valor neste tipo deve ser considerado um valor vazio se a data pode variar no intervalo de 01.01.0100. antes de 31.12.9999/XNUMX/XNUMX? Para fazer isso, uma designação especial é introduzida no SGBD para constantes de data vazias {...}, se o valor desse tipo for escrito: {DD. MILÍMETROS. AA} ou {AA. MILÍMETROS. DD}. Com este valor, ocorre uma comparação ao verificar o valor de vazio. É considerado um valor "completo" bem definido de uma expressão desse tipo e o menor possível. Ao trabalhar com bancos de dados, os valores nulos costumam ser usados como valores padrão ou são usados quando faltam valores de expressão. 2. Valores indefinidos (Valores nulos) Palavra Nulo usado para denotar valores indefinidos em bancos de dados. Para entender melhor quais valores são entendidos como nulos, considere uma tabela que é um fragmento de um banco de dados:
Assim, valor indefinido ou Valor nulo - isto é: 1) desconhecido, mas usual, ou seja, valor aplicável. Por exemplo, o Sr. Khairetdinov, que é o número um em nosso banco de dados, sem dúvida tem alguns dados de passaporte (como uma pessoa nascida em 1980 e um cidadão do país), mas eles não são conhecidos, portanto, não estão incluídos no banco de dados . Portanto, o valor Null será escrito na coluna correspondente da tabela; 2) valor não aplicável. O Sr. Karamazov (nº 2 em nosso banco de dados) simplesmente não pode ter nenhum dado de passaporte, porque no momento da criação deste banco de dados ou da entrada de dados nele, ele era uma criança; 3) o valor de qualquer célula da tabela, caso não possamos dizer se é aplicável ou não. Por exemplo, o Sr. Kovalenko, que ocupa a terceira posição no banco de dados compilado por nós, não sabe o ano de nascimento, então não podemos dizer com certeza se ele tem ou não os dados do passaporte. E consequentemente, os valores de duas células na linha dedicada ao Sr. Kovalenko serão Null-value (o primeiro - como desconhecido em geral, o segundo - como um valor cuja natureza é desconhecida). Como qualquer outro tipo de dados, os valores Null também possuem certas Propriedades. Listamos os mais significativos deles: 1) ao longo do tempo, a compreensão do valor Null pode mudar. Por exemplo, para o Sr. Karamazov (Nº 2 em nosso banco de dados) em 2014, ou seja, ao atingir a maioridade, o valor Nulo mudará para algum valor específico e bem definido; 2) O valor nulo pode ser atribuído a uma variável ou constante de qualquer tipo (numérico, string, booleano, data, hora, etc.); 3) o resultado de qualquer operação em expressões com valores nulos como operandos é um valor nulo; 4) uma exceção à regra anterior são as operações de conjunção e disjunção sob as condições das leis de absorção (para mais detalhes sobre as leis de absorção, ver parágrafo 4 da aula nº 2). 3. Valores nulos e a regra geral para avaliar expressões Vamos falar mais sobre ações em expressões contendo valores nulos. A regra geral para lidar com valores Nulos (que o resultado das operações em valores Nulos é um valor Nulo) se aplica às seguintes operações: 1) à aritmética; 2) às operações de negação, conjunção e disjunção bit a bit (exceto para as leis de absorção); 3) para operações com strings (por exemplo, concatenação - concatenação de strings); 4) às operações de comparação (<, ≤, ≠, ≥, >). Vamos dar exemplos. Como resultado da aplicação das seguintes operações, serão obtidos valores nulos: 3 + Nulo, 1/ Nulo, (Ivanov' + '' + Nulo) ≔ Nulo Aqui, em vez da igualdade usual, usamos operação de substituição "≔" devido à natureza especial de trabalhar com valores nulos. A seguir, este símbolo também será usado em situações semelhantes, o que significa que a expressão à direita do caractere curinga pode substituir qualquer expressão da lista à esquerda do caractere curinga. A natureza dos valores nulos geralmente resulta em algumas expressões produzindo um valor nulo em vez do nulo esperado, por exemplo: (x - x), y * (x - x), x * 0 ≔ Nulo quando x = Nulo. O fato é que ao substituir, por exemplo, na expressão (x - x) os valores x = Null, obtemos a expressão (Null - Null), e a regra geral para calcular o valor da expressão contendo valores Null entre em vigor, e a informação sobre o fato de que aqui o valor Null corresponde à mesma variável é perdida. Pode-se concluir que ao calcular quaisquer operações que não sejam booleanos, os valores nulos são interpretados como inaplicável, e, portanto, o resultado também é um valor Null. O uso de valores nulos em operações de comparação não leva a resultados menos inesperados. Por exemplo, as seguintes expressões também produzem valores nulos em vez dos valores booleanos True ou False esperados: (Nulo < Nulo); (Nulo ≤ nulo); (Nulo = Nulo); (Nulo ≠ Nulo); (Nulo > Nulo); (Nulo ≥ Nulo) ≔ Nulo; Assim, concluímos que é impossível dizer que um valor Null é igual ou não igual a si mesmo. Cada nova ocorrência de um valor Null é tratada como independente, e cada vez que os valores Null são tratados como valores desconhecidos diferentes. Nisso, os valores nulos são fundamentalmente diferentes de todos os outros tipos de dados, porque sabemos que era seguro dizer sobre todos os valores passados anteriormente e seus tipos que são iguais ou não iguais entre si. Assim, vemos que os valores Nulos não são os valores das variáveis no sentido usual da palavra. Portanto, torna-se impossível comparar os valores de variáveis ou expressões que contenham valores Null, pois como resultado receberemos não os valores booleanos True ou False, mas valores Null, como nos exemplos a seguir: (x < Nulo); (x ≤ nulo); (x=Nulo); (x ≠ Nulo); (x > Nulo); (x ≥ Nulo) ≔ Nulo; Portanto, por analogia com valores vazios, para verificar uma expressão para valores Nulos, você deve usar um predicado especial: IsNull(<expressão>), que significa literalmente "é Nulo". A função booleana retorna True se a expressão contiver Null ou for Null, e False caso contrário, mas nunca retornará Null. O predicado IsNull pode ser aplicado a variáveis e expressões de qualquer tipo. Quando aplicado a expressões do tipo vazio, o predicado sempre retornará False. Por exemplo:
Então, de fato, vemos que no primeiro caso, quando o predicado IsNull foi tirado de zero, a saída acabou sendo False. Em todos os casos, incluindo o segundo e o terceiro, quando os argumentos da função lógica eram iguais ao valor Null, e no quarto caso, quando o próprio argumento era inicialmente igual ao valor Null, o predicado retornava True. 4. Valores nulos e operações lógicas Normalmente, apenas três operações lógicas são suportadas diretamente em sistemas de gerenciamento de banco de dados: negação ¬, conjunção & e disjunção ∨. As operações de sucessão ⇒ e equivalência ⇔ são expressas em termos delas usando substituições: (x ⇒ y) ≔ (¬x ∨ y); (x ⇔ y) ≔ (x ⇒ y) & (y ⇒ x); Observe que essas substituições são totalmente preservadas ao usar valores nulos. Curiosamente, usando o operador de negação "¬" qualquer uma das operações conjunção & ou disjunção ∨ pode ser expressa uma através da outra da seguinte forma: (x & y) ≔¬ (¬x ∨¬y); (x ∨ y) ≔ ¬(¬x & ¬y); Essas substituições, assim como as anteriores, não são afetadas por valores nulos. E agora apresentamos as tabelas verdade das operações lógicas de negação, conjunção e disjunção, mas além dos habituais valores Verdadeiro e Falso, também usamos o valor Nulo como operandos. Por conveniência, introduzimos a seguinte notação: em vez de True, escreveremos t, em vez de False - f, e em vez de Null - n. 1. Negação XX.
Vale a pena notar os seguintes pontos interessantes sobre a operação de negação usando valores Null: 1) ¬¬x ≔ x - a lei da dupla negação; 2) ¬Null ≔ Null - O valor Null é um ponto fixo. 2. Conjunção x & y.
Esta operação também tem suas próprias propriedades: 1) x & y ≔ y & x - comutatividade; 2) x & x ≔ x - idempotência; 3) False & y ≔ False, aqui False é um elemento absorvente; 4) True & y ≔ y, aqui True é o elemento neutro. 3. Disjunção x ∨ y.
Свойства: 1) x ∨ y ≔ y ∨ x - comutatividade; 2) x ∨ x ≔ x - idempotência; 3) False ∨ y ≔ y, aqui False é o elemento neutro; 4) True ∨ y ≔ True, aqui True é um elemento absorvente. Uma exceção à regra geral são as regras para calcular as operações lógicas conjunção & e disjunção ∨ sob as condições de ação leis de absorção: (Falso & y) ≔ (x & Falso) ≔ Falso; (Verdadeiro ∨ y) ≔ (x ∨ Verdadeiro) ≔ Verdadeiro; Essas regras adicionais são formuladas para que, ao substituir um valor Null por False ou True, o resultado ainda não dependa desse valor. Conforme mostrado anteriormente para outros tipos de operações, usar valores Null em operações Booleanas também pode resultar em valores inesperados. Por exemplo, a lógica à primeira vista é quebrada em a lei da exclusão do terceiro (x ∨ ¬x) e a lei da reflexividade (x = x), pois para x ≔ Null temos: (x ∨ ¬x), (x = x) ≔ Nulo. As leis não são cumpridas! Isso é explicado da mesma forma que antes: quando um valor Nulo é substituído em uma expressão, a informação de que esse valor é informado pela mesma variável é perdida, e a regra geral para trabalhar com valores Nulos entra em vigor. Assim, concluímos: ao realizar operações lógicas com valores Nulos como operando, esses valores são determinados pelos sistemas gerenciadores de banco de dados conforme aplicável, mas desconhecido. 5. Valores nulos e verificação de condição Assim, do exposto, podemos concluir que na lógica dos sistemas de gerenciamento de banco de dados não existem dois valores lógicos (True e False), mas três, pois o valor Null também é considerado como um dos possíveis valores lógicos. É por isso que muitas vezes é referido como o valor desconhecido, o valor desconhecido. No entanto, apesar disso, apenas a lógica de dois valores é implementada em sistemas de gerenciamento de banco de dados. Portanto, uma condição com valor Null (uma condição indefinida) deve ser interpretada pela máquina como True ou False. Por padrão, a linguagem DBMS reconhece uma condição com um valor Null como False. Ilustramos isso com os seguintes exemplos da implementação de instruções condicionais If e While em sistemas de gerenciamento de banco de dados: Se P então A mais B; Essa entrada significa: se P for avaliado como Verdadeiro, a ação A será executada e se P for avaliado como Falso ou Nulo, a ação B será executada. Agora aplicamos a operação de negação a este operador, obtemos: Se ¬P então B senão A; Por sua vez, este operador significa o seguinte: se ¬P for avaliado como Verdadeiro, então a ação B será executada, e se ¬P for avaliado como Falso ou Nulo, então a ação A será executada. E novamente, como podemos ver, quando um valor Null aparece, encontramos resultados inesperados. O ponto é que as duas instruções If neste exemplo não são equivalentes! Embora um deles seja obtido do outro negando a condição e reorganizando os ramos, ou seja, pela operação padrão. Tais operadores são geralmente equivalentes! Mas em nosso exemplo, vemos que o valor Null da condição P no primeiro caso corresponde ao comando B e no segundo - A. Agora considere a ação da instrução condicional while: Enquanto P faz A; B; Como funciona este operador? Enquanto P for True, a ação A será executada, e assim que P for False ou Null, a ação B será executada. Mas os valores Null nem sempre são interpretados como False. Por exemplo, em restrições de integridade, as condições indefinidas são reconhecidas como Verdadeiras (restrições de integridade são condições impostas aos dados de entrada e garantem sua correção). Isso ocorre porque em tais restrições apenas dados deliberadamente falsos devem ser rejeitados. E, novamente, em sistemas de gerenciamento de banco de dados, há uma função de substituição IfNull(restrições de integridade, True), com o qual valores nulos e condições indefinidas podem ser representados explicitamente. Vamos reescrever as instruções condicionais If e While usando esta função: 1) Se IfNull ( P, False) então A else B; 2) Enquanto IfNull(P, False) faça A; B; Portanto, a função de substituição IfNull(expressão 1, expressão 2) retorna o valor da primeira expressão se ela não contiver um valor Nulo e, caso contrário, o valor da segunda expressão. Deve-se notar que nenhuma restrição é imposta ao tipo da expressão retornada pela função IfNull. Portanto, usando essa função, você pode substituir explicitamente quaisquer regras para trabalhar com valores nulos. Aula nº 3. Objetos de Dados Relacionais 1. Requisitos para a forma tabular de representação das relações 1. O primeiro requisito para a forma tabular da representação das relações é a finitude. Trabalhar com infinitas tabelas, relacionamentos ou quaisquer outras representações e organizações de dados é inconveniente, o esforço despendido raramente se justifica e, além disso, essa direção tem pouca aplicação prática. Mas além deste, bastante esperado, existem outros requisitos. 2. O cabeçalho da tabela que representa o relacionamento deve ser obrigatoriamente constituído por uma linha - o cabeçalho das colunas, e com nomes exclusivos. Cabeçalhos de vários níveis não são permitidos. Por exemplo, estes:
Todos os títulos de várias camadas são substituídos por títulos de camada única selecionando os títulos adequados. Em nosso exemplo, a tabela após as transformações especificadas ficará assim:
Vemos que o nome de cada coluna é único, então elas podem ser trocadas como você quiser, ou seja, sua ordem se torna irrelevante. E isso é muito importante porque é a terceira propriedade. 3. A ordem das linhas não deve ser significativa. No entanto, esse requisito também não é estritamente restritivo, pois qualquer tabela pode ser facilmente reduzida à forma exigida. Por exemplo, você pode inserir uma coluna adicional que determinará a ordem das linhas. Nesse caso, nada mudará com a reorganização das linhas. Aqui está um exemplo de tal tabela:
4. Não deve haver linhas duplicadas na tabela representando o relacionamento. Se houver linhas duplicadas na tabela, isso pode ser facilmente corrigido introduzindo uma coluna adicional responsável pelo número de duplicatas de cada linha, por exemplo:
A propriedade a seguir também é bastante esperada, pois está subjacente a todos os princípios de programação e design de bancos de dados relacionais. 5. Os dados em todas as colunas devem ser do mesmo tipo. Além disso, eles devem ser de um tipo simples. Vamos explicar o que são tipos de dados simples e complexos. Um tipo de dado simples é aquele cujos valores de dados não são compostos, ou seja, não contêm constituintes. Assim, nem listas, nem arrays, nem árvores, nem objetos compostos semelhantes devem estar presentes nas colunas da tabela. Tais objetos são tipo de dados composto - em sistemas de gerenciamento de banco de dados relacional, eles próprios são apresentados na forma de relações de tabelas independentes. 2. Domínios e atributos Domínios e atributos são conceitos básicos na teoria de criação e gerenciamento de bancos de dados. Vamos explicar o que é. Formalmente, domínio de atributo (indicado dom(a)), onde a é um atributo, é definido como o conjunto de valores válidos do mesmo tipo do atributo correspondente a. Este tipo deve ser simples, ou seja: dom(a) ⊆ {x | tipo(x) = tipo(a)}; Atributo (denominado a) é por sua vez definido como um par ordenado que consiste no nome do atributo name(a) e no domínio do atributo dom(a), ou seja: a = (nome(a): dom(a)); Esta definição usa ":" em vez do usual "," (como nas definições de pares ordenados padrão). Isso é feito para enfatizar a associação do domínio do atributo e o tipo de dados do atributo. Aqui estão alguns exemplos de atributos diferentes: а1 = (Curso: {1, 2, 3, 4, 5}); а2 = (MassaKg: {x | tipo(x) = real, x 0}); а3 = (ComprimentoSm: {x | tipo(x) = real, x 0}); Observe que os atributos a2 e um3 domínios coincidem formalmente. Mas o significado semântico desses atributos é diferente, pois comparar os valores de massa e comprimento não tem sentido. Portanto, um domínio de atributo está associado não apenas ao tipo de valores válidos, mas também a um significado semântico. Na forma tabular de um relacionamento, o atributo é exibido como um cabeçalho de coluna na tabela e o domínio do atributo não é especificado, mas implícito. Se parece com isso:
É fácil ver que aqui cada um dos títulos um1, um2, um3 colunas de uma tabela que representa um relacionamento é um atributo separado. 3. Esquemas de relacionamentos. Tuplas de valor nomeado Na teoria e na prática do SGBD, os conceitos de um esquema de relação e um valor nomeado de uma tupla em um atributo são básicos. Vamos trazê-los. esquema de relação (indicado S) é definido como um conjunto finito de atributos com nomes únicos, ou seja: S = {uma | uma∈S}; Em cada tabela que representa uma relação, todos os cabeçalhos de coluna (todos os atributos) são combinados no esquema da relação. O número de atributos em um esquema de relacionamento determina grau ele relações e é denotado como a cardinalidade do conjunto: |S|. Um esquema de relacionamento pode ser associado a um nome de esquema de relacionamento. Em uma forma tabular de representação de relacionamento, como você pode ver facilmente, o esquema de relacionamento nada mais é do que uma linha de cabeçalhos de coluna.
S = {uma1, um2, um3, um4} - esquema de relacionamento desta tabela. O nome da relação é exibido como um cabeçalho esquemático da tabela. Em forma de texto, o esquema de relacionamento pode ser representado como uma lista nomeada de nomes de atributos, por exemplo: Alunos (número da carteira, sobrenome, nome, patronímico, data de nascimento). Aqui, como na forma tabular, os domínios de atributo não são especificados, mas implícitos. Segue da definição que o esquema de uma relação também pode ser vazio (S = ∅). É verdade que isso é possível apenas na teoria, pois na prática o sistema de gerenciamento de banco de dados nunca permitirá a criação de um esquema de relacionamento vazio. Valor da tupla nomeada no atributo (indicado t(uma)) é definido por analogia com um atributo como um par ordenado que consiste em um nome de atributo e um valor de atributo, ou seja: t(a) = (nome(a) : x), x ∈ dom(a); Vemos que o valor do atributo é retirado do domínio do atributo. Na forma tabular de uma relação, cada valor nomeado de uma tupla em um atributo é uma célula da tabela correspondente:
Aqui t(um1), t(um2), t(um3) - valores nomeados da tupla t nos atributos a1E2E3. Os exemplos mais simples de valores de tupla nomeados em atributos: (Curso: 5), (Pontuação: 5); Aqui Curso e Pontuação são os nomes de dois atributos, respectivamente, e 5 é um de seus valores retirados de seus domínios. É claro que, embora esses valores sejam iguais em ambos os casos, eles são semanticamente diferentes, pois os conjuntos desses valores em ambos os casos diferem um do outro. 4. Tuplas. Tipos de tupla O conceito de tupla em sistemas gerenciadores de banco de dados já pode ser encontrado intuitivamente no parágrafo anterior, quando falamos sobre o valor nomeado de uma tupla em vários atributos. Então, tupla (indicado t, do inglês. tupla - "tupla") com esquema de relação S é definido como o conjunto de valores nomeados desta tupla em todos os atributos incluídos neste esquema de relação S. Em outras palavras, os atributos são retirados de escopo de uma tupla, def(t), ou seja: t ≡ t(S) = {t(a) | uma ∈ def(t) ⊆ S;. É importante que não mais de um valor de atributo corresponda a um nome de atributo. Na forma tabular do relacionamento, uma tupla será qualquer linha da tabela, ou seja:
Aqui t1(S) = {t(uma1), t(um2), t(um3), t(um4)} e T2(S) = {t(uma5), t(um6), t(um7), t(um8)} - tuplas. Tuplas no SGBD diferem em tipos dependendo do seu domínio de definição. As tuplas são chamadas: 1) parcial, se seu domínio de definição estiver incluído ou coincidir com o esquema da relação, ou seja, def(t) ⊆ S. Este é um caso comum na prática de banco de dados; 2) completo, caso seu domínio de definição coincida completamente, é igual ao esquema de relação, ou seja, def(t) = S; 3) incompleto, se o domínio de definição estiver completamente incluído no esquema de relações, ou seja, def(t) ⊂ S; 4) em nenhum lugar definido, se seu domínio de definição for igual ao conjunto vazio, ou seja, def(t) = ∅. Vamos explicar com um exemplo. Digamos que temos uma relação dada pela tabela a seguir.
Deixe aqui t1 = {10, 20, 30},t2 = {10, 20, Nulo}, t3 = {Nulo, Nulo, Nulo}. Então é fácil ver que a tupla t1 - completo, pois seu domínio de definição é def(t1) = {a, b, c} = S. Tupla t2 - incompleto, def(t2) = { a, b} ⊂ S. Finalmente, a tupla t3 - não definido em nenhum lugar, pois é def(t3) = ∅. Deve-se notar que uma tupla não definida em nenhum lugar é um conjunto vazio, porém associado a um esquema de relação. Às vezes, uma tupla definida em lugar nenhum é denotada: ∅(S). Como já vimos no exemplo acima, tal tupla é uma linha de tabela que consiste apenas em valores nulos. Curiosamente, o comparável, ou seja, possivelmente iguais, são apenas tuplas com o mesmo esquema de relacionamento. Portanto, por exemplo, duas tuplas definidas em lugar nenhum com esquemas de relacionamento diferentes não serão iguais, como seria de esperar. Eles serão diferentes, assim como seus padrões de relacionamento. 5. Relacionamentos. Tipos de relacionamento E por fim, vamos definir o relacionamento como uma espécie de topo da pirâmide, composto por todos os conceitos anteriores. Então, atitudes (indicado r, do inglês. relação) com o esquema de relação S é definido como um conjunto necessariamente finito de tuplas com o mesmo esquema de relação S. Assim: r ≡ r(S) = {t(S) | t∈r}; Por analogia com esquemas de relação, o número de tuplas em uma relação é chamado poder de relacionamento e denotado como a cardinalidade do conjunto: |r|. Relações, como tuplas, diferem em tipos. Assim, a relação é chamada: 1) parcial, se a seguinte condição for satisfeita para qualquer tupla incluída na relação: [def(t) ⊆ S]. Este é (como acontece com as tuplas) o caso geral; 2) completo, caso se ∀t ∈ r(S) temos [def(t) = S]; 3) incompleto, se ∃t ∈ r(S) def(t) ⊂ S; 4) em nenhum lugar definido, se ∀t ∈ r(S) [def(t) = ∅]. Prestemos atenção especial às relações não definidas em lugar algum. Ao contrário das tuplas, trabalhar com esses relacionamentos envolve um pouco de sutileza. O ponto é que as relações definidas em lugar nenhum podem ser de dois tipos: elas podem ser vazias ou podem conter uma única tupla definida em lugar nenhum (tais relações são denotadas por {∅(S)}). comparável (por analogia com tuplas), ou seja, possivelmente iguais, são apenas relações com o mesmo esquema de relação. Portanto, relacionamentos com diferentes padrões de relacionamento são diferentes. Na forma tabular, a relação é o corpo da tabela, ao qual corresponde a linha - o título das colunas, ou seja, literalmente - toda a tabela, juntamente com a primeira linha contendo os títulos. Aula No. 4. Álgebra Relacional. Operações unárias Álgebra relacional, como você pode imaginar, é um tipo especial de álgebra em que todas as operações são executadas em modelos de dados relacionais, ou seja, em relacionamentos. Em termos tabulares, uma relação inclui linhas, colunas e uma linha - o cabeçalho das colunas. Portanto, as operações unárias naturais são operações de seleção de determinadas linhas ou colunas, bem como de alteração de cabeçalhos de coluna - renomeação de atributos. 1. Operação de seleção unária A primeira operação unária que veremos é operação de busca - a operação de selecionar linhas de uma tabela representando uma relação, de acordo com algum princípio, ou seja, selecionar linhas-tuplas que satisfaçam uma determinada condição ou condições. Operador de busca denotado por σ , condição de amostragem - P , ou seja, o operador σ é sempre tomado com uma certa condição nas tuplas P, e a própria condição P é escrita dependendo do esquema da relação S. Levando em conta tudo isso, o operação de busca sobre o esquema da relação S em relação à relação r ficará assim: σ r(S) ≡ σ r = {t(S) |t ∈ r & P t} = {t(S) |t ∈ r & IfNull(P t, False}; O resultado desta operação será uma nova relação com o mesmo esquema de relação S, consistindo daquelas tuplas t(S) do operando-relação original que satisfazem a condição de seleção P t. Fica claro que para aplicar algum tipo de condição a uma tupla, é necessário substituir os valores dos atributos da tupla ao invés dos nomes dos atributos. Para entender melhor como essa operação funciona, vejamos um exemplo. Seja dado o seguinte esquema de relações: S: Sessão (Nº da Caderneta de Notas, Sobrenome, Assunto, Nota). Vamos tomar a condição de seleção da seguinte forma: P = (Assunto = ‘Ciência da Computação’ e Avaliação >
Precisamos extrair do operando-relação inicial aquelas tuplas que contêm informações sobre os alunos que passaram na disciplina "Ciência da Computação" em pelo menos três pontos. Seja também dada a seguinte tupla desta relação: t0(S) ∈ r(S): {(Boletim nº: 100), (Sobrenome: 'Ivanov'), (Assunto: 'Bancos de dados'), (Pontuação: 5)}; Aplicando nossa condição de seleção à tupla t0, Nós temos: P t0 = ('Bancos de dados' = 'Informática' e 5 > 3); Nesta tupla em particular, a condição de seleção não é atendida. Em geral, o resultado desta amostra em particular σ<Assunto = 'Ciência da Computação' e Série > 3 > Sessão haverá uma tabela "Sessão", na qual são deixadas as linhas que satisfazem a condição de seleção. 2. Operação de projeção unária Outra operação unária padrão que estudaremos é a operação de projeção. Operação de projeção é a operação de selecionar colunas de uma tabela representando uma relação, de acordo com algum atributo. Ou seja, a máquina seleciona aqueles atributos (ou seja, literalmente aquelas colunas) da relação operando original que foi especificada na projeção. operador de projeção denotado por [S'] ou π . Aqui S' é um subesquema do esquema original da relação S, ou seja, algumas de suas colunas. O que isto significa? Isso significa que S' tem menos atributos do que S, pois apenas permaneceram em S' aqueles atributos para os quais a condição de projeção foi satisfeita. E na tabela que representa a relação r(S' ), há tantas linhas quanto há na tabela r(S), e há menos colunas, pois restam apenas as correspondentes aos demais atributos. Assim, o operador de projeção π< S'> aplicado à relação r(S) resulta em uma nova relação com um esquema de relação diferente r(S' ), consistindo em projeções t(S) [S' ] de tuplas do original relação. Como essas projeções de tupla são definidas? Projeção de qualquer tupla t(S) da relação original r(S) para o subcircuito S' é determinada pela seguinte fórmula: t(S) [S'] = {t(a)|a ∈ def(t) ∩ S'}, S' ⊆S. É importante notar que as tuplas duplicadas são excluídas do resultado, ou seja, não haverá linhas duplicadas na tabela representando a nova. Com todos os itens acima em mente, uma operação de projeção em termos de sistemas de gerenciamento de banco de dados ficaria assim: π r(S) ≡ π r ≡ r(S) [S'] ≡ r [S' ] = {t(S) [S'] | t ∈ r}; Vejamos um exemplo que ilustra como funciona a operação de busca. Seja a relação "Sessão" e o esquema desta relação: S: Sessão (número da apostila, sobrenome, assunto, série); Estaremos interessados em apenas dois atributos deste esquema, a saber, "Gradebook #" e "Last Name" do aluno, então o subesquema S' ficará assim: S': (Número do livro de registro, Sobrenome). É necessário projetar a relação inicial r(S) no subcircuito S'. Em seguida, vamos receber uma tupla t0(S) da relação original: t0(S) ∈ r(S): {(Boletim nº: 100), (Sobrenome: 'Ivanov'), (Assunto: 'Bancos de dados'), (Pontuação: 5)}; Portanto, a projeção desta tupla no subcircuito S' será assim: t0(S) S': {(Número do livro de contas: 100), (Apelido: 'Ivanov')}; Se falarmos sobre a operação de projeção em termos de tabelas, então a Sessão de projeção [número do boletim de notas, Sobrenome] da relação original é a tabela Sessão, da qual todas as colunas são excluídas, exceto duas: número do boletim de notas e Sobrenome. Além disso, todas as linhas duplicadas também foram removidas. 3. Operação de renomeação unária E a última operação unária que veremos é operação de renomeação de atributo. Se falamos sobre o relacionamento como uma tabela, a operação de renomeação é necessária para alterar os nomes de todas ou algumas das colunas. renomear operador fica assim: ρ<φ>, aqui φ - renomear função. Esta função estabelece uma correspondência um-para-um entre os nomes dos atributos do esquema S e Ŝ, onde respectivamente S é o esquema da relação original e Ŝ é o esquema da relação com atributos renomeados. Assim, o operador ρ<φ> aplicado à relação r(S) dá uma nova relação com o esquema Ŝ, consistindo de tuplas da relação original com apenas atributos renomeados. Vamos escrever a operação de renomear atributos em termos de sistemas de gerenciamento de banco de dados: ρ<φ> r(S) ≡ ρ<φ>r = {ρ<φ> t(S)| t ∈ r}; Aqui está um exemplo de uso desta operação: Vamos considerar a relação Session já familiar para nós, com o esquema: S: Sessão (número da apostila, sobrenome, assunto, série); Vamos introduzir um novo esquema de relacionamento Ŝ, com diferentes nomes de atributos que gostaríamos de ver em vez dos existentes: Ŝ : (Nº ZK, Sobrenome, Assunto, Pontuação); Por exemplo, um cliente de banco de dados queria ver outros nomes em sua relação pronta para uso. Para implementar essa ordem, você precisa projetar a seguinte função de renomeação: φ : (Nº do livro de contas, Apelido, Assunto, Série) → (Nº ZK, Apelido, Assunto, Pontuação); Na verdade, apenas dois atributos precisam ser renomeados, então é legal escrever a seguinte função de renomeação em vez da atual: φ : (número do livro de registro, Grau) → (Nº ZK, Pontuação); Além disso, deixe que a tupla já familiar pertencente à relação Session também seja dada: t0(S) ∈ r(S): {(Boletim nº: 100), (Sobrenome: 'Ivanov'), (Assunto: 'Bancos de dados'), (Pontuação: 5)}; Aplique o operador renomear a esta tupla: ρ<φ>t0(S): {(ZK#: 100), (Sobrenome: 'Ivanov'), (Assunto: 'Bancos de dados'), (Pontuação: 5)}; Então, essa é uma das tuplas da nossa relação, cujos atributos foram renomeados. Em termos tabulares, a razão ρ < Número do boletim de notas, Nota → "Não. ZK, Pontuação > Sessão - esta é uma nova tabela obtida da tabela de relacionamento "Sessão" renomeando os atributos especificados. 4. Propriedades das operações unárias As operações unárias, como qualquer outra, têm certas propriedades. Vamos considerar o mais importante deles. A primeira propriedade das operações unárias de seleção, projeção e renomeação é a propriedade que caracteriza a razão das cardinalidades das relações. (Lembre-se que a cardinalidade é o número de tuplas em uma ou outra relação.) É claro que aqui estamos considerando, respectivamente, a relação inicial e a relação obtida como resultado da aplicação de uma ou outra operação. Observe que todas as propriedades das operações unárias seguem diretamente de suas definições, de modo que podem ser facilmente explicadas e até mesmo, se desejado, deduzidas independentemente. Assim: 1) relação de potência: a) para a operação de seleção: | σ r |≤ |r|; b) para a operação de projeção: | r[S'] | ≤ |r|; c) para a operação de renomeação: | ρ<φ>r | = |r|; No total, vemos que para dois operadores, nomeadamente para o operador de seleção e o operador de projeção, o poder das relações originais - operandos é maior do que o poder das relações obtidas dos originais aplicando as operações correspondentes. Isso ocorre porque a seleção que acompanha essas duas operações de seleção e projeto exclui algumas linhas ou colunas que não atendem às condições de seleção. No caso em que todas as linhas ou colunas satisfazem as condições, não há diminuição no poder (ou seja, o número de tuplas), então a desigualdade nas fórmulas não é estrita. No caso da operação de renomeação, o poder da relação não muda, pois ao mudar de nome, nenhuma tupla é excluída da relação; 2) propriedade idempotente: a) para a operação de amostragem: σ σ r = σ ; b) para a operação de projeção: r [S'] [S'] = r [S']; c) para a operação de renomeação, no caso geral, não se aplica a propriedade da idempotência. Esta propriedade significa que aplicar o mesmo operador duas vezes em sucessão a qualquer relação equivale a aplicá-lo uma vez. Para a operação de renomeação de atributos de relações, de modo geral, esta propriedade pode ser aplicada, mas com ressalvas e condições especiais. A propriedade da idempotência é muitas vezes usada para simplificar a forma de uma expressão e trazê-la para uma forma mais econômica e real. E a última propriedade que consideraremos é a propriedade da monotonicidade. É interessante notar que sob quaisquer condições todos os três operadores são monotônicos; 3) propriedade de monotonicidade: a) para uma operação de busca: r1 ⊆ r2 ⇒σ r1 ⇒ σ r2; b) para a operação de projeção: r1 ⊆ r2 ⇒ r1[S'] ⊆ r2 [S']; c) para a operação de renomeação: r1 ⊆ r2 ⇒ ρ<φ>r1 ⊆ ρ<φ>r2; O conceito de monotonicidade na álgebra relacional é semelhante ao mesmo conceito da álgebra geral ordinária. Esclareçamos: se inicialmente as relações r1 e r2 estavam relacionados entre si de tal forma que r ⊆ r2, então mesmo após aplicar qualquer um dos três operadores de seleção, projeção ou renomeação, essa relação será preservada. Aula No. 5. Álgebra Relacional. Operações Binárias 1. Operações de união, interseção, diferença Quaisquer operações têm suas próprias regras de aplicabilidade que devem ser observadas para que expressões e ações não percam seu significado. As operações binárias da teoria dos conjuntos de união, interseção e diferença só podem ser aplicadas a duas relações necessariamente com o mesmo esquema de relação. O resultado de tais operações binárias serão relações constituídas por tuplas que satisfaçam as condições das operações, mas com o mesmo esquema de relação dos operandos. 1. O resultado operações sindicais duas relações r1(S) e r2(S) haverá uma nova relação r3(S) consistindo dessas tuplas de relações r1(S) e r2(S) que pertencem a pelo menos uma das relações originais e com o mesmo esquema de relacionamento. Assim, a intersecção das duas relações é: r3(S) = r1(S) r2(S) = {t(S) | t∈r1 ∪t∈r2}; Para maior clareza, aqui está um exemplo em termos de tabelas: Sejam dadas duas relações: r1(S):
r2(S):
Vemos que os esquemas da primeira e da segunda relações são os mesmos, só que possuem um número diferente de tuplas. A união dessas duas relações será a relação r3(S), que corresponderá à tabela a seguir: r3(S) = r1(S) r2(S):
Assim, o esquema da relação S não mudou, apenas o número de tuplas aumentou. 2. Vamos passar para a consideração da próxima operação binária - operações de interseção dois relacionamentos. Como sabemos da geometria escolar, a relação resultante incluirá apenas as tuplas das relações originais que estão presentes simultaneamente em ambas as relações r1(S) e r2(S) (novamente, observe o mesmo padrão de relacionamento). A operação de intersecção de duas relações ficará assim: r4(S) = r1(S)∩r2(S) = {t(S) | t ∈ r1 & t ∈ r2}; E novamente, considere o efeito desta operação nas relações apresentadas na forma de tabelas: r1(S):
r2(S):
De acordo com a definição da operação pela intersecção das relações r1(S) e r2(S) haverá uma nova relação r4(S), cuja visualização de tabela ficaria assim: r4(S) = r1(S)∩r2(S):
De fato, se olharmos para as tuplas da primeira e segunda relações iniciais, há apenas uma comum entre elas: {b, 2}. Tornou-se a única tupla da nova relação r4(S). 3. Operação de diferença duas relações é definida de maneira semelhante às operações anteriores. As relações operando, como nas operações anteriores, devem ter os mesmos esquemas de relação, então a relação resultante incluirá todas aquelas tuplas da primeira relação que não estão na segunda, ou seja: r5(S) = r1(S)\r2(S) = {t(S) | t ∈ r1 & t ∉ r2}; As já conhecidas relações r1(S) e r2(S), em uma visualização tabular assim: r1(S):
r2(S):
Consideraremos ambos os operandos na operação de intersecção de duas relações. Então, seguindo esta definição, a relação resultante r5(S) ficará assim: r5(S) = r1(S)\r2(S):
As operações binárias consideradas são básicas; outras operações, mais complexas, são baseadas nelas. 2. Produto cartesiano e operações de junção natural A operação de produto cartesiano e a operação de junção natural são operações binárias do tipo produto e são baseadas na operação de união de duas relações que discutimos anteriormente. Embora a ação da operação do produto cartesiano possa parecer familiar para muitos, vamos, no entanto, começar com a operação do produto natural, pois é um caso mais geral do que a primeira operação. Portanto, considere a operação de junção natural. Deve-se notar imediatamente que os operandos desta ação podem ser relações com esquemas diferentes, em contraste com as três operações binárias de união, interseção e renomeação. Se considerarmos duas relações com diferentes esquemas de relação r1(S1) e r2(S2), então seus composto natural haverá uma nova relação r3(S3), que consistirá apenas daquelas tuplas de operandos que combinam na interseção dos esquemas de relacionamento. Assim, o esquema do novo relacionamento será maior do que qualquer um dos esquemas de relações dos originais, pois é a conexão deles, "colando". A propósito, tuplas que são idênticas em duas relações de operandos, segundo as quais essa "colação" ocorre, são chamadas conectável. Vamos escrever a definição da operação de junção natural na linguagem de fórmulas dos sistemas de gerenciamento de banco de dados: r3(S3) = r1(S1)xr2(S2) = {t(S1 ∪S2) | t[S1] ∈ r1 &t(S2) ∈ r2}; Vamos considerar um exemplo que ilustra bem o trabalho de uma conexão natural, sua "cola". Sejam duas relações r1(S1) e r2(S2), na forma tabular de representação, respectivamente, iguais: r1(S1):
r2(S2):
Vemos que essas relações têm tuplas que coincidem na interseção dos esquemas S1 e S2 relações. Vamos listá-los: 1) tupla {a, 1} da relação r1(S1) corresponde à tupla {1, x} da relação r2(S2); 2) tupla {b, 1} de r1(S1) também corresponde à tupla {1, x} de r2(S2); 3) a tupla {c, 3} corresponde à tupla {3, z}. Assim, sob junção natural, a nova relação r3(S3) é obtido "colando" exatamente nessas tuplas. Então r3(S3) em uma visualização de tabela ficará assim: r3(S3) = r1(S1)xr2(S2):
Acontece por definição: esquema S3 não coincide com o esquema S1, nem com o esquema S2, "colamos" os dois esquemas originais cruzando as tuplas para obter sua junção natural. Vamos mostrar esquematicamente como as tuplas são unidas ao aplicar a operação de junção natural. Seja a relação r1 tem uma forma condicional:
E a razão r2 - Visão:
Então sua conexão natural ficaria assim:
Vemos que a "colagem" de operandos-relações ocorre de acordo com o mesmo esquema que demos anteriormente, considerando o exemplo. Operação conexão cartesiana é um caso especial da operação de junção natural. Mais especificamente, ao considerar o efeito da operação do produto cartesiano nas relações, estipulamos deliberadamente que neste caso só podemos falar de esquemas de relações não-intersecionais. Como resultado da aplicação de ambas as operações, são obtidas relações com esquemas iguais à união de esquemas de relações de operandos, apenas todos os pares possíveis de suas tuplas caem no produto cartesiano de duas relações, pois os esquemas de operandos não devem em nenhum caso se cruzar. Assim, com base no exposto, escrevemos uma fórmula matemática para a operação do produto cartesiano: r4(S4) = r1(S1)xr2(S2) = {t(S1 ∪S2) | t[S1] ∈ r1 &t(S2) ∈ r2}, S1 ∩S2= ∅; Agora vamos ver um exemplo para mostrar como o esquema de relação resultante ficará ao aplicar a operação do produto cartesiano. Sejam duas relações r1(S1) e r2(S2), que são apresentados em forma de tabela da seguinte forma: r1(S1):
r2(S2):
Então vemos que nenhuma das tuplas de relações r1(S1) e r2(S2), de fato, não coincide em sua intersecção. Portanto, na relação resultante r4(S4) todos os pares possíveis de tuplas das relações do primeiro e do segundo operando cairão. Pegue: r4(S4) = r1(S1)xr2(S2):
Obtivemos um novo esquema de relação r4(S4) não por "colar" tuplas como no caso anterior, mas pela enumeração de todos os diferentes pares de tuplas possíveis que não combinam na interseção dos esquemas originais. Novamente, como no caso da junção natural, damos um exemplo esquemático da operação do produto cartesiano. Deixe r1 definido da seguinte forma:
E a razão r2 dado:
Então seu produto cartesiano pode ser representado esquematicamente da seguinte forma:
É assim que se obtém a relação resultante ao aplicar a operação do produto cartesiano. 3. Propriedades das operações binárias Das definições acima das operações binárias de união, interseção, diferença, produto cartesiano e junção natural, seguem as propriedades. 1. A primeira propriedade, como no caso de operações unárias, ilustra relação de potência relações: 1) para a operação sindical: |r1 ∪r2| ≤ |r1| + |r2|; 2) para a operação de interseção: |r1 ∩r2 | ≤ min(|r1|, |r2|); 3) para a operação de diferença: |r1 \r2| ≤ |r1|; 4) para a operação do produto cartesiano: |r1 xr2| = |r1| |r2|; 5) para operação de junção natural: |r1 xr2| ≤ |r1| |r2|. A razão de potências, como lembramos, caracteriza como o número de tuplas nas relações muda após a aplicação de uma ou outra operação. Então o que vemos? Poder associações duas relações r1 e r2 menor que a soma das cardinalidades dos operandos-relações originais. Por que isso está acontecendo? O problema é que, quando você mescla, as tuplas correspondentes desaparecem, sobrepondo-se umas às outras. Então, referindo-se ao exemplo que consideramos depois de passar por esta operação, você pode ver que na primeira relação havia duas tuplas, na segunda - três, e na resultante - quatro, ou seja, menos de cinco (a soma das cardinalidades das relações-operandos). Pela tupla correspondente {b, 2}, essas relações são "coladas". Poder do resultado cruzamentos duas relações é menor ou igual à cardinalidade mínima das relações de operandos originais. Passemos à definição desta operação: apenas as tuplas que estão presentes em ambas as relações iniciais entram na relação resultante. Isso significa que a cardinalidade da nova relação não pode exceder a cardinalidade do operando-relação cujo número de tuplas é o menor dos dois. E a potência do resultado pode ser igual a essa cardinalidade mínima, pois o caso é sempre permitido quando todas as tuplas de uma relação de menor cardinalidade coincidem com algumas tuplas do segundo operando-relação. Em caso de operação diferenças tudo é bastante trivial. De fato, se todas as tuplas que também estão presentes na segunda relação forem "subtraídas" do primeiro operando-relação, seu número (e, consequentemente, seu poder) diminuirá. Caso nenhuma tupla da primeira relação corresponda a qualquer tupla da segunda relação, ou seja, não há nada para "subtrair", seu poder não diminuirá. Curiosamente, se a operação produto cartesiano a potência da relação resultante é exatamente igual ao produto das potências das duas relações de operandos. É claro que isso acontece porque todos os pares possíveis de tuplas das relações originais são escritos no resultado e nada é excluído. E, finalmente, a operação conexão natural obtém-se uma relação cuja potência é maior ou igual ao produto das potências das duas relações originais. Novamente, isso acontece porque as relações de operandos são "coladas" por tuplas correspondentes, e as não correspondentes são excluídas completamente do resultado. 2. Propriedade de idempotência: 1) para a operação de união: r ∪ r = r; 2) para a operação de interseção: r ∩ r = r; 3) para a operação de diferença: r \ r ≠ r; 4) para a operação do produto cartesiano (no caso geral, a propriedade não é aplicável); 5) para a operação de junção natural: r x r = r. Curiosamente, a propriedade da idempotência não é verdadeira para todas as operações acima, e para a operação do produto cartesiano, não é aplicável. De fato, se você combinar, cruzar ou conectar naturalmente qualquer relação consigo mesma, ela não mudará. Mas se você subtrair de uma relação exatamente igual a ela, o resultado será uma relação vazia. 3. Propriedade comutativa: 1) para a operação sindical: r1 ∪r2 = r2 ∪r1; 2) para a operação de interseção: r ∩ r = r ∩ r; 3) para a operação de diferença: r1 \r2 ≠r2 \r1; 4) para a operação do produto cartesiano: r1 xr2 = r2 xr1; 5) para operação de junção natural: r1 xr2 = r2 xr1. A propriedade de comutatividade vale para todas as operações, exceto para a operação de diferença. Isso é fácil de entender, pois sua composição (tuplas) não muda ao rearranjar as relações nos lugares. E ao aplicar a operação de diferença, é importante qual das relações de operandos vem primeiro, pois depende de quais tuplas de qual relação serão tomadas como referência, ou seja, com quais tuplas outras tuplas serão comparadas para exclusão. 4. Propriedade de associatividade: 1) para a operação sindical: (r1 ∪r2) ∪r3 = r1 ∪(r2 ∪r3); 2) para a operação de interseção: (r1 ∩r2)∩r3 = r1 ∩(r2 ∩r3); 3) para a operação de diferença: (r1 \r2)\r3 ≠r1 \(r2 \r3); 4) para a operação do produto cartesiano: (r1 xr2)xr3 = r1 x(r2 xr3); 5) para operação de junção natural: (r1 xr2)xr3 = r1 x(r2 xr3). E novamente vemos que a propriedade é executada para todas as operações, exceto para a operação de diferença. Isso é explicado da mesma forma que no caso da aplicação da propriedade de comutatividade. Em geral, as operações de união, interseção, diferença e junção natural não se importam com a ordem em que as relações dos operandos estão. Mas quando os relacionamentos são "tirados" um do outro, a ordem desempenha um papel dominante. Com base nas propriedades e raciocínio acima, podemos tirar a seguinte conclusão: as três últimas propriedades, a saber, a propriedade de idempotência, comutatividade e associatividade, são verdadeiras para todas as operações que consideramos, exceto para a operação de diferença de duas relações , para o qual nenhuma das três propriedades indicadas foi satisfeita, e apenas em um caso a propriedade foi considerada inaplicável. 4. Opções de operação de conexão Utilizando como base as operações unárias de seleção, projeção, renomeação e operações binárias de união, interseção, diferença, produto cartesiano e junção natural consideradas anteriormente (todas elas são geralmente chamadas de operações de conexão), podemos introduzir novas operações derivadas usando os conceitos e definições acima. Essa atividade é chamada de compilação. opções de operação de junção. A primeira dessas variantes de operações de junção é a operação conexão interna de acordo com a condição de conexão especificada. A operação de uma junção interna por alguma condição específica é definida como uma operação derivada do produto cartesiano e operações de seleção. Escrevemos a definição da fórmula desta operação: r1(S1)x P r2(S2) = σ (r1 xr2),S1 ∩S2 =∅; Aqui P = P<S1 ∪S2> - uma condição imposta à união de dois esquemas das relações-operandos originais. É por esta condição que as tuplas são selecionadas das relações r1 e r2 na relação resultante. Observe que a operação de junção interna pode ser aplicada a relacionamentos com diferentes esquemas de relacionamento. Esses esquemas podem ser qualquer um, mas em nenhum caso eles devem se cruzar. As tuplas das relações de operandos originais que são o resultado da operação de junção interna são chamadas tuplas juntáveis. Para ilustrar visualmente a operação da operação de junção interna, daremos o exemplo a seguir. Sejam dadas duas relações r1(S1) e r2(S2) com diferentes esquemas de relacionamento: r1(S1):
r2(S2):
A tabela a seguir fornecerá o resultado da aplicação da operação de junção interna na condição P = (b1 = b2). r1(S1)x P r2(S2):
Assim, vemos que a "colagem" das duas tabelas que representam o relacionamento realmente aconteceu justamente para aquelas tuplas em que a condição da operação de junção interna P = (b1 = b2) é cumprida. Agora, com base na operação de junção interna já apresentada, podemos introduzir a operação junção externa esquerda и junção externa direita. Vamos explicar. O resultado da operação left outer join é o resultado da inner join, completado com tuplas não juntáveis do operando-relação de origem esquerda. Da mesma forma, o resultado de uma operação de junção externa à direita é definido como o resultado de uma operação de junção interna, completada com tuplas não juntáveis do operando de relação de origem destro. A questão de como as relações resultantes das operações das junções externas esquerda e direita são reabastecidas é bastante esperada. Tuplas de um operando-relação são complementadas no esquema de outro operando-relação Valores nulos. Vale a pena notar que as operações de junção externa esquerda e direita introduzidas dessa maneira são operações derivadas da operação de junção interna. Para escrever as fórmulas gerais para as operações de junção externa esquerda e direita, realizaremos algumas construções adicionais. Sejam dadas duas relações r1(S1) e r2(S2) com diferentes esquemas de relações S1 e S2, que não se cruzam. Como já estipulamos que as operações de junção interna esquerda e direita são derivadas, podemos obter as seguintes fórmulas auxiliares para determinar a operação de junção externa esquerda: 1) r3 (S2 ∪S1) ≔ r1(S1)x Pr2(S2); r 3 (S2 ∪S1) é simplesmente o resultado da junção interna das relações r1(S1) e r2(S2). A junção externa esquerda é uma operação derivada da operação junção interna, e é por isso que começamos nossas construções com ela; 2) r4(S1) ≔ r 3(S2 ∪S1) [S1]; Assim, com a ajuda de uma operação de projeção unária, selecionamos todas as tuplas juntáveis do operando-relação inicial esquerdo r1(S1). O resultado é designado r4(S1) para facilidade de uso; 3) r5 (S1) ≔ r1(S1)\r4(S1); Aqui r1(S1) são todas as tuplas do operando de relação de origem à esquerda, e r4(S1) - suas próprias tuplas, apenas conectadas. Assim, usando a operação binária da diferença, em relação a r5(S1) obtivemos todas as tuplas não juntáveis da relação do operando esquerdo; 4) r6(S2)≔{∅(S2)}; {∅(S2)} é uma nova relação com o esquema (S2) contendo apenas uma tupla e composta por valores Null. Por conveniência, denotamos essa razão como r6(S2); 5) r7 (S2 ∪S1) ≔ r5(S1)xr6(S2); Aqui nós pegamos as tuplas não conectadas da relação operando à esquerda (r5(S1)) e os complementou no esquema do segundo operando de relação S2 Valores nulos, ou seja, cartesiano multiplicado a relação consistindo dessas mesmas tuplas não juntáveis pela relação r6(S2) definido no parágrafo quarto; 6) r1(S1)→x P r2(S2) ≔ (r1 x P r2) ∪r7 (S2 ∪S1); Isto é junção externa esquerda, obtido, como pode ser visto, pela união do produto cartesiano dos operandos-relações originais r1 e r2 e relações r7 (S2 ∪ S1) definido no parágrafo XNUMX. Agora temos todos os cálculos necessários para determinar não apenas a operação da junção externa esquerda, mas por analogia e determinar a operação da junção externa direita. Então: 1) operação junção externa esquerda na forma estrita fica assim: r1(S1) →x P r2(S2) ≔ (r1 x P r2) ∪ [(r1 \(r1 x P r2) [S1]) x {∅(S2)}]; 2) operação junção externa direita é definido de maneira semelhante à operação left outer join e tem a seguinte forma: r1(S1) →x P r2(S2) ≔ (r1 x P r2) ∪ [(r2 \(r1 x P r2) [S2]) x {∅(S1)}]; Essas duas operações derivadas têm apenas duas propriedades dignas de menção. 1. Propriedade da comutatividade: 1) para a operação de junção externa esquerda: r1(S1) →x P r2(S2) ≠ r2(S2) →x P r1(S1); 2) para a operação de junção externa direita: r1(S1) ←x P r2(S2) ≠ r2(S2) ←x P r1(S1) Assim, vemos que a propriedade de comutatividade não é satisfeita para essas operações em termos gerais, mas as operações das junções externas esquerda e direita são mutuamente inversas, ou seja, o seguinte é verdadeiro: 1) para a operação de junção externa esquerda: r1(S1) →x P r2(S2) = r2(S2) →x P r1(S1); 2) para a operação de junção externa direita: r1(S1) ←x P r2(S2) = r2(S2) ←x Pr1(S1). 2. A principal propriedade das operações de junção externa esquerda e direita é que elas permitem restaurar o operando-relação inicial de acordo com o resultado final de uma determinada operação de junção, ou seja, são executados: 1) para a operação de junção externa esquerda: r1(S1) = (r1 →x P r2) [S1]; 2) para a operação de junção externa direita: r2(S2) = (r1 ←x P r2) [S2]. Assim, vemos que o primeiro operando-relação original pode ser restaurado a partir do resultado da operação de junção esquerda-direita, e mais especificamente, aplicando ao resultado desta junção (r1 xr2) a operação unária de projeção no esquema S1,[S1]. E da mesma forma, o segundo operando de relação original pode ser restaurado aplicando a junção externa direita (r1 xr2) a operação unária de projeção sobre o esquema da relação S2. Vamos dar um exemplo para uma consideração mais detalhada da operação das operações das junções externas esquerda e direita. Vamos introduzir as relações já familiares r1(S1) e r2(S2) com diferentes esquemas de relacionamento: r1(S1):
r2(S2):
Tupla não juntável do operando de relação esquerdo r2(S2) é uma tupla {d, 4}. Seguindo a definição, são eles que devem complementar o resultado da conexão interna das duas relações de operandos originais. Condição de junção interna das relações r1(S1) e r2(S2) também deixamos o mesmo: P = (b1 = b2). Então o resultado da operação junção externa esquerda haverá a seguinte tabela: r1(S1) →x P r2(S2):
De fato, como podemos ver, como resultado do impacto da operação de junção externa esquerda, o resultado da operação de junção interna foi reabastecido com tuplas não juntáveis da esquerda, ou seja, no nosso caso, a primeira relação- operando. O reabastecimento da tupla no esquema do segundo operando de relação de origem (à direita), por definição, aconteceu com a ajuda de valores nulos. E semelhante ao resultado junção externa direita pelo mesmo que antes, a condição P = (b1 = b2) das relações-operandos originais r1(S1) e r2(S2) é a seguinte tabela: r1(S1) ←x P r2(S2):
De fato, neste caso, o resultado da operação de junção interna deve ser reabastecido com tuplas não juntáveis à direita, no nosso caso, o segundo operando-relação inicial. Tal tupla, como não é difícil ver, na segunda relação r2(S2) um, a saber {2, y}. Em seguida, atuamos na definição da operação da junção externa direita, complementando a tupla do primeiro operando (esquerdo) no esquema do primeiro operando com valores nulos. Finalmente, vamos ver a terceira versão das operações de junção acima. Operação de junção externa completa. Esta operação pode ser considerada não apenas como uma operação derivada de operações de junção interna, mas também como uma união de operações de junção externa esquerda e direita. Operação de junção externa completa é definido como o resultado de completar a mesma junção interna (como no caso da definição de junções externas esquerda e direita) com tuplas não juntáveis das relações de operandos iniciais esquerda e direita. Com base nesta definição, damos a forma de formulário desta definição: r1(S1) ↔x P r2(S2) = (r1 →x P r2) ∪ (r1 ←x P r2); A operação de junção externa completa também tem uma propriedade semelhante à das operações de junção externa esquerda e direita. Somente devido à natureza recíproca original da operação de junção externa completa (afinal, ela foi definida como a união das operações de junção externa esquerda e direita), ela executa propriedade de comutatividade: r1(S1) ↔x P r2(S2)=r2(S2) ↔x P r1(S1); E para concluir a consideração das opções para operações de junção, vejamos um exemplo que ilustra a operação de uma operação de junção externa completa. Introduzimos duas relações r1(S1) e r2(S2) e a condição de junção. Deixar r1(S1)
r2(S2):
E deixe a condição de conexão das relações r1(S1) e r2(S2) será: P = (b1 = b2), como nos exemplos anteriores. Então o resultado da operação full outer join das relações r1(S1) e r2(S2) pela condição P = (b1 = b2) teremos a seguinte tabela: r1(S1) ↔x P r2(S2):
Assim, vemos que a operação de junção externa completa justifica claramente sua definição como a união dos resultados das operações de junção externa esquerda e direita. A relação resultante da operação de junção interna é complementada por tuplas simultaneamente não juntáveis como a esquerda (primeiro, r1(S1)) e à direita (segundo, r2(S2)) do operando de relação original. 5. Operações de derivativos Assim, consideramos várias variantes de operações de junção, ou seja, as operações de junção interna, junção esquerda, direita e junção externa completa, que são derivadas das oito operações originais da álgebra relacional: operações unárias de seleção, projeção, renomeação e operações binárias de união, interseção, diferença, produto cartesiano e conexão natural. Mas mesmo entre essas operações originais há exemplos de operações com derivativos. 1. Por exemplo, operação cruzamentos duas razões é uma derivada da operação da diferença das mesmas duas razões. Vamos mostrar. A operação de interseção pode ser expressa pela seguinte fórmula: r1(S)∩r2(S) = r1 \r1 \r2 ou, que dá o mesmo resultado: r1(S)∩r2(S) = r2 \r2 \r1; 2. Outro exemplo, a derivada da operação básica das oito operações originais é a operação conexão natural. Em sua forma mais geral, esta operação é derivada da operação binária do produto cartesiano e das operações unárias de selecionar, projetar e renomear atributos. Porém, por sua vez, a operação de junção interna é uma operação derivada da mesma operação do produto cartesiano de relações. Portanto, para mostrar que uma operação de junção natural é uma operação derivada, considere o exemplo a seguir. Vamos comparar os exemplos anteriores para operações de junção natural e interna. Sejam dadas duas relações r1(S1) e r2(S2) que atuarão como operandos. São iguais: r1(S1):
r2(S2):
Como já recebemos anteriormente, o resultado da operação de junção natural dessas relações será uma tabela da seguinte forma: r3(S3) ≔ r1(S1)xr2(S2):
E o resultado da junção interna das mesmas relações r1(S1) e r2(S2) pela condição P = (b1 = b2) teremos a seguinte tabela: r4(S4) ≔ r1(S1)x P r2(S2):
Vamos comparar esses dois resultados, as novas relações resultantes r3(S3) e r4(S4). É claro que a operação de junção natural é expressa através da operação de junção interna, mas, mais importante, com uma condição de junção de uma forma especial. Vamos escrever uma fórmula matemática que descreva a ação da operação de junção natural como uma derivada da operação de junção interna. r1(S1)xr2(S2) = { ρ < ϕ1>r1 x E ρ<ϕ2>r2}[S1 ∪S2], onde E- condição de conectividade tuplas; E= ∀a ∈S1 ∩S2 [IsNull(b1) & IsNull(2) ∪b1 = b2]; b1 =ϕ1 (nome(a)), b2 =ϕ2 (nomeia um)); Aqui está um dos renomear funções ϕ1 é idêntico, e outra função de renomeação (ou seja, ϕ2) renomeia os atributos onde nossos esquemas se cruzam. A condição de conectividade E para tuplas é escrita de forma geral, levando em consideração as possíveis ocorrências de valores Null, pois a operação de junção interna (como mencionado acima) é uma operação derivada do produto cartesiano de duas relações e a operação de seleção unária. 6. Expressões de álgebra relacional Vamos mostrar como as expressões e operações de álgebra relacional consideradas anteriormente podem ser usadas na operação prática de vários bancos de dados. Vamos, por exemplo, termos à nossa disposição um fragmento de algum banco de dados comercial: Fornecedores (Código de fornecedor, Nome do Fornecedor, Cidade do Fornecedor); Ferramentas (Código da ferramenta, Nome da ferramenta,...); Entregas (Código de fornecedor, código da peça); Os nomes de atributos sublinhados[1] são atributos-chave (ou seja, identificadores), cada um em sua própria relação. Suponha que nós, como desenvolvedores deste banco de dados e guardiões de informações sobre este assunto, sejamos obrigados a obter os nomes dos fornecedores (Nome do Fornecedor) e sua localização (Cidade do Fornecedor) no caso em que esses fornecedores não forneçam ferramentas com um nome genérico "Alicates". Para determinar todos os fornecedores que atendem a esse requisito em nosso banco de dados possivelmente muito grande, escrevemos algumas expressões de álgebra relacional. 1. Formamos uma conexão natural das relações "Fornecedores" e "Suprimentos" para combinar com cada fornecedor os códigos das peças fornecidas por ele. A nova relação - resultado da aplicação da operação de junção natural - para conveniência de aplicação posterior, será denotada por r1. Fornecedores x Suprimentos ≔ r1 (Código do Fornecedor, Nome do Fornecedor, Cidade do Fornecedor, Entre parênteses, listamos todos os atributos das relações envolvidas nesta operação de junção natural. Podemos ver que o atributo "ID do fornecedor" está duplicado, mas no registro de resumo da transação, cada nome de atributo deve aparecer apenas uma vez, ou seja: Fornecedores x Suprimentos ≔ r1 (Código do fornecedor, nome do fornecedor, cidade do fornecedor, código do instrumento); 2. novamente formamos uma conexão natural, só que desta vez a relação obtida no parágrafo um e a relação Instrumentos. Fazemos isso para corresponder o nome desta ferramenta com cada código de ferramenta obtido no parágrafo anterior. r1 x Ferramentas [Código da ferramenta, Nome da ferramenta] ≔ r2 (Código do Fornecedor, Nome do Fornecedor, Cidade do Fornecedor, O resultado resultante será denotado por r2, os atributos duplicados são excluídos: r1 x Ferramentas [Código da ferramenta, Nome da ferramenta] ≔ r2 (Código do fornecedor, nome do fornecedor, cidade do fornecedor, código do instrumento, nome do instrumento); Observe que tomamos apenas dois atributos da relação Tools: "Tool Code" e "Tool Name". Para fazer isso, nós, como pode ser visto a partir da notação da relação r2, aplicou-se a operação de projeção unária: Ferramentas [código da ferramenta, nome da ferramenta], ou seja, se a relação Ferramentas fosse apresentada como uma tabela, o resultado desta operação de projeção seriam as duas primeiras colunas com os títulos "Código da ferramenta" e "Ferramenta nome" respectivamente ". É interessante notar que os dois primeiros passos que já consideramos são bastante gerais, ou seja, podem ser usados para implementar quaisquer outras requisições. Mas os próximos dois pontos, por sua vez, representam passos concretos para alcançar a tarefa específica que temos diante de nós. 3. Escreva uma operação de seleção unária de acordo com a condição <"Nome da ferramenta" = "Alicate"> em relação à relação r2obtido no parágrafo anterior. E nós, por sua vez, aplicamos a operação de projeção unária [Código do Fornecedor, Nome do Fornecedor, Cidade do Fornecedor] ao resultado dessa operação para obter todos os valores desses atributos, pois precisamos obter essas informações com base no ordem. Assim: (σ<Nome da ferramenta = "Alicates"> r2) [Código do Fornecedor, Nome do Fornecedor, Cidade do Fornecedor] ≔ r3 (Código do fornecedor, nome do fornecedor, cidade do fornecedor, código da ferramenta, nome da ferramenta). Na razão resultante, denotada por r3, apenas esses fornecedores (com todos os seus dados de identificação) acabaram por fornecer ferramentas com o nome genérico "Alicates". Mas em virtude do pedido, precisamos destacar aqueles fornecedores que, ao contrário, não fornecem tais ferramentas. Portanto, vamos passar para a próxima etapa do nosso algoritmo e escrever a última expressão da álgebra relacional, que nos dará a informação que estamos procurando. 4. Primeiro, vamos fazer a diferença entre a proporção "Fornecedores" e a proporção r3, e após aplicar esta operação binária, aplicamos a operação de projeção unária nos atributos "Nome do Fornecedor" e "Cidade do Fornecedor". (Fornecedores\r3) [Nome do Fornecedor, Cidade do Fornecedor] ≔ r4 (Código do fornecedor, nome do fornecedor, cidade do fornecedor); O resultado é designado r4, essa relação incluía apenas aquelas tuplas da relação "Fornecedores" original que correspondiam à condição do nosso pedido. Assim, mostramos como, usando expressões e operações de álgebra relacional, você pode realizar todos os tipos de ações com bancos de dados arbitrários, realizar várias ordens, etc. Aula nº 6. Linguagem SQL Vamos primeiro dar um pouco de pano de fundo histórico. A linguagem SQL, projetada para interagir com bancos de dados, surgiu em meados da década de 1970. (primeiras publicações datam de 1974) e foi desenvolvido pela IBM como parte de um projeto experimental de sistema de gerenciamento de banco de dados relacional. O nome original da linguagem é SEQUEL (Structured English Query Language) - refletiu apenas parcialmente a essência dessa linguagem. Inicialmente, imediatamente após sua invenção e durante o período primário de operação da linguagem SQL, seu nome era uma abreviação da frase Structured Query Language, que se traduz como "Structured Query Language". Claro, a linguagem foi focada principalmente na formulação de consultas a bancos de dados relacionais que sejam convenientes e compreensíveis para os usuários. Mas, na verdade, quase desde o início, era uma linguagem de banco de dados completa, fornecendo, além dos meios de formulação de consultas e manipulação de bancos de dados, os seguintes recursos: 1) meios de definir e manipular o esquema do banco de dados; 2) meios para definir restrições e gatilhos de integridade (que serão mencionados posteriormente); 3) meios de definição de visualizações de banco de dados; 4) meios de definição de estruturas de camadas físicas que suportem a execução eficiente das requisições; 5) meio de autorização de acesso às relações e seus domínios. A linguagem não tinha os meios de sincronizar explicitamente o acesso a objetos de banco de dados do lado de transações paralelas: desde o início, assumiu-se que a sincronização necessária era realizada implicitamente pelo sistema de gerenciamento de banco de dados. Atualmente, SQL não é mais uma abreviação, mas o nome de uma linguagem independente. Além disso, atualmente, a linguagem de consulta estruturada é implementada em todos os sistemas comerciais de gerenciamento de banco de dados relacional e em quase todos os SGBDs que não foram originalmente baseados em uma abordagem relacional. Todas as empresas de manufatura afirmam que sua implementação está em conformidade com o padrão SQL e, de fato, os dialetos implementados da Structured Query Language são muito próximos. Isso não foi alcançado imediatamente. Uma característica dos sistemas de gerenciamento de banco de dados comerciais mais modernos que dificulta a comparação dos dialetos existentes do SQL é a falta de uma descrição uniforme da linguagem. Normalmente, a descrição está espalhada por vários manuais e misturada com uma descrição de recursos de linguagem específicos do sistema que não estão diretamente relacionados à linguagem de consulta estruturada. No entanto, pode-se dizer que o conjunto básico de instruções SQL, incluindo instruções para determinar o esquema do banco de dados, buscar e manipular dados, autorizar o acesso a dados, suporte para embutir SQL em linguagens de programação e instruções SQL dinâmicas, está bem estabelecido no mercado comercial. implementações e mais ou menos em conformidade com o padrão. Com o tempo e o trabalho na Structured Query Language, foi possível alcançar um padrão para uma padronização clara da sintaxe e semântica de instruções de recuperação de dados, manipulação de dados e correção de restrições de integridade do banco de dados. Foram especificados meios para definir as chaves primárias e estrangeiras de relacionamentos e as chamadas restrições de verificação de integridade, que são um subconjunto de restrições de integridade SQL verificadas imediatamente. As ferramentas para definir chaves estrangeiras facilitam a formulação dos requisitos da chamada integridade referencial de bancos de dados (sobre a qual falaremos mais adiante). Esse requisito, comum em bancos de dados relacionais, também poderia ser formulado com base no mecanismo geral de restrições de integridade SQL, mas a formulação baseada no conceito de chave estrangeira é mais simples e compreensível. Assim, levando em conta tudo isso, atualmente, a linguagem de consulta estruturada não é apenas o nome de uma linguagem, mas o nome de toda uma classe de linguagens, pois, apesar dos padrões existentes, vários dialetos da linguagem de consulta estruturada são implementados em vários sistemas de gerenciamento de banco de dados, que, é claro, têm uma base comum. 1. A instrução Select é a instrução básica da Structured Query Language O lugar central na linguagem de consulta estruturada SQL é ocupado pela instrução Select, que implementa a operação mais demandada ao trabalhar com bancos de dados - consultas. O operador Select avalia expressões de álgebra relacional e pseudo-relacional. Neste curso, consideraremos a implementação apenas das operações unárias e binárias da álgebra relacional que já abordamos, bem como a implementação de consultas usando as chamadas subconsultas. A propósito, deve-se notar que no caso de trabalhar com operações de álgebra relacional, tuplas duplicadas podem aparecer nas relações resultantes. Não há proibição estrita contra a presença de linhas duplicadas em relações nas regras da linguagem de consulta estruturada (diferentemente da álgebra relacional comum), portanto, não é necessário excluir duplicatas do resultado. Então, vamos ver a estrutura básica da instrução Select. É bastante simples e inclui as seguintes frases obrigatórias padrão: Selecione ... A partir de ... Onde... ; No lugar das reticências em cada linha devem estar as relações, atributos e condições de um determinado banco de dados e tarefas para ele. No caso mais geral, a estrutura básica Select deve ser assim: Selecionar selecione alguns atributos De de tal relacionamento Onde com tais e tais condições para amostragem de tuplas Assim, selecionamos atributos do esquema de relacionamento (títulos de algumas colunas), indicando de quais relacionamentos (e, como você pode ver, pode haver vários) fazemos nossa seleção e, finalmente, com base em quais condições paramos nossa escolha em certas tuplas. É importante observar que as referências de atributos são feitas usando seus nomes. Assim, obtém-se o seguinte algoritmo de trabalho esta instrução Select básica: 1) as condições para selecionar tuplas da relação são lembradas; 2) é verificado quais tuplas satisfazem as propriedades especificadas. Tais tuplas são lembradas; 3) os atributos listados na primeira linha da estrutura básica da instrução Select com seus valores são gerados. (Se falarmos sobre a forma tabular do relacionamento, serão exibidas essas colunas da tabela, cujos títulos foram listados como atributos necessários; é claro que as colunas não serão exibidas completamente, em cada uma delas apenas essas tuplas que satisfizeram as condições mencionadas permanecerão.) Considere um exemplo. Seja dada a seguinte relação r1, como um fragmento de algum banco de dados de livrarias:
Suponha que também tenhamos a seguinte expressão com a instrução Select: Selecionar Título do livro, Autor do livro De r1 Onde Preço do livro > 200; O resultado deste operador será o seguinte fragmento de tupla: (Telefone móvel, S. Rei). (A seguir, consideraremos muitos exemplos de implementações de consulta usando essa estrutura básica e estudaremos sua aplicação detalhadamente.) 2. Operações unárias na linguagem de consulta estruturada Nesta seção, consideraremos como as já familiares operações unárias de seleção, projeção e renomeação são implementadas na linguagem de consulta estruturada usando o operador Select. É importante notar que, se antes pudéssemos trabalhar apenas com operações individuais, mesmo um único operador Select no caso geral nos permite definir uma expressão de álgebra relacional inteira, e não apenas uma única operação. Então, passemos diretamente à análise da representação de operações unárias na linguagem de consultas estruturadas. 1. Operação de amostragem. A operação de seleção em SQL é implementada pela instrução Select da seguinte forma: Selecionar todos os atributos De nome da relação Onde condição de seleção; Aqui, em vez de escrever "todos os atributos", você pode usar o sinal "*". Na teoria da Linguagem de Consulta Estruturada, este ícone significa selecionar todos os atributos do esquema de relação. A condição de seleção aqui (e em todas as outras implementações de operações) é escrita como uma expressão lógica com conectivos padrão não (não) e (e) ou (ou). Os atributos de relacionamento são referidos por seus nomes. Considere um exemplo. Vamos definir o seguinte esquema de relação: performance acadêmica (Número do boletim de notas, semestre, código da disciplina, Classificação, Data); Aqui, como mencionado anteriormente, os atributos sublinhados formam a chave de relação. Vamos compor uma instrução Select da seguinte forma, que implementa a operação de seleção unária: Selecione * Do desempenho acadêmico Onde Boletim nº = 100 e Semestre = 6; É claro que, como resultado dessa declaração, a máquina exibirá o progresso de um aluno com número recorde cem para o sexto semestre. 2. Operação de projeção. A operação de projeção em Structured Query Language é ainda mais fácil de implementar do que a operação de busca. Lembre-se de que ao aplicar a operação de projeção, não são selecionadas linhas (como ao aplicar a operação de seleção), mas colunas. Portanto, basta listar os cabeçalhos das colunas desejadas (ou seja, nomes de atributos), sem especificar condições estranhas. No total, obtemos um operador da seguinte forma: Selecionar lista de nomes de atributos De nome da relação; Após aplicar esta instrução, a máquina retornará aquelas colunas da tabela de relações cujos nomes foram especificados na primeira linha desta instrução Select. Como mencionamos anteriormente, não é necessário excluir linhas e colunas duplicadas da relação resultante. Mas se em um pedido ou em uma tarefa for necessário eliminar duplicatas, você deve usar uma opção especial da linguagem de consulta estruturada - distinto. Esta opção define a eliminação automática de tuplas duplicadas da relação. Com esta opção aplicada, a instrução Select ficará assim: Selecionar lista distinta de nomes de atributos De nome da relação; Em SQL, existe uma notação especial para elementos opcionais de expressões - colchetes [...]. Portanto, na sua forma mais geral, a operação de projeção ficará assim: Selecionar [distinta] lista de nomes de atributos De nome da relação; No entanto, se o resultado da aplicação da operação for garantido para não conter duplicatas, ou duplicatas ainda são admissíveis, então a opção distinto é melhor não especificar para não sobrecarregar o registro, ou seja, por motivos de desempenho do operador. Vamos considerar um exemplo que ilustra a possibilidade de XNUMX% de confiança na ausência de duplicatas. Seja dado o esquema de relações já conhecido por nós: performance acadêmica (Número do boletim de notas, semestre, código da disciplina, Classificação, Data). Seja a seguinte instrução Select: Selecionar Número do boletim de notas, semestre, código da disciplina De performance acadêmica; Aqui, é fácil ver que os três atributos retornados pelo operador formam a chave da relação. Por isso a opção distinto torna-se redundante, porque é garantido que não haverá duplicatas. Isso decorre de um requisito nas chaves chamado de restrição exclusiva. Consideraremos essa propriedade com mais detalhes posteriormente, mas se o atributo for chave, não haverá duplicatas nele. 3. Renomear operação. A operação de renomear atributos na linguagem de consulta estruturada é bastante simples. Ou seja, é incorporado na realidade pelo seguinte algoritmo: 1) na lista de nomes de atributos da frase Selecionar, são listados os atributos que precisam ser renomeados; 2) a palavra-chave especial adicionada a cada atributo especificado; 3) após cada ocorrência da palavra as, é indicado o nome do atributo correspondente, ao qual é necessário alterar o nome original. Assim, levando em conta todo o exposto, a instrução correspondente à operação de renomeação de atributos ficará assim: Selecionar nome do atributo 1 como novo nome do atributo 1,... De nome da relação; Vamos mostrar como esse operador funciona com um exemplo. Seja dado o esquema de relacionamento que já nos é familiar: performance acadêmica (Número do boletim de notas, semestre, código da disciplina,Classificação, Data); Vamos ter uma ordem para alterar os nomes de alguns atributos, ou seja, em vez de "Número do livro de contas" deve haver "Número da conta" e em vez de "Pontuação" - "Pontuação". Vamos escrever como será a instrução Select que implementa essa operação de renomeação: Selecionar livro de registro como número de registro, semestre, código da disciplina, nota como pontuação, data De performance acadêmica; Assim, o resultado da aplicação deste operador será um novo esquema de relacionamento que difere do esquema de relacionamento original "Conquista" pelos nomes de dois atributos. 3. Operações binárias na linguagem de consultas estruturadas Assim como as operações unárias, as operações binárias também têm sua própria implementação na linguagem de consulta estruturada ou SQL. Então, vamos considerar a implementação nesta linguagem das operações binárias que já passamos, ou seja, as operações de união, interseção, diferença, produto cartesiano, junção natural, junção interna e esquerda, direita, junção externa completa. 1. Operação sindical. Para implementar a operação de combinação de duas relações, é necessário utilizar dois operadores Select simultaneamente, cada um dos quais correspondendo a um dos operandos-relações originais. E uma operação especial precisa ser aplicada a essas duas instruções Select básicas União. Considerando todos os itens acima, vamos escrever como será a operação de união usando a semântica da linguagem de consulta estruturada: Selecionar listar nomes de atributos da relação 1 De nome da relação 1 União Selecionar listar nomes de atributos da relação 2 De nome da relação 2; É importante observar que as listas de nomes de atributos dos dois relacionamentos que estão sendo unidos devem se referir a atributos de tipos compatíveis e ser listadas em ordem consistente. Se este requisito não for atendido, sua solicitação não poderá ser atendida e o computador exibirá uma mensagem de erro. Mas o que é interessante notar é que os próprios nomes de atributos nesses relacionamentos podem ser diferentes. Nesse caso, a relação resultante recebe os nomes de atributo especificados na primeira instrução Select. Você também precisa saber que o uso da operação Union exclui automaticamente todas as tuplas duplicadas da relação resultante. Portanto, se você precisar que todas as linhas duplicadas sejam preservadas no resultado final, em vez da operação União, você deve usar uma modificação desta operação - a operação União tudo. Nesse caso, a operação de combinar duas relações ficará assim: Selecionar listar nomes de atributos da relação 1 De nome da relação 1 União tudo Selecionar listar nomes de atributos da relação 2 De nome da relação 2; Neste caso, as tuplas duplicadas não serão removidas da relação resultante. Usando a notação mencionada anteriormente para elementos opcionais e opções em instruções Select, escrevemos a forma mais geral da operação de unir duas relações na linguagem de consulta estruturada: Selecionar listar nomes de atributos da relação 1 De nome da relação 1 União [Todos] Selecionar listar nomes de atributos da relação 2 De nome da relação 2; 2. Operação de interseção. A operação de interseção e a operação de diferença de duas relações na linguagem de consulta estruturada são implementadas de forma semelhante (consideramos o método de representação mais simples, pois quanto mais simples o método, mais econômico, mais relevante e, portanto, mais em demanda). Assim, vamos analisar a maneira de implementar a operação de interseção usando de chaves. Este método envolve a participação de duas construções Select, mas elas não são iguais (como na representação da operação de união), uma delas é, por assim dizer, uma "subconstrução", "subciclo". Esse operador é geralmente chamado subconsulta. Então, digamos que temos dois esquemas de relacionamento (R1 e R2), definido mais ou menos assim: R1 (chave,...) e R2 (chave,...); Ao gravar esta operação, também usaremos a opção especial in, que literalmente significa "em" ou (como neste caso específico) "contido em". Assim, levando em conta todo o exposto, a operação de intersecção de duas relações utilizando a linguagem de consulta estruturada será escrita da seguinte forma: Selecionar * De R1 Onde digite (Selecionar pista De R2); Assim, vemos que a subconsulta neste caso será o operador entre parênteses. Esta subconsulta em nosso caso retorna uma lista de valores chave da relação R2. E, como segue de nossa notação de operadores, da análise da condição de seleção, somente aquelas tuplas da relação R cairão na relação resultante1, cuja chave está contida na lista de chaves da relação R2. Ou seja, na relação final, se relembrarmos a definição da interseção de duas relações, apenas permanecerão as tuplas que pertencem a ambas as relações. 3. Operação de diferença. Como mencionado anteriormente, a operação unária da diferença de duas relações é implementada de forma semelhante à operação de interseção. Aqui, além da consulta principal com o operador Select, uma segunda consulta auxiliar é usada - a chamada subconsulta. Mas ao contrário da implementação da operação anterior, ao implementar a operação de diferença, é necessário usar outra palavra-chave, a saber não em, que em tradução literal significa "não em" ou (como é apropriado traduzir no nosso caso em consideração) - "não está contido em". Então, vamos, como no exemplo anterior, temos dois esquemas de relacionamento (R1 e R2), aproximadamente dado por: R1 (chave,...) e R2 (chave,...); Como você pode ver, os atributos-chave são novamente definidos entre os atributos dessas relações. Assim, obtemos a seguinte forma para representar a operação de diferença na linguagem de consulta estruturada: Selecione * De R1 Onde pista não em (Selecionar pista De R2); Assim, apenas aquelas tuplas da relação R1, cuja chave não está contida na lista de chaves da relação R2. Se considerarmos a notação literalmente, então realmente acontece que da relação R1 "subtraiu" a razão R2. A partir daqui concluímos que a condição de seleção neste operador está escrita corretamente (afinal, a definição da diferença de duas relações é realizada) e o uso de chaves, como no caso da implementação da operação de interseção, é totalmente justificado . Os dois usos do "método chave" que vimos são os mais comuns. Isso conclui o estudo do uso de chaves na construção de operadores que representam relações. Todas as operações binárias restantes da álgebra relacional são escritas de outras maneiras. 4. Operação do produto cartesiano Como lembramos das aulas anteriores, o produto cartesiano de dois operandos-relação é composto como um conjunto de todos os pares possíveis de valores nomeados de tuplas em atributos. Portanto, na linguagem de consulta estruturada, a operação do produto cartesiano é implementada usando uma junção cruzada, denotada pela palavra-chave junção cruzada, que se traduz literalmente como "junção cruzada" ou "junção cruzada". Existe apenas um operador Select na estrutura que representa a operação do produto cartesiano na linguagem de consulta estruturada e tem a seguinte forma: Selecione * De R1 junção cruzada R2 Aqui r1 e R2 - nomes dos operandos-relações iniciais. Opção junção cruzada garante que a relação resultante conterá todos os atributos (todos, pois a primeira linha do operador contém o sinal "*") correspondente a todos os pares de tuplas das relações R1 e R2. É muito importante lembrar uma característica da implementação da operação do produto cartesiano. Esta característica é consequência da definição da operação binária do produto cartesiano. Lembre-se: r4(S4) = r1(S1)xr2(S2) = {t(S1 ∪S2) | t[S1] ∈ r1 &t(S2) ∈ r2}, S1 ∩S2=∅; Como pode ser visto na definição acima, os pares de tuplas são formados com esquemas de relacionamento necessariamente sem interseção. Portanto, ao trabalhar na linguagem de consulta estruturada SQL, é invariavelmente estipulado que as relações de operandos iniciais não devem ter nomes de atributos correspondentes. Mas se essas relações ainda tiverem os mesmos nomes, a situação atual pode ser facilmente resolvida usando a operação de renomeação de atributos, ou seja, nesses casos, basta usar a opção as, que foi mencionado anteriormente. Vamos considerar um exemplo no qual precisamos encontrar o produto cartesiano de duas relações que têm alguns de seus nomes de atributos correspondentes. Então, dadas as seguintes relações: R1 (A,B), R2 (B,C); Vemos que os atributos R1.B e R2.B têm os mesmos nomes. Com isso em mente, a instrução Select que implementa essa operação de produto cartesiana na linguagem de consulta estruturada ficará assim: Selecionar A, R1.B as B1,R2.B as B2,C De R1 junção cruzada R2; Assim, utilizando a opção renomear como, a máquina não terá "dúvidas" sobre os nomes correspondentes das duas relações de operandos originais. 5. Operações de junção interna À primeira vista, pode parecer estranho considerarmos a operação de junção interna antes da operação de junção natural, pois quando passamos pelas operações binárias, tudo era o contrário. Mas analisando a expressão das operações na linguagem de consulta estruturada, pode-se chegar à conclusão de que a operação de junção natural é um caso especial da operação de junção interna. É por isso que é racional considerar essas operações apenas nessa ordem. Então, primeiro, vamos relembrar a definição da operação de junção interna pela qual passamos anteriormente: r1(S1)x P r2(S2) = σ (r1 xr2),S1 ∩ S2 =∅. Para nós, nesta definição, é especialmente importante que os esquemas de relações-operandos S considerados1 e S2 não deve se cruzar. Para implementar a operação de junção interna na linguagem de consulta estruturada, existe uma opção especial junção interna, que é traduzido literalmente do inglês como "inner join" ou "inner join". A instrução Select no caso de uma operação de junção interna ficará assim: Selecione * De R1 junção interna R2; Aqui, como antes, R1 e R2 - nomes dos operandos-relações iniciais. Ao implementar esta operação, os esquemas de operandos de relação não devem ser cruzados. 6. Operação de junção natural Como já dissemos, a operação de junção natural é um caso especial da operação de junção interna. Por quê? Sim, porque durante a ação de uma junção natural, as tuplas das relações dos operandos originais são unidas de acordo com uma condição especial. Ou seja, pela condição de igualdade de tuplas na interseção de operandos-relações, enquanto com a ação da operação de junção interna, tal situação não poderia ser permitida. Como a operação de junção natural que estamos considerando é um caso especial da operação de junção interna, a mesma opção é usada para implementá-la como para a operação considerada anteriormente, ou seja, a opção junção interna. Mas como, ao compilar o operador Select para a operação de junção natural, também é necessário levar em consideração a condição de igualdade das tuplas dos operandos-relações iniciais na interseção de seus esquemas, então, além da opção indicada, a palavra-chave é aplicada on. Traduzido do inglês, significa literalmente "on", e em relação ao nosso significado, pode ser traduzido como "sujeito a". A forma geral da instrução Select para realizar uma operação de junção natural é a seguinte: Selecione * De nome da relação 1 junção interna nome da relação 2 on condição de igualdade de tupla; Considere um exemplo. Sejam dadas duas relações: R1 (A,B,C), R2 (B, C, D); A operação de junção natural dessas relações pode ser implementada usando o seguinte operador: Selecionar A, R1.B,R1.CD De R1 junção interna R2 on R1.B=R2.B e R1.C=R2.C Como resultado desta operação, os atributos especificados na primeira linha do operador Select, correspondentes às tuplas iguais na interseção especificada, serão exibidos no resultado. Deve-se notar que aqui estamos nos referindo aos atributos comuns B e C, não apenas pelo nome. Isso deve ser feito não pelo mesmo motivo que no caso da implementação da operação cartesiana de produtos, mas porque, caso contrário, não ficará claro a qual relação eles se referem. Curiosamente, o texto usado da condição de junção (R1.B=R2.B e R1.C=R2.C) assume que os atributos compartilhados das relações de valor nulo unidas não são permitidos. Isso está embutido no sistema Structured Query Language desde o início. 7. Operação de junção externa esquerda A expressão da linguagem de consulta estruturada SQL da operação de junção externa esquerda é obtida da implementação da operação de junção natural substituindo a palavra-chave interior por palavra-chave exterior esquerdo. Assim, na linguagem de consultas estruturadas, essa operação será escrita da seguinte forma: Selecione * De nome da relação 1 junção externa esquerda nome da relação 2 on condição de igualdade de tupla; 8. Operação de junção externa direita A expressão para uma operação de junção externa direita na linguagem de consulta estruturada é obtida executando uma operação de junção natural substituindo a palavra-chave interior por palavra-chave direito externo. Assim, obtemos que na linguagem de consulta estruturada SQL, a operação da junção externa direita será escrita da seguinte forma: Selecione * De nome da relação 1 junção externa direita nome da relação 2 on condição de igualdade de tupla; 9. Operação de junção externa completa A expressão Structured Query Language para uma operação de junção externa completa é obtida, como nos dois casos anteriores, da expressão para uma operação de junção natural substituindo a palavra-chave interior por palavra-chave exterior completo. Assim, na linguagem de consultas estruturadas, esta operação será escrita da seguinte forma: Selecione * De nome da relação 1 junção externa completa nome da relação 2 on condição de igualdade de tupla; É muito conveniente que essas opções sejam incorporadas à semântica da linguagem de consulta estruturada SQL, porque, caso contrário, cada programador teria que produzi-las independentemente e inseri-las em cada novo banco de dados. 4. Usando subconsultas Como pode ser entendido a partir do material abordado, o conceito de "subconsulta" na linguagem de consulta estruturada é um conceito básico e bastante aplicável (às vezes, aliás, também são chamadas de consultas SQL. De fato, a prática de programação e trabalhar com banco de dados mostra que compilar um sistema de subconsultas para resolver várias tarefas relacionadas - uma atividade muito mais gratificante em comparação com alguns outros métodos de trabalhar com informações estruturadas. Portanto, vamos considerar um exemplo para entender melhor as ações com subconsultas, sua compilação E use. Seja o seguinte fragmento de um determinado banco de dados, que pode ser utilizado em qualquer instituição de ensino: Itens (Código do item, Nome do item); Alunos (número do livro de registro, Nome completo); Sessão (Código da disciplina, número do livro de notas, Avaliar); Vamos formular uma consulta SQL que retorna uma instrução indicando o número do livro de notas do aluno, o sobrenome e as iniciais e a nota da disciplina chamada "Bancos de dados". As universidades precisam receber essas informações sempre e em tempo hábil, portanto, a consulta a seguir talvez seja a unidade de programação mais popular usando esses bancos de dados. Por conveniência, vamos supor adicionalmente que os atributos "Last Name", "First Name" e "Patronymic" não permitem valores Null e não estão vazios. Esse requisito é bastante compreensível e lógico, pois os primeiros dados de um novo aluno inseridos no banco de dados de qualquer instituição de ensino são os dados sobre seu sobrenome, nome e patronímico. E nem é preciso dizer que não pode haver uma entrada em tal banco de dados que contenha dados sobre um aluno, mas ao mesmo tempo seu nome é desconhecido. Observe que o atributo "Nome do item" do esquema de relacionamento "Itens" é uma chave, portanto, conforme segue a definição (mais sobre isso posteriormente), todos os nomes de itens são exclusivos. Isso também é compreensível sem explicar a representação da chave, porque todas as disciplinas ensinadas em uma instituição de ensino devem ter e ter nomes diferentes. Agora, antes de começarmos a compilar o texto do próprio operador, apresentaremos duas funções que nos serão úteis à medida que prosseguirmos. Primeiro vamos precisar da função aparar, é escrito Trim ("string"), ou seja, o argumento para esta função é uma string. O que essa função faz? Eles retornam o próprio argumento sem espaços no início e no final desta linha, ou seja, esta função é utilizada, por exemplo, nos casos: Trim ("Bogucharnikov") ou Trim ("Maksimenko"), quando argumentos após ou antes são vale alguns espaços extras. E em segundo lugar, também é necessário considerar a função Esquerda, que se escreve Esquerda (string, número), ou seja, uma função de já dois argumentos, um dos quais é, como antes, uma string. Seu segundo argumento é um número, ele indica quantos caracteres do lado esquerdo da string devem ser exibidos no resultado. Por exemplo, o resultado da operação: Esquerda ("Mikhail, 1") + "." + Esquerda ("Zinovievich, 1") serão as iniciais "M.Z." É para exibir as iniciais dos alunos que usaremos essa função em nossa consulta. Então, vamos começar a compilar a consulta desejada. Primeiro, vamos fazer uma pequena consulta auxiliar, que usamos na consulta principal, principal: Selecionar Número do boletim de notas, Grau De Sessão Onde Código do item = (Selecionar Código do item De objetos Onde Nome do item = "Bancos de dados") as "Estimativas" Bases de Dados "; Usar a opção as aqui significa que apelidamos essa consulta de "Estimativas de banco de dados". Fizemos isso para facilitar o trabalho adicional com essa solicitação. Em seguida, nesta consulta, uma subconsulta: Selecionar Código do item De objetos Onde Nome do item = "Bancos de dados"; permite selecionar na relação "Sessão" aquelas tuplas que se relacionam com o assunto em consideração, ou seja, bancos de dados. Curiosamente, essa subconsulta interna só pode retornar um valor, pois o atributo "Nome do item" é a chave do relacionamento "Itens", ou seja, todos os seus valores são únicos. E toda a consulta "Pontuações "Banco de dados" permite selecionar na relação "Sessão" dados sobre os alunos (seus números e notas do boletim de notas) que atendem à condição especificada na subconsulta, ou seja, informações sobre o assunto chamado "Banco de dados". Agora faremos a requisição principal, utilizando os resultados já recebidos. Selecionar Alunos. número do livro de registro, aparar (Sobrenome) + " " + Esquerdo (Nome, 1) + "." + Esquerdo (Patronímico, 1) + "."as Nome completo, Estimativas "Bancos de dados". Avaliar De Alunos junção interna ( Selecionar Número do boletim de notas, Grau De Sessão Onde Código do item = (Selecionar Código do item De objetos Onde Nome do item = "Bancos de dados") ) Como "Estimativas" Bases de Dados ". on Alunos. Boletim # = Notas do "Banco de dados". Número do livro de registro. Então, primeiro listamos os atributos que precisarão ser exibidos após a conclusão da consulta. Deve-se mencionar que o atributo "Número da Caderneta" é da relação Alunos, daí - os atributos "Sobrenome", "Nome" e "Patronímico". É verdade que os dois últimos atributos não são totalmente deduzidos, mas apenas as primeiras letras. Também mencionamos o atributo 'Score' da consulta 'Database Score' que inserimos anteriormente. Selecionamos todos esses atributos da junção interna da relação "Alunos" e da consulta "Notas do banco de dados". Essa junção interna, como podemos ver, é feita por nós sob a condição de igualdade dos números do livro de registro. Como resultado dessa operação de junção interna, as notas são adicionadas à relação Alunos. Deve-se notar que, como os atributos "Sobrenome", "Nome" e "Patronímico" por condição não permitem valores nulos e não são vazios, a fórmula de cálculo que retorna o atributo "Nome" (aparar (Sobrenome) + " " + Esquerdo (Nome, 1) + "." + Esquerdo (Patronímico, 1) + "."as Nome completo), respectivamente, não requer verificações adicionais, é simplificado. Aula número 7. Relações básicas Como já sabemos, os bancos de dados são como uma espécie de contêiner, cujo objetivo principal é armazenar os dados apresentados na forma de relacionamentos. Você precisa saber que, dependendo de sua natureza e estrutura, os relacionamentos são divididos em: 1) relacionamentos básicos; 2) relacionamentos virtuais. Os relacionamentos de exibição base contêm apenas dados independentes e não podem ser expressos em termos de outros relacionamentos de banco de dados. Em sistemas de gerenciamento de banco de dados comercial, os relacionamentos básicos são geralmente referidos simplesmente como mesas em contraste com as representações correspondentes ao conceito de relações virtuais. Neste curso, consideraremos com algum detalhe apenas os relacionamentos básicos, as principais técnicas e princípios de trabalhar com eles. 1. Tipos de dados básicos Tipos de dados, como relacionamentos, são divididos em básico и virtual. (Falaremos sobre tipos de dados virtuais um pouco mais tarde; dedicaremos um capítulo separado a este tópico.) Tipos de dados básicos - estes são quaisquer tipos de dados que são definidos inicialmente em sistemas de gerenciamento de banco de dados, ou seja, presentes por padrão (em oposição a um tipo de dados definido pelo usuário, que analisaremos imediatamente após passar pelo tipo de dados base). Antes de prosseguir com a consideração dos tipos de dados básicos reais, listamos quais tipos de dados existem em geral: 1) dados numéricos; 2) dados lógicos; 3) dados de cadeia; 4) dados que definem a data e hora; 5) dados de identificação. Por padrão, os sistemas de gerenciamento de banco de dados introduziram vários dos tipos de dados mais comuns, cada um dos quais pertencendo a um dos tipos de dados listados. Vamos chamá-los. 1. Em numérico tipo de dados é distinguido: 1) inteiro. Essa palavra-chave geralmente denota um tipo de dados inteiro; 2) Real, correspondendo ao tipo de dado real; 3) Decimal(n, m). Este é um tipo de dados decimal. Além disso, na notação n é um número que fixa o número total de dígitos do número, e m mostra quantos caracteres deles estão após a vírgula; 4) Dinheiro ou Moeda, introduzido especificamente para a representação conveniente de dados do tipo de dados monetários. 2. Em lógico tipo de dados geralmente alocam apenas um tipo básico, este é lógico. 3. Corda o tipo de dados tem quatro tipos básicos (significando, é claro, os mais comuns): 1) Bit(n). São cadeias de bits com comprimento fixo n; 2) Varbit(n). Também são cadeias de bits, mas com comprimento variável não superior a n bits; 3) Cara(n). São cadeias de caracteres com comprimento constante n; 4) Varchar(n). São cadeias de caracteres, com comprimento variável que não excede n caracteres. 4. Tipo data e hora inclui os seguintes tipos de dados básicos: 1) Data - tipo de dado de data; 2) Hora - tipo de dado que expressa a hora do dia; 3) Data-hora é um tipo de dados que expressa data e hora. 5. Identificação O tipo de dados contém apenas um tipo incluído por padrão no sistema de gerenciamento de banco de dados, que é o GUID (Globally Unique Identifier). Deve-se notar que todos os tipos de dados básicos podem ter variantes de diferentes intervalos de representação de dados. Para dar um exemplo, as variantes do tipo de dados inteiro de quatro bytes podem ser tipos de dados de oito bytes (grande) e dois bytes (pequeno). Vamos falar separadamente sobre o tipo de dados GUID básico. Esse tipo destina-se a armazenar valores de dezesseis bytes do chamado identificador global exclusivo. Todos os diferentes valores desse identificador são gerados automaticamente quando uma função interna especial é chamada NovoId(). Esta designação vem da frase completa em inglês New Identification, que significa literalmente "novo valor identificador". Cada valor de identificador gerado em um computador específico é exclusivo em todos os computadores fabricados. O identificador GUID é usado, em particular, para organizar a replicação de banco de dados, ou seja, ao criar cópias de alguns bancos de dados existentes. Esses GUIDs podem ser usados por desenvolvedores de banco de dados junto com outros tipos básicos. Uma posição intermediária entre o tipo GUID e outros tipos base é ocupada por outro tipo base especial - o tipo contador. Uma palavra-chave especial é usada para designar dados desse tipo. Contador(x0, ∆x), que se traduz literalmente do inglês e significa "contador". Parâmetro x0 define o valor inicial e ∆x - passo de incremento. Os valores desse tipo de contador são necessariamente inteiros. Deve-se notar que trabalhar com esse tipo de dados básico inclui vários recursos muito interessantes. Por exemplo, valores desse tipo de contador não são definidos, como estamos acostumados ao trabalhar com todos os outros tipos de dados, eles são gerados sob demanda, assim como para valores do tipo identificador globalmente exclusivo. Também é incomum que o tipo de contador só possa ser especificado ao definir a tabela, e só então! Este tipo não pode ser usado no código. Você também precisa lembrar que ao definir uma tabela, o tipo de contador só pode ser especificado para uma coluna. Os valores dos dados do contador são gerados automaticamente quando as linhas são inseridas. Além disso, essa geração é realizada sem repetição, de modo que o contador sempre identificará de forma única cada linha. Mas isso cria alguns inconvenientes ao trabalhar com tabelas contendo dados de contador. Se, por exemplo, os dados na relação dada pela tabela forem alterados e tiverem que ser apagados ou trocados, os valores do contador podem facilmente "confundir as cartas", principalmente se um programador inexperiente estiver trabalhando. Vamos dar um exemplo que ilustra tal situação. Seja dada a seguinte tabela representando alguma relação, na qual quatro linhas são inseridas:
O contador deu automaticamente a cada nova linha um nome exclusivo. E agora vamos remover a segunda e quarta linhas da tabela, e então adicionar uma linha adicional. Essas operações resultarão na seguinte transformação da tabela de origem:
Assim, o contador removeu a segunda e a quarta linhas junto com seus nomes exclusivos e não as "reatribuiu" a novas linhas, como seria de esperar. Além disso, o sistema de gerenciamento de banco de dados nunca permitirá que você altere o valor do contador manualmente, assim como não permitirá que você declare vários contadores em uma tabela ao mesmo tempo. Normalmente, o contador é usado como substituto, ou seja, uma chave artificial na mesa. É interessante saber que os valores únicos de um contador de quatro bytes a uma taxa de geração de um valor por segundo durarão mais de 100 anos. Vamos mostrar como é calculado: 1 ano = 365 dias * 24 h * 60 s * 60 s < 366 dias * 24 h * 60 s * 60 s < 225 com. 1 segundo > 2-25 ano 24*8 valores / 1 valor/segundo = 232 c > 27 ano > 100 anos. 2. Tipo de dados personalizado Um tipo de dados customizado difere de todos os tipos básicos, pois não foi originalmente integrado ao sistema de gerenciamento de banco de dados, não foi declarado como um tipo de dados padrão. Esse tipo pode ser criado por qualquer usuário e programador de banco de dados de acordo com suas próprias solicitações e requisitos. Assim, um tipo de dado definido pelo usuário é um subtipo de algum tipo base, ou seja, é um tipo base com algumas restrições no conjunto de valores permitidos. Na notação de pseudocódigo, um tipo de dados personalizado é criado usando a seguinte instrução padrão: Criar subtipo nome do subtipo Formato nome do tipo base As restrição de subtipo; Portanto, na primeira linha, devemos especificar o nome do nosso novo tipo de dados definido pelo usuário, na segunda - qual dos tipos de dados básicos existentes tomamos como modelo, criando nosso próprio e, finalmente, na terceira - aquelas restrições que precisamos adicionar às restrições existentes no conjunto de valores do tipo de dados base - amostra. As restrições de subtipo são escritas como uma condição dependente do nome do subtipo que está sendo definido. Para entender melhor como a instrução Create funciona, considere o exemplo a seguir. Suponha que precisamos criar nosso próprio tipo de dados especializado, por exemplo, para trabalhar no correio. Este será o tipo para trabalhar com dados como números de CEP. Nossos números serão diferentes dos números decimais comuns de seis dígitos, pois só podem ser positivos. Vamos escrever um operador para criar o subtipo que precisamos: Criar subtipo Código postal Formato decimal(6, 0) As Código postal > 0. Por que escolhemos decimal(6, 0)? Relembrando a forma usual do índice, vemos que tais números devem consistir em seis inteiros de zero a nove. É por isso que tomamos o tipo decimal como o tipo de dados base. É curioso notar que, em geral, a condição imposta ao tipo de dado base, ou seja, a restrição de subtipo, pode conter os conectivos lógicos not, e, ou, e em geral ser uma expressão de qualquer complexidade arbitrária. Os subtipos de dados personalizados definidos dessa maneira podem ser usados livremente junto com outros tipos de dados básicos tanto no código do programa quanto ao definir tipos de dados nas colunas da tabela, ou seja, os tipos de dados básicos e os tipos de dados do usuário são completamente iguais ao trabalhar com eles. No ambiente de desenvolvimento visual, eles aparecem em listas de tipos válidos junto com outros tipos de dados básicos. A probabilidade de precisarmos de um tipo de dados não documentado (definido pelo usuário) ao projetar um novo banco de dados próprio é bastante alta. De fato, por padrão, apenas os tipos de dados mais comuns são costurados no sistema de gerenciamento de banco de dados, adequados, respectivamente, para resolver as tarefas mais comuns. Ao compilar bancos de dados de assunto, é quase impossível fazer sem projetar seus próprios tipos de dados. Mas, curiosamente, com igual probabilidade, podemos precisar remover o subtipo que criamos, para não bagunçar e complicar o código. Para fazer isso, os sistemas de gerenciamento de banco de dados geralmente têm um operador especial embutido. cair, que significa "remover". A forma geral deste operador para remover tipos personalizados desnecessários é a seguinte: Subtipo de descarte o nome do tipo personalizado; Os tipos de dados personalizados geralmente são recomendados para subtipos que são gerais o suficiente. 3. Valores padrão Os sistemas de gerenciamento de banco de dados podem ter a capacidade de criar quaisquer valores padrão arbitrários ou, como também são chamados, padrões. Esta operação em qualquer ambiente de programação tem um peso bastante grande, pois em quase todas as tarefas pode ser necessário introduzir constantes, valores padrão imutáveis. Para criar um padrão em sistemas de gerenciamento de banco de dados, a função já familiar para nós da passagem de um tipo de dados definido pelo usuário é usada Crie. Somente no caso de criação de um valor padrão, uma palavra-chave adicional também é usada omissão, que significa "padrão". Em outras palavras, para criar um valor padrão em um banco de dados existente, você deve usar a seguinte instrução: Criar padrão nome padrão As expressão constante; É claro que no lugar de um valor constante ao aplicar este operador, você precisa escrever o valor ou expressão que queremos tornar o valor ou expressão padrão. E, é claro, precisamos decidir sob qual nome será conveniente usá-lo em nosso banco de dados e escrever esse nome na primeira linha do operador. Observe que, nesse caso específico, essa instrução Create segue a sintaxe Transact-SQL incorporada ao sistema Microsoft SQL Server. Então o que temos? Deduzimos que o padrão é uma constante nomeada armazenada em bancos de dados, assim como seu objeto. No ambiente de desenvolvimento visual, os padrões aparecem na lista de padrões destacados. Aqui está um exemplo de criação de um padrão. Suponha que para o correto funcionamento do nosso banco de dados seja necessário que um valor funcione nele com o significado de um tempo de vida ilimitado de algo. Em seguida, você precisa inserir na lista de valores desse banco de dados o valor padrão que atende a esse requisito. Isso pode ser necessário, apenas porque cada vez que você encontrar essa expressão bastante complicada no texto do código, será extremamente inconveniente escrevê-la novamente. É por isso que usaremos a instrução Create acima para criar um padrão, com o significado de um tempo de vida ilimitado de algo. Criar padrão "sem limite de tempo" As ‘9999-12-31 23: 59:59’ A sintaxe Transact-SQL também foi usada aqui, segundo a qual os valores das constantes de data e hora (neste caso, '9999-12-31 23:59:59') são escritos como cadeias de caracteres de uma determinada direção. A interpretação de strings de caracteres como valores de data e hora é determinada pelo contexto em que as strings são usadas. Por exemplo, em nosso caso particular, primeiro o valor limite do ano é escrito na linha constante e depois o tempo. No entanto, apesar de toda a sua utilidade, os padrões, como um tipo de dados definido pelo usuário, às vezes também podem exigir que sejam removidos. Os sistemas de gerenciamento de banco de dados geralmente têm um predicado integrado especial, semelhante a um operador que remove um tipo de dados mais definido pelo usuário que não é mais necessário. Este é um predicado Cair e o próprio operador se parece com isso: Soltar padrão nome padrão; 4. Atributos Virtuais Todos os atributos em sistemas de gerenciamento de banco de dados são divididos (por analogia absoluta com relacionamentos) em básicos e virtuais. Assim chamado atributos básicos são atributos armazenados que precisam ser usados mais de uma vez e, portanto, é aconselhável salvar. E, por sua vez, atributos virtuais não são armazenados, mas atributos computados. O que isto significa? Isso significa que os valores dos chamados atributos virtuais não são realmente armazenados, mas são calculados através dos atributos base em tempo real por meio de fórmulas fornecidas. Neste caso, os domínios dos atributos virtuais computados são determinados automaticamente. Vamos dar um exemplo de uma tabela que define uma relação, na qual dois atributos são comuns, básicos e o terceiro atributo é virtual. Ele será calculado de acordo com uma fórmula especialmente inserida.
Assim, vemos que os atributos "Peso Kg" e "Preço Rub por Kg" são atributos básicos, pois possuem valores ordinários e ficam armazenados em nosso banco de dados. Mas o atributo "Custo" é um atributo virtual, pois é definido pela fórmula de seu cálculo e não será realmente armazenado no banco de dados. É interessante notar que, devido à sua natureza, os atributos virtuais não podem assumir valores padrão e, em geral, o próprio conceito de valor padrão para um atributo virtual não tem sentido e, portanto, não é aplicável. E você também precisa estar ciente de que, embora os domínios dos atributos virtuais sejam determinados automaticamente, o tipo de valores calculados às vezes precisa ser alterado do existente para outro. Para fazer isso, a linguagem dos sistemas de gerenciamento de banco de dados possui um predicado Convert especial, com a ajuda do qual o tipo da expressão calculada pode ser redefinido. Convert é a chamada função de conversão de tipo explícito. Está escrito da seguinte forma: Converter (tipo de dados, expressão); A expressão que é o segundo argumento da função Convert será calculada e emitida como tal dado, cujo tipo é indicado pelo primeiro argumento da função. Considere um exemplo. Suponha que precisamos calcular o valor da expressão "2 * 2", mas precisamos gerar isso não como um inteiro "4", mas como uma string de caracteres. Para realizar essa tarefa, escrevemos a seguinte função Convert: Converter (Carac(1), 2 * 2). Assim, podemos ver que esta notação da função Convert dará exatamente o resultado que precisamos. 5. O conceito de chaves Ao declarar o esquema de uma relação base, podem ser fornecidas declarações de várias chaves. Já encontramos isso muitas vezes antes. Finalmente, é hora de falar com mais detalhes sobre o que são as chaves de relacionamento, e não se limitar a frases gerais e definições aproximadas. Então, vamos dar uma definição estrita de uma chave de relação. Chave do esquema de relacionamento é um subesquema do esquema original, consistindo em um ou mais atributos para os quais é declarado condição de exclusividade valores em tuplas de relacionamento. Para entender o que é a condição de unicidade, ou, como também é chamada, restrição única, vamos começar com a definição de uma tupla e a operação unária de projetar uma tupla em um subcircuito. Vamos trazê-los: t = t(S) = {t(a) | a ∈ def( t) ⊆ S} - definição de uma tupla, t(S) [S' ] = {t(a) | a ∈ def (t) ∩ S'}, S' ⊆ S é a definição da operação de projeção unária; É claro que a projeção da tupla no subesquema corresponde a uma substring da linha da tabela. Então, o que exatamente é uma restrição de exclusividade de atributo chave? A declaração da chave K para o esquema da relação S leva à formulação da seguinte condição invariante, chamada, como já dissemos, restrição de exclusividade e denotado como: Inv < K → S > r(S): Inv < K → S > r(S) = ∀t1, T2 ∈ r(t 1[K]=t2 [K] → t 1(S) =t2(S)), K ⊆ S; Então, essa restrição de unicidade Inv < K → S > r(S) da chave K significa que se quaisquer duas tuplas t1 e t2, pertencentes à relação r(S), são iguais na projeção sobre a chave K, então isso necessariamente acarreta a igualdade dessas duas tuplas e na projeção sobre todo o esquema da relação S. Em outras palavras, todos os valores das tuplas pertencentes aos atributos-chave são únicas, únicas em sua relação. E o segundo requisito importante para uma chave de relação é requisito de redundância. O que isto significa? Esse requisito significa que nenhum subconjunto estrito da chave precisa ser exclusivo. Em um nível intuitivo, fica claro que o atributo chave é aquele atributo de relação que identifica de forma única e precisa cada tupla da relação. Por exemplo, na seguinte relação dada por uma tabela:
o atributo chave é o atributo "Gradebook #", porque alunos diferentes não podem ter o mesmo número de boletim de notas, ou seja, este atributo está sujeito a uma restrição única. É interessante que no esquema de qualquer relação possa ocorrer uma variedade de chaves. Listamos os principais tipos de chaves: 1) chave simples é uma chave que consiste em um e não mais atributos. Por exemplo, em uma folha de exame para uma determinada disciplina, uma chave simples é o número do cartão de crédito, pois pode identificar exclusivamente qualquer aluno; 2) chave composta é uma chave que consiste em dois ou mais atributos. Por exemplo, uma chave composta na lista de salas de aula é o número do prédio e o número da sala de aula. Afinal, não é possível identificar de forma única cada público com um desses atributos, e é bastante fácil fazer isso com sua totalidade, ou seja, com uma chave composta; 3) superchave é qualquer superconjunto de qualquer chave. Portanto, o esquema da própria relação é certamente uma superchave. Disso podemos concluir que qualquer relação teoricamente tem pelo menos uma chave, podendo ter várias delas. No entanto, declarar uma superchave no lugar de uma chave normal é logicamente ilegal, pois envolve relaxar a restrição de exclusividade imposta automaticamente. Afinal, a superchave, embora tenha a propriedade de unicidade, não tem a propriedade de não redundância; 4) chave primária é simplesmente a chave que foi declarada primeiro quando a relação base foi definida. É importante que uma e apenas uma chave primária seja declarada. Além disso, os atributos de chave primária nunca podem assumir valores nulos. Ao criar uma relação base em uma entrada de pseudocódigo, a chave primária é denotada chave primária e entre colchetes está o nome do atributo, que é essa chave; 5) chaves candidatas são todas as outras chaves declaradas após a chave primária. Quais são as principais diferenças entre chaves candidatas e chaves primárias? Primeiro, pode haver várias chaves candidatas, enquanto a chave primária, como mencionado acima, pode ser apenas uma. E, em segundo lugar, se os atributos da chave primária não podem assumir valores nulos, essa condição não é imposta aos atributos das chaves candidatas. Em pseudocódigo, ao definir uma relação de base, as chaves candidatas são declaradas usando as palavras Chave candidata e entre colchetes a seguir, como no caso de declarar uma chave primária, é indicado o nome do atributo, que é a chave candidata dada; 6) chave externa é uma chave declarada em uma relação de base que também se refere a uma chave primária ou candidata da mesma ou de alguma outra relação de base. Nesse caso, o relacionamento ao qual a chave estrangeira se refere é chamado de referência (ou pai) atitude. Uma relação que contém uma chave estrangeira é chamada filho. Em pseudocódigo, a chave estrangeira é denotada como chave estrangeira, entre parênteses imediatamente após essas palavras, é indicado o nome do atributo dessa relação, que é uma chave estrangeira, e após isso a palavra-chave é escrita referências ("refere-se a") e especifique o nome da relação de base e o nome do atributo ao qual essa chave estrangeira específica se refere. Além disso, ao criar uma relação base, para cada chave estrangeira, uma condição é escrita, chamada restrição de integridade referencial, mas falaremos sobre isso em detalhes mais tarde. Aula nº 8 O assunto desta palestra será uma discussão bastante detalhada do operador de criação de relação de base. Analisaremos o próprio operador em um registro de pseudocódigo, analisaremos todos os seus componentes e seu trabalho e analisaremos os métodos de modificação, ou seja, alterando as relações básicas. 1. Símbolos metalinguísticos Ao descrever as construções sintáticas usadas na escrita do operador de criação da relação base em pseudocódigo, vários métodos são usados. símbolos metalinguísticos. Esses são todos os tipos de colchetes de abertura e fechamento, várias combinações de pontos e vírgulas, em uma palavra, símbolos que cada um carrega seu próprio significado e facilitam para o programador escrever código. Vamos apresentar e explicar o significado dos principais símbolos metalinguísticos mais usados no desenho de relações básicas. Então: 1) caráter metalinguístico "{}". Construções sintáticas em chaves são obrigatório unidades sintáticas. Ao definir uma relação de base, os elementos necessários são, por exemplo, atributos de base; sem declarar atributos básicos, nenhum relacionamento pode ser projetado. Portanto, ao escrever o operador de criação da relação base em pseudocódigo, os atributos base são listados entre chaves; 2) o símbolo metalinguístico "[]". Nesse caso, o oposto é verdadeiro: as construções de sintaxe entre colchetes representam opcional elementos de sintaxe. As unidades sintáticas opcionais no operador de criação da relação base, por sua vez, são os atributos virtuais das chaves primária, candidata e estrangeira. Aqui, é claro, também há sutilezas, mas falaremos sobre elas mais tarde, quando passarmos diretamente ao projeto do operador para criar a relação de base; 3) símbolo metalinguístico "|". Este símbolo significa literalmente "ou", como o símbolo análogo na matemática. A utilização deste símbolo metalinguístico implica a escolha entre duas ou mais construções separadas, respectivamente, por este símbolo; 4) símbolo metalinguístico “…”. Uma reticência colocada imediatamente após qualquer unidade sintática significa a possibilidade repetições esses elementos sintáticos que antecedem o símbolo metalinguístico; 5) símbolo metalinguístico ",..". Este símbolo significa quase o mesmo que o anterior. Somente ao utilizar o símbolo metalinguístico ",..", reiteração construções sintáticas ocorrem separados por vírgulasque muitas vezes é muito mais conveniente. Com isso em mente, podemos falar sobre a equivalência das duas construções sintáticas a seguir: unidade [, unidade]... и unidade,.. ; 2. Um exemplo de criação de um relacionamento básico em uma entrada de pseudocódigo Agora que esclarecemos os significados dos principais símbolos metalinguísticos usados ao escrever o operador de criação da relação de base em pseudocódigo, podemos prosseguir para a consideração propriamente dita desse operador. Como pode ser entendido a partir das referências acima, o operador para criar uma relação de base na entrada de pseudocódigo inclui declarações de atributos de base e virtuais, chaves primárias, candidatas e estrangeiras. Além disso, como será mostrado e explicado acima, esse operador também abrange restrições de valor de atributo e restrições de tupla, bem como as chamadas restrições de integridade referencial. As duas primeiras restrições, ou seja, a restrição de valor de atributo e a restrição de tupla, são declaradas após a palavra reservada especial verificar. As restrições de integridade referencial podem ser de dois tipos: em atualização, que significa "ao atualizar", e ao excluir, que significa "na exclusão". O que isto significa? Isso significa que ao atualizar ou excluir atributos de relacionamentos referenciados por uma chave estrangeira, a integridade do estado deve ser mantida. (Falaremos mais sobre isso mais tarde.) O próprio operador de criação de relação base é utilizado por nós já estudados - o operador Crie, apenas para criar um relacionamento básico, a palavra-chave é adicionada mesa ("atitude"). E, é claro, como a relação em si é maior e inclui todas as construções discutidas anteriormente, bem como novas construções adicionais, o operador create será bastante impressionante. Então, vamos escrever em pseudocódigo a forma geral do operador usado para criar relações básicas: Criar tabela nome da relação base { nome do atributo base tipo de valor de atributo básico verificar (limite de valor de atributo) {Nulo | não nulo} omissão (valor padrão) },.. [nome do atributo virtual as (Fórmula de cálculo) ],.. [,verificar (restrição de tupla)] [,chave primária (Nome do Atributo,..)] [,Chave candidata (Nome do Atributo,..)]... [,chave estrangeira (Nome do Atributo,..) referências nome da relação de referência (nome do atributo, ..) na atualização { Restringir | Cascata | Definir Nulo} ao excluir { Restringir | Cascata | Definir Nulo} ] ... Assim, vemos que vários atributos básicos e virtuais, chaves candidatas e estrangeiras podem ser declarados, pois após as construções sintáticas correspondentes existe um símbolo metalinguístico ",.." Após a declaração da chave primária, este símbolo não está presente, pois as relações de base, conforme mencionado anteriormente, permitem apenas uma chave primária. Em seguida, vamos dar uma olhada no mecanismo de declaração. atributos básicos. Ao descrever qualquer atributo no operador de criação de relação base, no caso geral, seu nome, tipo, restrições em seus valores, sinalizador de validade de valores nulos e valores padrão são especificados. É fácil perceber que o tipo de um atributo e suas restrições de valor determinam seu domínio, ou seja, literalmente o conjunto de valores válidos para aquele determinado atributo. Restrição de valor de atributo é escrito como uma condição dependente do nome do atributo. Aqui está um pequeno exemplo para tornar este material mais fácil de entender: Criar tabela nome da relação base Curso número inteiro verificar (1 <= Curso e Curso <= 5; Aqui, a condição "1 <= Cabeçalho e Cabeçalho <= 5" juntamente com a definição de um tipo de dados inteiro realmente condiciona completamente o conjunto de valores permitidos do atributo, ou seja, literalmente seu domínio. O sinalizador de permissão de valores Nulos (Null | not Null) proíbe (não Null) ou, inversamente, permite (Null) o aparecimento de valores Null entre os valores de atributo. Tomando o exemplo que acabamos de discutir, o mecanismo para aplicar sinalizadores de validade nula é o seguinte: Criar tabela nome da relação base Curso número inteiro verificar (1 <= Curso e Curso <= 5); Não nulo; Portanto, o número do curso de um aluno nunca pode ser nulo, não pode ser desconhecido para compiladores de banco de dados e não pode não existir. Valores padrão (omissão (valor padrão)) são usados ao inserir uma tupla em um relacionamento se os valores dos atributos não estiverem definidos explicitamente na instrução insert. É interessante notar que os valores padrão também podem ser valores Nulos, desde que os valores Nulos para aquele determinado atributo sejam declarados válidos. Agora considere a definição atributo virtual no operador de criação da relação base. Como dissemos anteriormente, definir um atributo virtual consiste em definir fórmulas para seu cálculo através de outros atributos base. Vamos considerar um exemplo de declaração de um atributo virtual "Cost Rub". na forma de uma fórmula dependendo dos atributos básicos "Peso Kg" e "Preço Rub. por Kg". Criar tabela nome da relação base Peso, kg tipo de valor de atributo básico Peso Kg verificar (restrição do valor do atributo Peso Kg) não nulo omissão (valor padrão) Preço, esfregue. por kg tipo de valor do atributo base Price Rub. por kg verificar (limitação do valor do atributo Price Rub. por Kg) não nulo omissão (valor padrão) ... Custo, esfregue. as (Peso Kg * Preço Rub. por Kg) Um pouco antes, examinamos as restrições de atributo, que foram escritas como condições dependentes dos nomes dos atributos. Agora considere o segundo tipo de restrições declaradas ao criar uma relação de base, a saber restrições de tupla. O que é uma restrição de tupla, como ela é diferente de uma restrição de atributo? Uma restrição de tupla também é escrita como uma condição dependente do nome do atributo base, mas somente no caso de uma restrição de tupla, a condição pode depender de vários nomes de atributo ao mesmo tempo. Considere um exemplo que ilustra o mecanismo de trabalho com restrições de tupla: Criar tabela nome da relação base Peso mín. Kg valor tipo de atributo base min Peso Kg verificar (restrição do valor do atributo min Peso Kg) não nulo omissão (valor padrão) Peso máximo Kg tipo de valor do atributo base máx. Peso Kg verificar (restrição do valor do atributo Max Peso Kg) não nulo omissão (valor padrão) verificar (0 < min Peso Kg e min Peso Kg < max Peso Kg); Assim, aplicar uma restrição a uma tupla equivale a substituir os valores da tupla por nomes de atributos. Vamos passar a considerar o operador de criação de relação de base. Uma vez declarados, os atributos base e virtual podem ou não ser declarados. chaves: primário, candidato e externo. Como dissemos anteriormente, o subesquema de uma relação de base que em outra (ou na mesma) relação de base corresponde a uma chave primária ou candidata no contexto da primeira relação é chamado chave estrangeira. As chaves estrangeiras representam mecanismo de link tuplas de algumas relações sobre tuplas de outras relações, ou seja, existem declarações de chaves estrangeiras associadas à imposição das chamadas já mencionadas restrições de integridade referencial. (Esta restrição será o foco da próxima aula, uma vez que a integridade do estado (ou seja, a integridade imposta pelas restrições de integridade) é crítica para o sucesso da relação base e de todo o banco de dados.) A declaração de chaves primárias e candidatas, por sua vez, impõe as restrições de exclusividade apropriadas no esquema de relação de base, que discutimos anteriormente. E, por fim, deve-se dizer sobre a possibilidade de deletar a relação de base. Muitas vezes, na prática de projeto de banco de dados, é necessário remover uma antiga relação desnecessária para não sobrecarregar o código do programa. Isso pode ser feito usando o operador já familiar Cair. Em sua forma geral completa, o operador delete da relação base se parece com isso: Soltar tabela o nome da relação de base; 3. Restrição de integridade por estado Restrição de integridade objeto de dados relacionais a partir de é o chamado invariante de dados. Ao mesmo tempo, a integridade deve ser distinguida com segurança da segurança, que, por sua vez, implica a proteção dos dados contra o acesso não autorizado a eles para divulgar, modificar ou destruir dados. Em geral, as restrições de integridade em objetos de dados relacionais são classificadas por níveis de hierarquia esses mesmos objetos de dados relacionais (a hierarquia de objetos de dados relacionais é uma sequência de conceitos aninhados: "atributo - tupla - relação - banco de dados"). O que isto significa? Isso significa que as restrições de integridade dependem de: 1) no nível de atributo - a partir de valores de atributo; 2) no nível da tupla - dos valores da tupla, ou seja, dos valores de vários atributos; 3) no nível das relações - de uma relação, ou seja, de várias tuplas; 4) no nível do banco de dados - de vários relacionamentos. Então, agora só nos resta considerar com mais detalhes as restrições de integridade no estado de cada um dos conceitos acima. Mas primeiro, vamos dar os conceitos de suporte processual e declarativo para restrições de integridade de estado. Assim, o suporte para restrições de integridade pode ser de dois tipos: 1) processual, ou seja, criado escrevendo código de programa; 2) declarativo, ou seja, criado pela declaração de certas restrições para cada um dos conceitos aninhados acima. O suporte declarativo para restrições de integridade é implementado no contexto da instrução Create para criar a relação de base. Vamos falar sobre isso com mais detalhes. Vamos começar considerando o conjunto de restrições a partir da base da nossa escada hierárquica de objetos de dados relacionais, ou seja, a partir do conceito de atributo. Restrição de nível de atributo inclui: 1) restrições quanto ao tipo de valores de atributos. Por exemplo, uma condição inteira para valores, ou seja, uma condição inteira para o atributo "Curso" de uma das relações básicas discutidas anteriormente; 2) uma restrição de valor de atributo, escrita como uma condição dependente do nome do atributo. Por exemplo, analisando a mesma relação básica do parágrafo anterior, vemos que nessa relação também há uma restrição nos valores dos atributos usando a opção verificar, ou seja: verificar (1 <= Curso e Curso <= 5); 3) A restrição de nível de atributo inclui restrições de valor nulo definidas pelo sinalizador bem conhecido de validade (nulo) ou, inversamente, inadmissibilidade (não nulo) de valores nulos. Como mencionamos anteriormente, as duas primeiras restrições definem a restrição de domínio do atributo, ou seja, o valor de seu conjunto de definições. Além disso, de acordo com a escada hierárquica de objetos de dados relacionais, precisamos falar sobre tuplas. Então, restrição de nível de tupla se reduz a uma restrição de tupla e é escrita como uma condição que depende dos nomes de vários atributos básicos do esquema de relação, ou seja, essa restrição de integridade de estado é muito menor e mais simples que a similar, correspondendo apenas ao atributo. E novamente, seria útil relembrar o exemplo da relação básica que passamos anteriormente, que tem a restrição de tupla que precisamos agora, a saber: verificar (0 < min Peso Kg e min Peso Kg < max Peso Kg); E, finalmente, o último conceito significativo no contexto da restrição de integridade do estado é o conceito de nível de relacionamento. Como dissemos antes, restrição de nível de relacionamento inclui limitar os valores do primário (chave primária) e candidato (Chave candidata) chaves. É curioso que as restrições impostas aos bancos de dados não sejam mais restrições de integridade de estado, mas restrições de integridade referencial. 4. Restrições de Integridade Referencial Assim, a restrição de nível de banco de dados inclui a restrição de integridade referencial de chave estrangeira (chave estrangeira). Já mencionamos isso brevemente quando falamos sobre restrições de integridade referencial ao criar um relacionamento de base e chaves estrangeiras. Agora é hora de falar sobre esse conceito com mais detalhes. Como dissemos antes, a chave estrangeira da relação base declarada refere-se à chave primária ou candidata de alguma outra relação base (na maioria das vezes). Lembre-se que neste caso, a relação referenciada pela chave estrangeira é chamada referência ou parental, porque meio que "gera" um atributo ou vários atributos na relação base de referência. E, por sua vez, uma relação contendo uma chave estrangeira é chamada filho, também por razões óbvias. O que é restrição de integridade referencial? E consiste no fato de que cada valor da chave estrangeira do relacionamento filho deve necessariamente corresponder ao valor de qualquer chave do relacionamento pai, a menos que o valor da chave estrangeira contenha valores nulos em quaisquer atributos. Tuplas de uma relação filha que violam essa condição são chamadas pendurado. De fato, se a chave estrangeira da relação filho se refere a um atributo que não existe na relação pai, então ela não se refere a nada. São justamente essas situações que devem ser evitadas de todas as formas possíveis, e isso significa manter a integridade referencial. Mas, sabendo que nenhum banco de dados jamais permitirá a criação de uma tupla pendente, os desenvolvedores garantem que não haja tuplas pendentes inicialmente no banco de dados e que todas as chaves disponíveis se refiram a um atributo muito real do relacionamento pai. No entanto, existem situações em que tuplas pendentes são formadas já durante a operação do banco de dados. Quais são essas situações? Sabe-se que quando as tuplas são removidas da relação pai ou quando o valor da chave de uma tupla da relação pai é atualizado, a integridade referencial pode ser violada, ou seja, podem ocorrer tuplas pendentes. Para excluir a possibilidade de sua ocorrência ao declarar um valor de chave estrangeira, é especificado um dos seguintes: três disponível regras mantendo a integridade referencial, aplicada de acordo ao atualizar o valor da chave na relação pai (ou seja, como mencionamos anteriormente, em atualização) ou ao remover uma tupla da relação pai (ao excluir). Deve-se notar que adicionar uma nova tupla ao relacionamento pai não pode quebrar a integridade referencial, por razões óbvias. Afinal, se essa tupla fosse apenas adicionada à relação base, nenhum atributo poderia se referir a ela antes por causa de sua ausência! Então, quais são essas três regras que são usadas para manter a integridade referencial em bancos de dados? Vamos listá-los. 1. restringirOu regra de restrição. Se, ao definir nossa relação base, ao declarar chaves estrangeiras em uma restrição de integridade referencial, aplicarmos essa regra de mantê-la, atualizar uma chave na relação pai ou excluir uma tupla da relação pai simplesmente não pode ser executada se essa tupla for referenciado por pelo menos uma tupla da relação filho, ou seja, operação restringir proíbe totalmente a execução de quaisquer ações que possam levar ao aparecimento de tuplas suspensas. Ilustramos a aplicação dessa regra com o exemplo a seguir. Sejam dadas duas relações: Atitude dos pais
relação infantil
Vemos que as tuplas de relação filho (2,...) e (2,...) referem-se à tupla de relação pai (..., 2), e a tupla de relação filho (3,...) refere-se a a (..., 3) atitude parental. A tupla (100,...) da relação filho está pendente e não é válida. Aqui, apenas as tuplas da relação pai (..., 1) e (..., 4) permitem que os valores-chave sejam atualizados e as tuplas sejam excluídas porque não são referenciadas por nenhuma das chaves estrangeiras da relação filho. Vamos compor o operador para criar uma relação básica, que inclui a declaração de todas as chaves acima: Criar tabela Atitude dos pais Chave primária Número inteiro não nulo chave primária (Chave primária) Criar tabela relação infantil Chave_estrangeira Número inteiro Nulo chave estrangeira (Chave_estrangeira) referências Relacionamento pai (chave_primária) na atualização Restringir excluir Restringir 2. CascataOu regra de modificação em cascata. Se, ao declarar chaves estrangeiras em nossa relação base, usamos a regra de manter a integridade referencial Cascata, a atualização de uma chave na relação pai ou a exclusão de uma tupla da relação pai faz com que as chaves e tuplas correspondentes da relação filha sejam atualizadas ou excluídas automaticamente. Vejamos um exemplo para entender melhor como funciona a regra de modificação em cascata. Sejam dadas as relações básicas que já nos são familiares do exemplo anterior: Atitude dos pais
и relação infantil
Suponha que atualizemos algumas tuplas na tabela que define o relacionamento “Relação pai”, ou seja, substituímos a tupla (..., 2) pela tupla (..., 20), ou seja, obtemos uma nova relação: Atitude dos pais
E vamos ao mesmo tempo na declaração de criar nossa relação base "Relação filho" ao declarar chaves estrangeiras, usamos a regra de manter a integridade referencial Cascata, ou seja, o operador para criar nosso relacionamento base se parece com isso: Criar tabela Atitude dos pais Chave primária Número inteiro não nulo chave primária (Chave primária) Criar tabela relação infantil Chave_estrangeira Número inteiro Nulo chave estrangeira (Chave_estrangeira) referências Relacionamento pai (chave_primária) na atualização Cascade ao excluir Cascata Então, o que acontece com a relação filho quando a relação pai é atualizada da maneira descrita acima? Terá o seguinte formato: relação infantil
Assim, de fato, a regra Cascata fornece uma atualização em cascata de todas as tuplas na relação filho em resposta a atualizações na relação pai. 3. Definir nuloOu regra de atribuição nula. Se, na declaração de criação de nossa relação base, ao declarar chaves estrangeiras, aplicarmos a regra de manter a integridade referencial Definir nulo, atualizar a chave de uma relação pai ou excluir uma tupla de uma relação pai implica atribuir automaticamente valores Nulos aos atributos de chave estrangeira da relação filho que permitem valores Nulos. Portanto, a regra é aplicável se tais atributos existirem. Vejamos um exemplo que já usamos antes. Suponha que nos sejam dadas duas relações básicas: "Paternidade"
relação infantil
Como você pode ver, os atributos da relação filho permitem valores nulos, daí a regra Definir nulo aplicável neste caso específico. Suponhamos agora que a tupla (..., 1) foi removida da relação pai e a tupla (..., 2) foi atualizada, como no exemplo anterior. Assim, a relação pai assume a seguinte forma: Atitude dos pais
Então, levando em consideração o fato de que ao declarar as chaves estrangeiras da relação filho, aplicamos a regra de manter a integridade referencial Definir nulo, a relação filho ficará assim: relação infantil
A tupla (..., 1) não foi referenciada por nenhuma chave de relação filho, portanto, excluí-la não tem consequências. O próprio operador de criação da relação base usando a regra Definir nulo ao declarar chaves estrangeiras, o relacionamento se parece com isso: Criar tabela Atitude dos pais Chave primária Número inteiro não nulo chave primária (Chave primária) Criar tabela relação infantil Chave_estrangeira Número inteiro Nulo chave estrangeira (Chave_estrangeira) referências Relacionamento pai (chave_primária) na atualização Definir Nulo ao excluir Definir Nulo Assim, vemos que a presença de três regras diferentes para manter a integridade referencial garante que em frases em atualização и ao excluir funções podem variar. Deve ser lembrado e entendido que a inserção de tuplas em uma relação filho ou a atualização dos valores-chave das relações filho não será realizada se isso levar a uma violação da integridade referencial, ou seja, ao aparecimento das chamadas tuplas pendentes. A remoção de tuplas de uma relação filho sob nenhuma circunstância pode levar a uma violação da integridade referencial. É interessante que uma relação filho possa atuar simultaneamente como pai com suas próprias regras para manter a integridade referencial, se as chaves estrangeiras de outras relações de base se referirem a alguns de seus atributos como chaves primárias. Se os programadores quiserem garantir que a integridade referencial seja imposta por algumas regras diferentes das regras padrão acima, o suporte processual para essas regras não padronizadas para manter a integridade referencial é fornecido com a ajuda dos chamados gatilhos. Infelizmente, uma consideração detalhada deste conceito não desce em nosso curso de palestras. 5. O conceito de índices A criação de chaves em relacionamentos de base é automaticamente vinculada à criação de índices. Vamos definir a noção de um índice. Índice - esta é uma estrutura de dados do sistema que contém uma lista necessariamente ordenada de valores de uma chave com links para essas tuplas da relação em que esses valores ocorrem. Existem dois tipos de índices em sistemas de gerenciamento de banco de dados: 1) simples. Um índice simples é obtido para um subesquema de esquema da relação base de um único atributo; 2) composto. Assim, um índice composto é um índice para um subesquema que consiste em vários atributos. Mas, além da divisão em índices simples e compostos, nos sistemas de gerenciamento de banco de dados há uma divisão dos índices em únicos e não exclusivos. Então: 1) único índices são índices referentes a no máximo um atributo. Índices únicos geralmente correspondem à chave primária da relação; 2) não exclusivo índices são índices que podem corresponder a vários atributos ao mesmo tempo. As chaves não exclusivas, por sua vez, correspondem na maioria das vezes às chaves estrangeiras do relacionamento. Considere um exemplo ilustrando a divisão de índices em únicos e não únicos, ou seja, considere os seguintes relacionamentos definidos por tabelas:
Aqui, respectivamente, Chave primária é a chave primária do relacionamento, Chave estrangeira é a chave estrangeira. Fica claro que nestas relações, o índice do atributo Chave Primária é único, pois corresponde à chave primária, ou seja, um atributo, e o índice do atributo Chave Estrangeira não é único, pois corresponde a chave estrangeira chaves. E seu valor "20" corresponde tanto à primeira quanto à terceira linha da tabela de relações. Mas às vezes os índices podem ser criados sem levar em conta as chaves. Isso é feito em sistemas de gerenciamento de banco de dados para dar suporte ao desempenho de operações de classificação e pesquisa. Por exemplo, uma busca dicotômica por um valor de índice em tuplas será implementada em sistemas de gerenciamento de banco de dados em vinte iterações. De onde veio essa informação? Eles foram obtidos por cálculos simples, ou seja, da seguinte forma: 106 = (103)2 = 220; Os índices são criados em sistemas de gerenciamento de banco de dados usando a instrução Create já conhecida por nós, mas apenas com a adição da palavra-chave index. Tal operador se parece com isso: Criar índice nome do índice On nome da relação base (nome do atributo,..); Aqui vemos o familiar símbolo metalinguístico ",.." denotando a possibilidade de repetir um argumento separado por uma vírgula, ou seja, um índice correspondente a vários atributos pode ser criado neste operador. Se você quiser declarar um índice exclusivo, adicione a palavra-chave exclusiva antes da palavra de índice e, em seguida, toda a instrução de criação na relação de índice base se torna: Crie um índice único nome do índice On nome da relação base (nome do atributo); Então, na forma mais geral, se lembrarmos da regra para designar elementos opcionais (o símbolo metalinguístico []), o operador de criação de índice na relação básica ficará assim: Criar índice [único] nome do índice On nome da relação base (nome do atributo,..); Se você deseja remover um índice já existente da relação base, use o operador Drop, também já conhecido por nós: Índice de queda {nome da relação base. Nome do índice},.. ; Por que o nome do índice qualificado "nome da relação base. Nome do índice" é usado aqui? Um operador de descarte de índice sempre usa seu nome qualificado porque o nome do índice deve ser exclusivo dentro do mesmo relacionamento, mas não mais. 6. Modificação das relações básicas Para trabalhar com sucesso e produtividade com vários relacionamentos de base, muitas vezes os desenvolvedores precisam modificar esse relacionamento de base de alguma forma. Quais são as principais opções de modificação exigidas mais frequentemente encontradas na prática de design de banco de dados? Vamos listá-los: 1) inserção de tuplas. Muitas vezes você precisa inserir novas tuplas em uma relação de base já formada; 2) atualizar os valores dos atributos. E a necessidade dessa modificação na prática de programação é ainda mais comum que a anterior, pois quando chegam novas informações sobre os argumentos do seu banco de dados, inevitavelmente você terá que atualizar algumas informações antigas; 3) remoção de tuplas. E com probabilidade aproximadamente igual, torna-se necessário remover da relação base aquelas tuplas cuja presença em seu banco de dados não é mais necessária devido a novas informações recebidas. Assim, delineamos os principais pontos de modificação das relações básicas. Como cada um desses objetivos pode ser alcançado? Em sistemas de gerenciamento de banco de dados, na maioria das vezes há operadores básicos de modificação de relacionamento embutidos. Vamos descrevê-los em uma entrada de pseudocódigo: 1) operador de inserção na relação de base das novas tuplas. Este é o operador inserção. Se parece com isso: Inserir em nome da relação base (nome do atributo, ..) Valores (Valor do atributo,..); O símbolo metalinguístico ",.." após o nome do atributo e o valor do atributo nos diz que este operador permite que vários atributos sejam adicionados à relação base ao mesmo tempo. Nesse caso, você deve listar os nomes dos atributos e os valores dos atributos, separados por vírgulas, em uma ordem consistente. Palavra-chave para dentro em combinação com o nome geral do operador inserção significa "inserir em" e indica em qual relação os atributos entre parênteses devem ser inseridos. Palavra-chave Valores nesta declaração, e significa "valores", "valores", que são atribuídos a esses atributos recém-declarados; 2) agora considere operador de atualização valores de atributo na relação base. Este operador é chamado Atualizar, que é traduzido do inglês e significa literalmente "atualizar". Vamos dar a forma geral completa desse operador em uma notação de pseudocódigo e decifrá-lo: Atualizar nome da relação base Conjunto {nome do atributo - valor do atributo},.. Onde doença; Então, na primeira linha do operador após a palavra-chave Atualizar o nome da relação base na qual as atualizações devem ser feitas é escrito. A palavra-chave Set é traduzida do inglês como "set", e esta linha da instrução especifica os nomes dos atributos a serem atualizados e os novos valores de atributo correspondentes. É possível atualizar vários atributos de uma só vez em uma declaração, que decorre do uso do símbolo metalinguístico ",..". Na terceira linha após a palavra-chave Onde uma condição é escrita mostrando exatamente quais atributos desta relação de base precisam ser atualizados; 3) operador Apagarpermitindo remover quaisquer tuplas da relação de base. Vamos escrever sua forma completa em pseudocódigo e explicar o significado de todas as unidades sintáticas individuais: Excluir de nome da relação base Onde doença; Palavra-chave da combinado com o nome do operador Apagar traduz como "remover de". E após essas palavras-chave na primeira linha do operador, é indicado o nome da relação base, da qual quaisquer tuplas devem ser removidas. E na segunda linha do operador após a palavra-chave Onde ("onde") indica a condição pela qual as tuplas são selecionadas que não são mais necessárias em nossa relação base. Aula número 9. Dependências funcionais 1. Restrição de dependência funcional A restrição de exclusividade imposta pelas declarações de chave primária e candidata de uma relação é um caso especial da restrição associada à noção dependências funcionais. Para explicar o conceito de dependência funcional, considere o exemplo a seguir. Vamos receber uma relação contendo dados sobre os resultados de uma determinada sessão. O esquema desse relacionamento fica assim: Sessão (número do livro de registro, Nome completo, Assunto, Avaliar); Os atributos "Número do boletim de notas" e "Assunto" formam uma chave primária composta (já que dois atributos são declarados como chave) desta relação. De fato, esses dois atributos podem determinar exclusivamente os valores de todos os outros atributos. No entanto, além da restrição de exclusividade associada a essa chave, a relação deve necessariamente estar sujeita à condição de que um boletim de notas seja emitido para uma determinada pessoa e, portanto, a esse respeito, as tuplas com o mesmo número de boletim de notas devem conter os mesmos valores dos atributos "Sobrenome", "Nome e nome do meio".
Se tivermos o seguinte fragmento de um determinado banco de dados de alunos de uma instituição educacional após uma determinada sessão, em tuplas com um número de notas de 100, os atributos "Sobrenome", "Nome" e "Patronímico" são os mesmos, e os atributos "Assunto" e "Avaliação" - não coincidem (o que é compreensível, pois estão falando de assuntos e desempenhos diferentes neles). Isso significa que os atributos "Sobrenome", "Nome" e "Patronímico" funcionalmente dependente no atributo "Número do boletim de notas", enquanto os atributos "Assunto" e "Avaliação" são funcionalmente independentes. Assim, o dependência funcional é uma dependência de valor único tabulada em sistemas de gerenciamento de banco de dados. Damos agora uma definição rigorosa de dependência funcional. Definição: sejam X, Y subesquemas do esquema da relação S, definindo sobre o esquema S diagrama de dependência funcional X → Y (leia "seta X Y"). Vamos definir restrições de dependência funcional inv<X → Y> como uma declaração de que, em relação ao esquema S, quaisquer duas tuplas que correspondam na projeção no subesquema X também devem corresponder na projeção ao subesquema Y. Vamos escrever a mesma definição na forma de fórmula: Inv<X → Y> r(S) = t1, T2 ∈ r(t1[X] =t2[X] ⇒ t1[S]=t2 [Y]), X, Y ⊆ S; Curiosamente, essa definição usa o conceito de operação de projeção unária, que encontramos anteriormente. De fato, de que outra forma, se você não usar esta operação, para mostrar a igualdade de duas colunas da tabela de relações, e não linhas, entre si? Portanto, escrevemos em termos desta operação que a coincidência de tuplas na projeção sobre algum atributo ou vários atributos (subesquema X) certamente acarretará a coincidência das mesmas colunas-tuplas no subesquema Y caso Y seja funcionalmente dependente de X. É interessante notar que no caso de uma dependência funcional de Y em X, também se diz que X define funcionalmente S ou o que S funcionalmente dependente em X. No esquema de dependência funcional X → Y, o subcircuito X é chamado de lado esquerdo e o subcircuito Y é chamado de lado direito. Na prática de projeto de banco de dados, o esquema de dependência funcional é comumente referido como dependência funcional para abreviar. Fim da definição. No caso especial, quando o lado direito da dependência funcional, ou seja, o subesquema Y, corresponde a todo o esquema do relacionamento, a restrição de dependência funcional se torna uma restrição de exclusividade de chave primária ou candidata. Sério: inv r(S) = ∀ t1, T2 ∈ r(t1[K] =t2 [K] → t1(S) =t2(S)), K ⊆ S; É só que ao definir uma dependência funcional, ao invés do subesquema X, você precisa pegar a designação da chave K, e ao invés do lado direito da dependência funcional, subesquema Y, pegar todo o esquema de relações S, ou seja, de fato, a restrição à unicidade das chaves de relações é um caso especial de restrição de dependência funcional quando o lado direito é igual a esquemas de dependência funcional em todo o esquema de relacionamento. Aqui estão alguns exemplos da imagem de dependência funcional: {Número do livro de contas} → {Sobrenome, Nome, Patronímico}; {número do boletim de notas, assunto} → {nota}; 2. Regras de inferência de Armstrong Se qualquer relação básica satisfaz dependências funcionais definidas por vetores, então com a ajuda de várias regras de inferência especiais é possível obter outras dependências funcionais que esta relação básica certamente irá satisfazer. Um bom exemplo dessas regras especiais são as regras de inferência de Armstrong. Mas antes de prosseguirmos com a análise das próprias regras de inferência de Armstrong, vamos introduzir um novo símbolo metalinguístico "├", que se chama símbolo de meta-afirmação de derivabilidade. Este símbolo, ao formular regras, é escrito entre duas expressões sintáticas e indica que a fórmula à sua direita é derivada da fórmula à sua esquerda. Vamos agora formular as próprias regras de inferência de Armstrong na forma do seguinte teorema. Teorema. As seguintes regras são válidas, chamadas regras de inferência de Armstrong. Regra de Inferência 1. ├ X → X; Regra de Inferência 2. X → Y├ X ∪ Z → Y; Regra de Inferência 3. X → Y, Y ∪ W → Z ├ X ∪ W → Z; Aqui X, Y, Z, W são subesquemas arbitrários do esquema da relação S. O símbolo de meta-enunciado de derivabilidade separa listas de premissas e listas de asserções (conclusões). 1. A primeira regra de inferência é chamada de "reflexividade" e diz o seguinte: "a regra é deduzida:" X implica funcionalmente X "". Esta é a mais simples das regras de derivação de Armstrong. Ela é derivada literalmente do nada. É interessante notar que uma dependência funcional que tem ambas as partes esquerda e direita é chamada reflexivo. De acordo com a regra da reflexividade, a restrição da dependência reflexiva é realizada automaticamente. 2. A segunda regra de inferência é chamada de "reposição" e diz o seguinte: "se X determina funcionalmente Y, então a regra é derivada: "a união dos subcircuitos X e Z implica funcionalmente Y". A regra de conclusão permite expandir o lado esquerdo da restrição de dependência funcional. 3. A terceira regra de inferência é chamada de "pseudotransitividade" e diz o seguinte: "se o subcircuito X implica funcionalmente o subcircuito Y, e a união dos subcircuitos Y e W implica funcionalmente Z, então a regra é derivada: "a união dos subcircuitos X e W determina funcionalmente o subcircuito Z"". A regra de pseudotransitividade generaliza a regra de transitividade correspondente ao caso especial W: = 0. Vamos dar uma notação formal desta regra: X→Y, Y→Z ├X→Z. Deve-se notar que as premissas e conclusões dadas anteriormente foram apresentadas de forma abreviada pelas designações de esquemas de dependência funcional. Na forma estendida, eles correspondem às seguintes restrições de dependência funcional. Regra de Inferência 1. inv r(S); Regra de Inferência 2. inv r(S) ⇒ inv r(S); Regra de Inferência 3. inv r(S) & inv r(S) ⇒ inv r(S); Desenhar evidência essas regras de inferência. 1. Prova da regra reflexividade segue diretamente da definição da restrição de dependência funcional quando o subesquema X é substituído pelo subcircuito Y. De fato, tome a restrição de dependência funcional: inv r(S) e substituir X em vez de Y, obtemos: inv r(S), e esta é a regra da reflexividade. A regra da reflexividade está provada. 2. Prova da regra reposição Vamos ilustrar em diagramas de dependência funcional. O primeiro diagrama é o diagrama do pacote: premissa: X → Y
Segundo diagrama: conclusão: X ∪ Z → Y
Sejam as tuplas iguais em X ∪ Z. Então elas são iguais em X. De acordo com a premissa, elas serão iguais em Y também. A regra de reabastecimento é comprovada. 3. Prova da regra pseudotransitividade também vamos ilustrar em diagramas, que neste caso em particular serão três. O primeiro diagrama é a primeira premissa: premissa 1: X → Y
premissa 2: Y ∪ W → Z
E, finalmente, o terceiro diagrama é o diagrama de conclusão: conclusão: X ∪ W → Z
Sejam as tuplas iguais em X ∪ W. Então elas são iguais tanto em X quanto em W. De acordo com a Premissa 1, elas também serão iguais em Y. Portanto, de acordo com a Premissa 2, elas serão iguais em Z também. A regra da pseudotransitividade está provada. Todas as regras são comprovadas. 3. Regras de inferência derivadas Outro exemplo de regras pelas quais se pode, se necessário, derivar novas regras de dependência funcional são as chamadas regras de inferência derivadas. Quais são essas regras, como elas são obtidas? Sabe-se que se outras são deduzidas de algumas regras já existentes por métodos lógicos legítimos, então essas novas regras, chamadas derivados, pode ser usado junto com as regras originais. Deve-se notar especialmente que essas regras muito arbitrárias são "derivadas" precisamente das regras de inferência de Armstrong pelas quais passamos anteriormente. Vamos formular as regras derivadas para derivar dependências funcionais na forma do seguinte teorema. Teorema As regras a seguir são derivadas das regras de inferência de Armstrong. Regra de Inferência 1. ├ X ∪ Z → X; Regra de Inferência 2. X → Y, X → Z ├ X ∪ Y → Z; Regra de Inferência 3. X → Y ∪ Z ├ X → Y, X → Z; Aqui X, Y, Z, W, como no caso anterior, são subesquemas arbitrários do esquema da relação S. 1. A primeira regra derivada é chamada regra da trivialidade e lê-se assim: "A regra é derivada: 'a união dos subcircuitos X e Z implica funcionalmente X'". Uma dependência funcional com o lado esquerdo sendo um subconjunto do lado direito é chamada trivial. De acordo com a regra da trivialidade, as restrições de dependência triviais são aplicadas automaticamente. Curiosamente, a regra da trivialidade é uma generalização da regra da reflexividade e, como esta, pode ser derivada diretamente da definição da restrição de dependência funcional. O fato de que esta regra é derivada não é acidental e está relacionado à completude do sistema de regras de Armstrong. Falaremos mais sobre a completude do sistema de regras de Armstrong um pouco mais tarde. 2. A segunda regra derivada é chamada regra de aditividade e diz o seguinte: "Se o subcircuito X determina funcionalmente o subcircuito Y, e X simultaneamente determina funcionalmente Z, então a seguinte regra é deduzida dessas regras: "X determina funcionalmente a união dos subcircuitos Y e Z"". 3. A terceira regra derivada é chamada regra de projetividade ou a regrareversão de aditividade". Lê-se da seguinte forma: "Se o subcircuito X determina funcionalmente a união dos subcircuitos Y e Z, então a seguinte regra é deduzida desta regra: "X determina funcionalmente o subcircuito Y e ao mesmo tempo X determina funcionalmente o subcircuito Z" ", ou seja, de fato, esta regra derivada é a regra de aditividade invertida. É curioso que as regras de aditividade e projetividade aplicadas às dependências funcionais com as mesmas partes esquerdas permitem combinar ou, inversamente, dividir as partes direitas da dependência. Na construção de cadeias de inferência, após formular todas as premissas, aplica-se a regra da transitividade para incluir uma dependência funcional com o lado direito na conclusão. Desenhar evidência regras de inferência arbitrárias listadas. 1. Prova da regra trivialidades. Vamos realizá-lo, como todas as provas posteriores, passo a passo: 1) temos: X → X (da regra da reflexividade da inferência de Armstrong); 2) ainda temos: X ∪ Z → X (obtido pela primeira aplicação da regra de conclusão de inferência de Armstrong, e depois como consequência do primeiro passo da prova). A regra da trivialidade foi comprovada. 2. Faremos uma prova passo a passo da regra aditividade: 1) temos: X → Y (esta é a premissa 1); 2) temos: X → Z (esta é a premissa 2); 3) temos: Y ∪ Z → Y ∪ Z (da regra da reflexividade da inferência de Armstrong); 4) temos: X ∪ Z → Y ∪ Z (obtido pela aplicação da regra da pseudotransitividade da inferência de Armstrong, e depois como consequência do primeiro e terceiro passos da prova); 5) temos: X ∪ X → Y ∪ Z (obtido pela aplicação da regra da pseudotransitividade de inferência de Armstrong, e segue da segunda e quarta etapas); 6) temos X → Y ∪ Z (segue do quinto passo). A regra da aditividade está provada. 3. E finalmente, construiremos uma prova da regra projetividade: 1) temos: X → Y ∪ Z, X → Y ∪ Z (esta é uma premissa); 2) temos: Y → Y, Z → Z (derivado usando a regra de reflexividade de inferência de Armstrong); 3) temos: Y ∪ z → y, Y ∪ z → Z (obtido da regra de conclusão de inferência de Armstrong e o corolário do segundo passo da prova); 4) temos: X → Y, X → Z (obtido pela aplicação da regra da pseudotransitividade da inferência de Armstrong, e depois como consequência do primeiro e terceiro passos da prova). A regra da projetividade está provada. Todas as regras de inferência derivadas são comprovadas. 4. Completude do sistema de regras de Armstrong Seja F(S) um dado conjunto de dependências funcionais definidas sobre o esquema de relação S. Denotado por inv a restrição imposta por este conjunto de dependências funcionais. Vamos anotá-lo: inv r(S) = ∀X → Y ∈F(S) [inv r(S)]. Assim, esse conjunto de restrições impostas pelas dependências funcionais é decifrado da seguinte forma: para qualquer regra do sistema de dependências funcionais X → Y pertencentes ao conjunto de dependências funcionais F(S), a restrição de dependências funcionais inv r(S) definido sobre o conjunto da relação r(S). Deixe que alguma relação r(S) satisfaça essa restrição. Aplicando as regras de inferência de Armstrong às dependências funcionais definidas para o conjunto F(S), pode-se obter novas dependências funcionais, como já dissemos e provamos anteriormente. E, o que é indicativo, a relação F(S) irá satisfazer automaticamente as restrições dessas dependências funcionais, como pode ser visto na forma estendida das regras de inferência de Armstrong. Lembre-se da forma geral dessas regras de inferência estendidas: Regra de Inferência 1. inv r(S); Regra de Inferência 2. inv r(S) ⇒ inv<X ∪ Z → Y> r(S); Regra de Inferência 3. inv r(S) & inv ∪ W → Z> r(S) ⇒ inv<X ∪ W→Z>; Voltando ao nosso raciocínio, vamos reabastecer o conjunto F(S) com novas dependências derivadas dele usando as regras de Armstrong. Aplicaremos este procedimento de reabastecimento até que não tenhamos mais novas dependências funcionais. Como resultado dessa construção, obteremos um novo conjunto de dependências funcionais, chamado fecho conjunto F(S) e denotado F+Diversidade, Igualdade e Compromisso para com a Sociedade. De fato, tal nome é bastante lógico, pois nós pessoalmente, através de uma longa construção, "fechamos" o conjunto de dependências funcionais existentes sobre si mesmo, acrescentando (daí o "+") todas as novas dependências funcionais resultantes das existentes. Deve-se notar que esse processo de construção de um fechamento é finito, pois o próprio esquema de relações, sobre o qual todas essas construções são realizadas, é finito. Escusado será dizer que um encerramento é um superconjunto do conjunto que está sendo fechado (na verdade, é maior!) e não muda de forma alguma quando é fechado novamente. Se escrevermos o que acabamos de dizer em uma forma formulada, obtemos: F(S) ⊆ F+(S), [F+(S)]+= F+(S); Além disso, da verdade provada (ou seja, legalidade, legitimidade) das regras de inferência de Armstrong e a definição de fechamento, segue-se que qualquer relação que satisfaça as restrições de um determinado conjunto de dependências funcionais satisfará a restrição da dependência pertencente ao fechamento . X → Y ∈ F+Diversidade, Igualdade e Compromisso para com a Sociedade ⇒ ∀r(S) [inv r(S) ⇒ inv r(S)]; Assim, o teorema da completude de Armstrong para o sistema de regras de inferência afirma que a implicação externa pode ser legitimamente e justificadamente substituída pela equivalência. (Não consideraremos a prova deste teorema, uma vez que o processo de prova em si não é tão importante em nosso curso particular de aulas.) Aula número 10. Formas normais 1. O significado da normalização do esquema de banco de dados O conceito que consideraremos nesta seção está relacionado ao conceito de dependências funcionais, ou seja, o significado de normalizar esquemas de banco de dados está inextricavelmente ligado ao conceito de restrições impostas por um sistema de dependências funcionais, e em grande parte decorre desse conceito. O ponto de partida de qualquer projeto de banco de dados é representar o domínio como um ou mais relacionamentos e, em cada etapa do projeto, algum conjunto de esquemas de relacionamento é produzido com propriedades "aprimoradas". Assim, o processo de projeto é um processo de normalização de padrões de relacionamento, com cada forma normal sucessiva tendo propriedades que são, em certo sentido, melhores que a anterior. Cada forma normal tem um certo conjunto de restrições, e uma relação está em uma certa forma normal se ela satisfaz seu próprio conjunto de restrições. Um exemplo é a restrição da primeira forma normal - os valores de todos os atributos da relação são atômicos. Na teoria de banco de dados relacional, a seguinte sequência de formas normais é geralmente distinguida: 1) primeira forma normal (1 NF); 2) segunda forma normal (2 NF); 3) terceira forma normal (3 FN); 4) forma normal de Boyce-Codd (BCNF); 5) quarta forma normal (4 NF); 6) quinta forma normal, ou forma normal de junção de projeção (5 NF ou PJ/NF). (Este curso de palestras inclui uma discussão detalhada das quatro primeiras formas normais de relações básicas, portanto, não analisaremos a quarta e a quinta formas normais em detalhes.) As principais propriedades das formas normais são as seguintes: 1) cada forma normal seguinte é, em certo sentido, melhor do que a forma normal anterior; 2) ao passar para a próxima forma normal, as propriedades das formas normais anteriores são preservadas. O processo de projeto é baseado no método de normalização, ou seja, decomposição de uma relação que está na forma normal anterior em duas ou mais relações que satisfaçam os requisitos da próxima forma normal (encontraremos isso quando nós mesmos tivermos que normalizar aquela à medida que passamos pelo material) ou alguma outra relação básica). Conforme mencionado na seção sobre como criar relacionamentos básicos, os conjuntos fornecidos de dependências funcionais impõem restrições apropriadas aos esquemas de relacionamentos básicos. Essas restrições geralmente são implementadas de duas maneiras: 1) declarativamente, ou seja, declarando vários tipos de chaves primárias, candidatas e estrangeiras na relação base (este é o método mais utilizado); 2) processualmente, ou seja, escrever o código do programa (usando os chamados gatilhos mencionados acima). Com a ajuda de uma lógica simples, você pode entender qual é o objetivo de normalizar esquemas de banco de dados. Normalizar bancos de dados ou trazer bancos de dados para uma forma normal significa definir tais esquemas de relações básicas para minimizar a necessidade de escrever código de programa, aumentar o desempenho do banco de dados e facilitar a manutenção da integridade dos dados por estado e integridade referencial. Ou seja, tornar o código e trabalhar com ele o mais simples e conveniente possível para desenvolvedores e usuários. Para demonstrar visualmente em comparação a operação de um banco de dados não normalizado e normalizado, considere o exemplo a seguir. Vamos ter uma relação de base contendo informações sobre os resultados da sessão de exame. Já consideramos esse banco de dados antes. Assim, 1 opção esquemas de banco de dados. Sessão (número do livro de registro, Nome completo, Assunto, Avaliar) Nesta relação, como você pode ver na imagem do esquema da relação base, uma chave primária composta é definida: Chave primária (número da apostila, assunto); Também a este respeito, é definido um sistema de dependências funcionais: {Número do livro de contas} → {Sobrenome, Nome, Patronímico}; Aqui está uma visão tabular de um pequeno fragmento de um banco de dados com este esquema de relação. Já usamos este fragmento ao considerar as limitações das dependências funcionais, então será bem fácil entendermos este tópico usando seu exemplo.
Aqui, para manter a integridade dos dados por estado, ou seja, para cumprir a restrição do sistema de dependência funcional {classbook number} → {Last name, First name, Patronímico} ao alterar, por exemplo, o sobrenome, é necessário examinar todas as tuplas dessa relação básica e inserir sequencialmente as mudanças necessárias. No entanto, por se tratar de um processo bastante trabalhoso e demorado (principalmente se estivermos lidando com um banco de dados de uma grande instituição de ensino), os desenvolvedores de sistemas gerenciadores de banco de dados chegaram à conclusão de que esse processo precisa ser automatizado, ou seja, , automática. Agora, o controle sobre o cumprimento desta (e de qualquer outra) dependência funcional pode ser organizado automaticamente usando a declaração correta de várias chaves na relação base e a chamada decomposição (ou seja, quebrar algo em várias partes independentes) desta relação. Então, vamos dividir nosso esquema de relacionamento "Sessão" existente em dois esquemas: o esquema "Alunos", que contém apenas informações sobre os alunos de uma determinada instituição de ensino, e o esquema "Sessão", que contém informações sobre a última sessão anterior. E então declararemos as chaves de forma que possamos obter facilmente qualquer informação necessária. Vamos mostrar como serão esses novos esquemas de relacionamento com suas chaves. opção 2 esquemas de banco de dados. Alunos (número do livro de registro, Nome completo), Chave primária (número do livro de notas). Sessão (Número do livro de registro, Assunto, Avaliar), Chave primária (número do livro de notas, Assunto), Chave estrangeira (número do boletim de notas) referências Estudantes (número do boletim de notas). O que nós temos agora? Em relação aos "Alunos", a chave primária "Número do boletim de notas" determina funcionalmente os outros três atributos: "Sobrenome", "Nome" e "Patronímico". E em relação a "Sessão", a chave primária composta "Nº do Boletim, Assunto" também de forma inequívoca, ou seja, define literalmente funcionalmente o último atributo desse esquema de relacionamento - "Pontuação". E a conexão entre essas duas relações foi estabelecida: é realizada através da chave externa da relação "Sessão" "Nº Caderno", que se refere ao atributo de mesmo nome na relação "Alunos" e, quando solicitado, fornece todas as informações necessárias. Vamos agora mostrar como serão as relações representadas pelas tabelas correspondentes à segunda opção de especificar os esquemas de banco de dados correspondentes.
Assim, vemos que o objetivo da normalização em termos das restrições impostas pelas dependências funcionais é a necessidade de impor as dependências funcionais requeridas em qualquer banco de dados usando declarações de vários tipos de chaves primárias, candidatas e estrangeiras das relações de base. 2. Primeira Forma Normal (1NF) Nos estágios iniciais de projeto de banco de dados e desenvolvimento de esquemas de gerenciamento de banco de dados, atributos simples e inequívocos foram usados como as unidades de código mais produtivas e racionais. Em seguida, eles usaram atributos simples e compostos, bem como atributos de valor único e multivalorados. Vamos explicar o significado de cada um desses conceitos. Atributos compostos, ao contrário dos simples, são atributos compostos por vários atributos simples. Atributos multivalorados, ao contrário dos de valor único, são atributos que representam vários valores. Aqui estão exemplos de atributos simples, compostos, de valor único e de vários valores. Considere a tabela a seguir representando o relacionamento:
Aqui, o atributo "Telefone" é simples, inequívoco, e o atributo "Endereço" é simples, mas possui vários valores. Agora considere outra tabela, com atributos diferentes:
Nesta relação, representada pela tabela, o atributo "Telefones" é simples, mas multivalorado, e o atributo "Endereços" é composto e multivalorado. Em geral, várias combinações de atributos simples ou compostos são possíveis. Em casos diferentes, as tabelas que representam relacionamentos podem se parecer com isso em geral:
Ao normalizar esquemas de relações básicas, os programadores podem usar um dos quatro tipos mais comuns de formas normais: primeira forma normal (1NF), segunda forma normal (2NF), terceira forma normal (3NF) ou forma normal Boyce-Codd (NFBC). . Para esclarecer: a abreviação NF é uma abreviação da frase em inglês Normal Form. Formalmente, além das acima, existem outros tipos de formas normais, mas as acima são uma das mais populares. Atualmente, os desenvolvedores de banco de dados estão tentando evitar atributos compostos e multivalorados para não complicar a escrita do código, não sobrecarregar sua estrutura e não confundir os usuários. A partir dessas considerações, a definição da primeira forma normal segue logicamente. Definição. Qualquer relação de base está em primeira forma normal se e somente se o esquema dessa relação contém apenas atributos simples e de valor único, e necessariamente com a mesma semântica. Para explicar visualmente as diferenças entre relações normalizadas e não normalizadas, considere um exemplo. Seja, existe uma relação não normalizada, com o seguinte esquema. Assim, 1 opção esquemas de relação com uma chave primária simples definida nele: Funcionários (número pessoal, Sobrenome, Nome, Patronímico, Código do cargo, Telefones, Data de admissão ou demissão); Chave primária (número pessoal); Vamos listar quais erros existem nesse esquema de relacionamento, ou seja, nomearemos aqueles sinais que tornam esse esquema propriamente não normalizado: 1) o atributo "Sobrenome Nome Patronímico" é composto, ou seja, composto por elementos heterogêneos; 2) o atributo "Telefones" é multivalorado, ou seja, seu valor é um conjunto de valores; 3) o atributo "Data de aceitação ou demissão" não possui semântica inequívoca, ou seja, neste último caso não fica claro qual data é inserida. Se, por exemplo, um atributo adicional for introduzido para definir com mais precisão o significado de uma data, o valor desse atributo será semanticamente claro, mas ainda assim será possível armazenar apenas uma das datas especificadas para cada funcionário. O que precisa ser feito para trazer essa relação à forma normal? Primeiro, é necessário dividir os atributos compostos em simples para excluir esses atributos muito compostos, bem como os atributos com semântica composta. E em segundo lugar, é necessário decompor essa relação, ou seja, é necessário quebrá-la em várias novas relações independentes para excluir atributos multivalorados. Assim, levando em conta todo o exposto, após reduzir a relação "Employees" para a primeira forma normal ou 1NF decompondo-a, obteremos um sistema das seguintes relações com chaves primárias e estrangeiras definidas sobre elas. Assim, 2 opção relações: Funcionários (número pessoal, Apelido, Nome próprio, Patronímico, Código do cargo, Data de admissão, Data de demissão); Chave primária (número pessoal); Telefones (Número pessoal, telefone); Chave primária (número pessoal, telefone); Referências de chave estrangeira (número pessoal) Funcionários (número pessoal); Então o que vemos? O atributo composto "Sobrenome Nome Patronímico" não está mais em nossa relação, em vez dele existem três atributos simples "Sobrenome", "Nome" e "Patronímico", portanto, esse motivo da "anormalidade" do relacionamento foi excluído . Além disso, em vez do atributo com semântica pouco clara "Data de contratação ou demissão", agora temos dois atributos "Data de admissão" e "Data de demissão", cada um com semântica inequívoca. Portanto, a segunda razão pela qual nossa relação "Empregados" não está na forma normal também é eliminada com segurança. E, por fim, o último motivo pelo qual a relação "Empregados" não foi normalizada é a presença do atributo multivalorado "Telefones". Para se livrar desse atributo, foi necessário decompor todo o relacionamento. Como resultado dessa decomposição, o atributo "Telefones" foi excluído da relação original "Funcionários" em geral, mas formou-se uma segunda relação - "Telefones", na qual existem dois atributos: "número pessoal do funcionário" e "Telefone ", ou seja, todos os atributos - novamente simples, a condição de pertencer à primeira forma normal é satisfeita. Esses atributos "Número do funcionário" e "Telefone" formam uma chave primária composta da relação "Telefones", e o atributo "Número do funcionário", por sua vez, é uma chave estrangeira que se refere ao atributo de mesmo nome na lista "Funcionários". relação ", ou seja, em relação ao atributo "Telefones" da chave primária "número pessoal" é também uma chave estrangeira referente à chave primária da relação "Funcionários". Assim, um link é fornecido entre os dois relacionamentos. Usando este link, você pode exibir toda a lista de seus telefones pelo número pessoal de qualquer funcionário sem muito esforço e tempo sem recorrer ao uso de atributos compostos. Observe que se houvesse dependências funcionais em relação ao sistema, após todas as transformações acima, a normalização não seria concluída. No entanto, neste exemplo específico, não há restrições de dependência funcional, portanto, não é necessária uma normalização adicional desse relacionamento. 3. Segunda Forma Normal (2NF) Requisitos mais fortes são impostos às relações pela segunda forma normal, ou 2FN. Isso porque a definição da segunda forma normal de relações implica, ao contrário da primeira forma normal, a presença de um sistema de restrições às dependências funcionais. Definição. A relação de base está em segunda forma normal em relação a um determinado conjunto de dependências funcionais se e somente se ele estiver na primeira forma normal e, além disso, cada atributo não-chave for totalmente funcionalmente dependente de cada chave. Nesta definição atributo não chave é qualquer atributo de relação que não esteja contido em nenhuma chave primária ou candidata da relação. A dependência funcional total em uma chave não implica em nenhuma dependência funcional em qualquer parte dessa chave. Assim, agora, ao normalizar uma relação, devemos também monitorar o atendimento das condições para que a relação esteja na primeira forma normal, ou seja, garantir que seus atributos sejam simples e inequívocos, bem como o atendimento da segunda condição quanto à as restrições de dependências funcionais. É claro que as relações com chaves simples (primária e candidata) estão certamente na segunda forma normal. De fato, neste caso, a dependência de uma parte da chave simplesmente não parece possível, porque a chave simplesmente não tem partes separadas. Agora, como na passagem do tópico anterior, considere um exemplo de um esquema de relação não normalizado e o próprio processo de normalização. Assim, 1 opção esquemas de relação: Públicos-alvo (Edifício nº, Auditório nº., Área m² m, No. comandante de serviço do corpo); Chave primária (número do corpus, número da audiência); Além disso, o seguinte sistema de dependência funcional é definido: {Nº do corpo} → {Nº do comandante de serviço do corpo}; O que vemos? Todas as condições para que esta relação "Público" permaneça na primeira forma normal estão reunidas, porque cada atributo desta relação é inequívoco e simples. Mas a condição de que cada elemento não-chave deve ser completamente funcionalmente dependente da chave não é satisfeita. Por quê? Sim, porque o atributo "Nº do estado-maior comandante do corpo" não depende funcionalmente da chave composta "Nº do corpo, nº da audiência", mas de uma parte desta chave, ou seja, do atributo "Nº do corpo". De fato, afinal, é o número do corpo que determina completamente qual comandante específico é designado a ele e, por sua vez, o número pessoal do comandante do corpo não pode depender de nenhum número de auditório. Assim, a principal tarefa da nossa normalização passa a ser a de garantir que as chaves sejam distribuídas de tal forma que, em particular, o atributo "No. Para conseguir isso, teremos que aplicar novamente, como no parágrafo anterior, a decomposição da relação. Então, o seguinte sistema de relações, que é 2 opção O relacionamento “Público” foi obtido apenas do relacionamento original, decompondo-o em vários novos relacionamentos independentes: Corpo (Nº do casco, número do comandante de pessoal do corpo); Chave primária (número do caso); Públicos-alvo (Edifício nº, Auditório nº., Área m² m); Chave primária (número do corpus, número da audiência); Referências de chave estrangeira (número do caso) Casos (número do caso); O que vemos agora? Com relação ao atributo não-chave "Corpus" "Número de pessoal do comandante do Corpo" depende totalmente funcionalmente da chave primária "Número do Corpo". Aqui a condição para encontrar a relação na segunda forma normal é totalmente satisfeita. Agora vamos passar para a consideração da segunda relação - "Público". Com relação a "Público", o atributo de chave primária "Caso #" também é uma chave estrangeira que se refere à chave primária do relacionamento "Caso". A este respeito, o atributo não chave "Área mXNUMX" é completamente dependente de toda a chave primária composta "Edifício #, Auditório #" e não depende, nem pode depender de nenhuma de suas partes. Assim, decompondo a relação original, chegamos à conclusão de que todas as condições da definição da segunda forma normal são plenamente satisfeitas. Neste exemplo, todos os requisitos de dependência funcional são impostos pela declaração de chaves primárias (sem chaves candidatas aqui) e chaves estrangeiras. Portanto, nenhuma normalização adicional é necessária. 4. Terceira Forma Normal (3NF) A próxima forma normal que veremos é a terceira forma normal (ou 3FN). Ao contrário da primeira forma normal, bem como da segunda forma normal, a terceira implica a atribuição de um sistema de dependências funcionais juntamente com a relação. Vamos formular quais propriedades uma relação deve ter para que seja reduzida à terceira forma normal. Definição. A relação de base está em terceira forma normal com relação a um determinado conjunto de dependências funcionais se e somente se ele estiver na segunda forma normal e cada atributo não-chave for funcionalmente dependente apenas de chaves. Assim, os requisitos da terceira forma normal são mais fortes do que os requisitos da primeira e da segunda formas normais, mesmo combinadas. De fato, na terceira forma normal, todo atributo não chave depende da chave e da chave inteira, e de nada mais que a chave. Vamos ilustrar o processo de trazer uma relação não normalizada para a terceira forma normal. Para fazer isso, considere um exemplo: uma relação que não está na terceira forma normal. Assim, 1 opção esquemas da relação "Funcionários": Funcionários (número pessoal, Sobrenome, Nome, Patronímico, Código Cargo, Salário); Chave primária (número pessoal); Além disso, o seguinte sistema de dependências funcionais é definido acima desse relacionamento "Funcionários": {Código do cargo} → {Salário}; De fato, como regra, o valor do salário, ou seja, o valor dos salários, depende diretamente do cargo e, portanto, de seu código no banco de dados correspondente. É por isso que esta relação "Funcionários" não está na terceira forma normal, porque acontece que o atributo não-chave "Salário" é completamente funcionalmente dependente do atributo "Código de cargo", embora este atributo não seja chave. Curiosamente, qualquer relação se reduz à terceira forma normal exatamente da mesma maneira que às duas formas anteriores a esta, a saber, por decomposição. Decompondo a relação "Empregados", obtemos o seguinte sistema de novas relações independentes: Assim, 2 opção esquemas da relação "Funcionários": Posições (Código de posição, Salário); Chave primária (código de posição); Funcionários (número pessoal, Sobrenome, Nome, Patronímico, Código do cargo); Chave primária (código de posição); Referências de chave estrangeira (código de posição) Posições (código de posição); Agora, como podemos ver, em relação a "Cargo", o atributo não chave "Salário" é completamente funcionalmente dependente da chave primária simples "Código Cargo" e somente desta chave. Observe que, em relação a "Funcionários", todos os quatro atributos não-chave "Sobrenome", "Nome", "Patronímico" e "Código de Cargo" são totalmente dependentes da chave primária simples "Número de Emprego". A este respeito, o atributo "Position ID" é uma chave estrangeira que se refere à chave primária do relacionamento "Positions". Neste exemplo, todos os requisitos são impostos pela declaração de chaves primárias e estrangeiras simples, portanto, nenhuma normalização adicional é necessária. É interessante e útil saber que, na prática, geralmente se limita a trazer os bancos de dados para a terceira forma normal. Ao mesmo tempo, algumas dependências funcionais de atributos-chave em outros atributos do mesmo relacionamento podem não ser impostas. O suporte para essas dependências funcionais não padrão é implementado usando os gatilhos mencionados anteriormente (ou seja, processualmente, escrevendo o código de programa apropriado). Além disso, os gatilhos devem operar com tuplas dessa relação. 5. Forma Normal de Boyce-Codd (NFBC) A forma normal de Boyce-Codd segue em "complexidade" logo após a terceira forma normal. Portanto, a forma normal de Boyce-Codd às vezes também é chamada simplesmente terceira forma normal forte (ou reforçado 3 NF). Por que ela é reforçada? Formulamos a definição da forma normal de Boyce-Codd: Definição. A relação de base está em Boyce forma normal - Kodd se e somente se estiver na terceira forma normal, e não apenas qualquer atributo não chave é totalmente funcionalmente dependente de qualquer chave, mas qualquer atributo chave deve ser totalmente funcionalmente dependente de qualquer chave. Assim, o requisito de que os atributos não-chave realmente dependam da chave inteira e de nada além da chave se aplica aos atributos-chave também. Em uma relação que está na forma normal de Boyce-Codd, todas as dependências funcionais dentro da relação são impostas pela declaração de chaves. No entanto, ao reduzir as relações de banco de dados para a forma Boyce-Codd, são possíveis situações em que as dependências entre os atributos de várias relações acabam sendo dependências funcionais não impostas. Suportar tais dependências funcionais com triggers operando em tuplas de diferentes relações é mais difícil do que no caso da terceira forma normal, quando triggers operam em tuplas de uma única relação. Entre outras coisas, a prática de projetar sistemas de gerenciamento de banco de dados mostrou que nem sempre é possível trazer a relação básica para a forma normal de Boyce-Codd. A razão para as anomalias observadas é que os requisitos da segunda forma normal e da terceira forma normal não requerem uma dependência funcional mínima da chave primária de atributos que são componentes de outras chaves possíveis. Este problema é resolvido pela forma normal, que é historicamente chamada de forma normal de Boyce-Codd e que é um refinamento da terceira forma normal no caso da presença de várias chaves possíveis sobrepostas. Em geral, a normalização do esquema de banco de dados torna as atualizações de banco de dados mais eficientes para o sistema de gerenciamento de banco de dados, pois reduz o número de verificações e backups que mantêm a integridade do banco de dados. Ao projetar um banco de dados relacional, você quase sempre obtém a segunda forma normal de todos os relacionamentos no banco de dados. Em bancos de dados que são atualizados com frequência, eles geralmente tentam fornecer a terceira forma normal do relacionamento. A forma normal de Boyce-Codd recebe muito menos atenção porque, na prática, são raras as situações em que uma relação tem várias chaves candidatas sobrepostas compostas. Todos os itens acima tornam a forma normal Boyce-Codd não muito conveniente de usar ao desenvolver código de programa, portanto, como mencionado anteriormente, na prática, os desenvolvedores geralmente se limitam a trazer seus bancos de dados para a terceira forma normal. No entanto, ele também tem sua própria característica bastante curiosa. O ponto é que situações em que uma relação está na terceira forma normal, mas não na forma normal de Boyce-Codd, são extremamente raras na prática, ou seja, após a redução à terceira forma normal, geralmente todas as dependências funcionais são impostas por declarações de primária, candidata e chaves estrangeiras, portanto, não há necessidade de gatilhos para suportar dependências funcionais. No entanto, a necessidade de gatilhos permanece para dar suporte a restrições de integridade que não estão vinculadas por dependências funcionais. 6. Aninhamento de formas normais O que significa aninhamento de formas normais? Aninhamento de formas normais - esta é a proporção dos conceitos de formas enfraquecidas e fortalecidas em relação umas às outras. O aninhamento de formas normais segue completamente de suas respectivas definições. Vamos imaginar um diagrama ilustrando a relação de aninhamento das formas normais conhecidas por nós:
Vamos explicar os conceitos de formas normais enfraquecidas e fortalecidas umas em relação às outras usando exemplos concretos. A primeira forma normal é enfraquecida em relação à segunda forma normal (e também em relação a todas as outras formas normais). De fato, lembrando as definições de todas as formas normais pelas quais passamos, podemos ver que os requisitos de cada forma normal incluíam o requisito de pertencer à primeira forma normal (afinal, isso foi incluído em cada definição subsequente). A segunda forma normal é mais forte que a primeira forma normal, mas mais fraca que a terceira forma normal e a forma normal de Boyce-Codd. De fato, pertencer à segunda forma normal está incluído na definição da terceira, e a própria segunda forma, por sua vez, inclui a primeira forma normal. A forma normal de Boyce-Codd não se fortalece apenas em relação à terceira forma normal, mas também em relação a todas as outras que a precedem. E a terceira forma normal, por sua vez, é enfraquecida apenas em relação à forma normal de Boyce-Codd. Aula No. 11. Projetando esquemas de banco de dados O meio mais comum de abstrair esquemas de banco de dados ao projetar no nível lógico é o chamado modelo entidade-relacionamento. Às vezes também é chamado Modelo ER, onde ER é uma abreviação da frase em inglês Entidade - Relacionamento, que se traduz literalmente como "entidade - relacionamento". Os elementos de tais modelos são classes de entidade, seus atributos e relacionamentos. Daremos explicações e definições de cada um desses elementos. Classe de entidade é como uma classe de objetos sem método no sentido de programação orientada a objetos. Ao passar para a camada física, as classes de entidade são convertidas em relacionamentos básicos de banco de dados relacional para sistemas de gerenciamento de banco de dados específicos. Eles, como as próprias relações básicas, têm seus próprios atributos. Vamos dar uma definição mais precisa e rigorosa dos objetos que acabamos de dar. classe é chamado de descrição nomeada de uma coleção de objetos com atributos, operações, relacionamentos e semântica comuns. Graficamente, uma classe geralmente é representada como um retângulo. Cada classe deve ter um nome (uma string de texto) que a diferencie exclusivamente de todas as outras classes. atributo de classe é uma propriedade nomeada de uma classe que descreve o conjunto de valores que instâncias dessa propriedade podem assumir. Uma classe pode ter qualquer número de atributos (em particular, não pode ter atributos). Uma propriedade expressa por um atributo é uma propriedade da entidade modelada que é comum a todos os objetos de uma determinada classe. Assim, um atributo é uma abstração do estado de um objeto. Qualquer atributo de qualquer objeto de classe deve ter algum valor. Os chamados relacionamentos são implementados usando a declaração de chaves estrangeiras (já encontramos fenômenos semelhantes antes), ou seja, em relação, são declaradas chaves estrangeiras que se referem às chaves primárias ou candidatas de algum outro relacionamento. E através disso, várias relações básicas independentes diferentes são "ligadas" em um único sistema chamado banco de dados. Além disso, o diagrama que forma a base gráfica do modelo entidade-relacionamento é representado usando a linguagem de modelagem unificada UML. Muitos livros são dedicados à linguagem de modelagem orientada a objetos UML (ou Unified Modeling Language), muitos dos quais foram traduzidos para o russo (e alguns escritos por autores russos). Em geral, a UML permite modelar diferentes tipos de sistemas: puramente software, puramente hardware, software-hardware, mistos, incluindo explicitamente atividades humanas, etc. Mas, entre outras coisas, como já mencionamos, a linguagem UML é usada ativamente para projetar bancos de dados relacionais. Para isso, é utilizada uma pequena parte da linguagem (diagramas de classes), e mesmo assim não na íntegra. De uma perspectiva de design de banco de dados relacional, os recursos de modelagem não são muito diferentes daqueles dos diagramas ER. Também queríamos mostrar que, no contexto do projeto de banco de dados relacional, os métodos de projeto estrutural baseados no uso de diagramas ER e os métodos orientados a objetos baseados no uso da linguagem UML diferem principalmente apenas na terminologia. O modelo ER é conceitualmente mais simples que o UML, possui menos conceitos, termos e opções de aplicação. E isso é compreensível, pois diferentes versões de modelos de ER foram desenvolvidas especificamente para dar suporte ao design de banco de dados relacional, e os modelos de ER quase não contêm recursos que vão além das necessidades reais de um designer de banco de dados relacional. A UML pertence ao mundo dos objetos. Este mundo é muito mais complicado (se você preferir, mais incompreensível, mais confuso) do que o mundo relacional. Como a UML pode ser usada para modelagem unificada orientada a objetos de qualquer coisa, a linguagem contém uma infinidade de conceitos, termos e casos de uso que são redundantes de uma perspectiva de design de banco de dados relacional. Se extrairmos do mecanismo geral dos diagramas de classes o que é realmente necessário para o projeto de bancos de dados relacionais, obteremos exatamente diagramas ER com notação e terminologia diferentes. É curioso que, ao formar nomes de classes na UML, seja permitida uma combinação arbitrária de letras, números e até sinais de pontuação. No entanto, na prática, recomenda-se usar adjetivos e substantivos curtos e significativos como nomes de classe, cada um deles começando com uma letra maiúscula. (Consideraremos o conceito de diagrama com mais detalhes no próximo parágrafo de nossa palestra.) 1. Vários tipos e multiplicidades de títulos O relacionamento entre relacionamentos no projeto de esquemas de banco de dados é representado como linhas conectando classes de entidade. Além disso, cada uma das extremidades da conexão pode (e geralmente deve) ser caracterizada pelo nome (ou seja, o tipo de conexão) e pela multiplicidade do papel da classe na conexão. Consideremos com mais detalhes os conceitos de multiplicidade e tipos de conexões. multiplicidade (multiplicidade) é uma característica que indica quantos atributos de uma classe de entidade com um determinado papel podem ou devem participar em cada instância de um relacionamento de algum tipo. A maneira mais comum de definir a cardinalidade de uma função de relacionamento é especificar diretamente um número ou intervalo específico. Por exemplo, especificar "1" diz que cada classe com uma determinada função deve participar de alguma instância dessa conexão e exatamente um objeto da classe com essa função pode participar de cada instância da conexão. Especificar o intervalo "0..1" indica que nem todos os objetos da classe com uma determinada função precisam participar de qualquer instância desse relacionamento, mas apenas um objeto pode participar de cada instância do relacionamento. Vamos falar sobre multiplicidade com mais detalhes. As cardinalidades típicas e mais comuns em sistemas de design de banco de dados são as seguintes cardinalidades: 1) 1 - a multiplicidade da conexão em sua extremidade correspondente é igual a um; 2) 0... 1 - esta forma de notação significa que a multiplicidade de uma determinada conexão em sua extremidade correspondente não pode exceder um; 3) 0... ∞ - esta multiplicidade é simplesmente decifrada como “muitos”. É curioso que, via de regra, “muito” signifique “nada”; 4) 1... ∞ - esta designação foi dada à multiplicidade “um ou mais”. Vamos dar um exemplo de um diagrama simples para ilustrar o trabalho com diferentes multiplicidades de links.
De acordo com esse diagrama, pode-se entender facilmente que cada bilheteria possui muitos ingressos e, por sua vez, cada ingresso está localizado em uma (e não mais que isso) bilheteria. Agora considere os tipos ou nomes mais comuns de links. Vamos listá-los: 1) 1: 1 - esta designação foi dada à conexão "um a um", isto é, é, por assim dizer, uma correspondência biunívoca de dois conjuntos; 2) 1 : 0... ∞ - esta é uma designação para uma conexão como "um para muitos". Por brevidade, esse relacionamento é chamado de "1: M". No diagrama considerado anteriormente, como você pode ver, existe um relacionamento exatamente com esse nome; 3) 0... ∞ : 1 - esta é uma reversão da conexão anterior ou uma conexão do tipo "muitos para um"; 4) 0... ∞ : 0... ∞ é uma designação para uma conexão como "muitos para muitos", ou seja, existem muitos atributos em cada extremidade do link; 5) 0... 1 : 0... 1 - esta é uma conexão semelhante à conexão do tipo “um para um” introduzida anteriormente, que, por sua vez, é chamada de "não mais do que um até não mais do que um"; 6) 0... 1 : 0... ∞ - esta é uma conexão semelhante a uma conexão um para muitos, é chamada de “não mais que um para muitos”; 7) 0... ∞ : 0... 1 - esta é uma conexão, por sua vez, semelhante a uma conexão do tipo muitos para um, é chamada de "muitos a não mais de um". Como você pode ver, as três últimas conexões foram obtidas a partir das conexões listadas em nossa palestra sob os números um, dois e três, substituindo a multiplicidade de "um" pela multiplicidade de "não mais que um". 2. Diagramas. Tipos de gráficos E agora vamos finalmente prosseguir diretamente para a consideração dos diagramas e seus tipos. Em geral, existem três níveis do modelo lógico. Esses níveis diferem na profundidade de representação das informações sobre a estrutura de dados. Esses níveis correspondem aos seguintes diagramas: 1) diagrama de apresentação; 2) diagrama chave; 3) diagrama de atributos completo. Vamos analisar cada um desses tipos de diagramas e explicar em detalhes o significado de suas diferenças na profundidade de apresentação das informações sobre a estrutura de dados. 1. Diagrama de apresentação. Esses diagramas descrevem apenas as classes mais básicas de entidades e seus relacionamentos. As chaves em tais diagramas podem não ser descritas e, portanto, as conexões não podem ser individualizadas de forma alguma. Portanto, relacionamentos muitos-para-muitos são aceitáveis, embora geralmente sejam evitados ou, se existirem, ajustados. Atributos compostos e multivalorados também são perfeitamente válidos, embora tenhamos escrito anteriormente que as relações de base com tais atributos não são reduzidas a nenhuma forma normal. Curiosamente, dos três tipos de diagramas que consideramos, apenas o último tipo (o diagrama de atributos completo) assume que os dados apresentados estão em alguma forma normal. Considerando que o diagrama de apresentação já considerado e o diagrama de chave seguinte na linha não implicam nada do tipo. Esses diagramas geralmente são usados para apresentações (daí seu nome - apresentacional, ou seja, usado para apresentações, demonstrações, onde não são necessários detalhes excessivos). Às vezes, ao projetar bancos de dados, é necessário consultar especialistas na área temática que esse banco de dados específico lida com informações. Em seguida, os diagramas de apresentação também são usados, pois para obter as informações necessárias de especialistas em uma profissão distante da programação, não é necessário esclarecimento excessivo de detalhes específicos. 2. Diagrama chave. Ao contrário dos diagramas de apresentação, os diagramas de chave necessariamente descrevem todas as classes de entidades e seus relacionamentos, no entanto, apenas em termos de chaves primárias. Aqui, relacionamentos muitos-para-muitos já são necessariamente detalhados (ou seja, relacionamentos desse tipo em sua forma pura simplesmente não podem ser especificados aqui). Atributos de vários valores ainda são permitidos da mesma forma que em um diagrama de apresentação, mas se estiverem presentes em um diagrama de chave, geralmente são convertidos em classes de entidade independentes. Mas, curiosamente, atributos não ambíguos ainda podem ser representados de forma incompleta ou descritos como compostos. Essas "liberdades", que ainda são válidas em diagramas como diagramas de apresentação e chave, não são permitidas no próximo tipo de diagrama, pois determinam que a relação de base não seja normalizada. Assim, podemos concluir que os diagramas de chave no futuro assumem apenas atributos "pendurados" nas classes de entidade já descritas, ou seja, usando um diagrama de apresentação, basta descrever as classes de entidade mais necessárias e, em seguida, usando um diagrama de chave, adicionar tudo a ele atributos necessários e especifique todos os links mais importantes. 3. Diagrama completo de atributos. Diagramas de atributos completos descrevem com mais detalhes todas as classes de entidades acima, seus atributos e relacionamentos entre essas classes de entidade. Como regra, tais gráficos representam dados que estão na terceira forma normal, então é natural que nas relações básicas descritas por tais gráficos não sejam permitidos atributos compostos ou multivalorados, assim como não existem muitos-para- não granulares. muitos relacionamentos. No entanto, os gráficos de atributos completos ainda apresentam uma desvantagem, ou seja, não podem ser considerados totalmente os mais completos dos gráficos em termos de apresentação de dados. Por exemplo, a peculiaridade de sistemas de gerenciamento de banco de dados específicos ao usar diagramas de atributos completos ainda não é levada em consideração e, em particular, o tipo de dados é especificado apenas na extensão necessária para o nível lógico de modelagem necessário. 3. Associações e migração de chaves Um pouco antes, já falamos sobre quais são os relacionamentos nos bancos de dados. Em particular, o relacionamento foi estabelecido ao declarar as chaves estrangeiras do relacionamento. Mas nesta seção do nosso curso, não estamos mais falando de relações básicas, mas de caixas registradoras de entidades. Nesse sentido, o processo de estabelecimento de relacionamentos ainda está associado às declarações de várias chaves, mas agora estamos falando das chaves das classes de entidade. Ou seja, o processo de estabelecimento de relacionamentos está associado à transferência de uma chave primária simples ou composta de uma classe de entidade para outra classe. O processo de tal transferência também é chamado de migração de chave. Nesse caso, a classe de entidade cujas chaves primárias são transferidas é chamada classe pai, e a classe de entidades para as quais as chaves estrangeiras são migradas é chamada classe infantil entidades. Em uma classe de entidade filha, os atributos de chave recebem o status de atributos de chave estrangeira e podem ou não participar da formação de sua própria chave primária. Assim, quando uma chave primária é migrada de uma classe de entidade pai para uma classe filha, uma chave estrangeira aparece na classe filha que se refere à chave primária da classe pai. Para conveniência da representação estereotipada da migração de chave, apresentamos os seguintes marcadores de chave: 1) PK - é assim que denotaremos qualquer atributo da chave primária (chave primária); 2) FK - com este marcador denotaremos os atributos de uma chave estrangeira (chave estrangeira); 3) PFK - com tal marcador denotaremos um atributo da chave primária / estrangeira, ou seja, qualquer atributo que faça parte da única chave primária de alguma classe de entidade e ao mesmo tempo faça parte de alguma chave estrangeira da mesma classe de entidade . Assim, os atributos de uma classe de entidade com marcadores PK e FK formam a chave primária desta classe. E atributos com marcadores FK e PFK fazem parte de algumas chaves estrangeiras desta classe de entidade. Em geral, as chaves podem migrar de maneiras diferentes e, em cada caso diferente, surge algum tipo de conexão. Portanto, vamos considerar quais tipos de links existem dependendo do esquema de migração de chave. No total, existem dois esquemas de migração principais. 1. Esquema de migração ∀PK (PK |→PFK); Nesta entrada, o símbolo "|→" significa o conceito de "migra", ou seja, a fórmula acima será lida da seguinte forma: qualquer (cada) atributo da chave primária PK da classe da entidade pai é transferido (migra) para o chave primária PFK classe de entidade filha, que, é claro, também é uma chave estrangeira para esta classe. Neste caso, estamos falando sobre o fato de que, sem exceção, todos os atributos-chave da classe da entidade pai devem ser migrados para a classe da entidade filha. Este tipo de conexão é chamado identificando, já que a chave da classe da entidade pai está totalmente envolvida na identificação das entidades filhas. Entre os links do tipo identificador, por sua vez, existem mais dois tipos de links independentes possíveis. Portanto, existem dois tipos de links de identificação: 1) identificando totalmente. Diz-se que um relacionamento de identificação identifica totalmente se e somente se os atributos da chave primária de migração da classe de entidade pai formam completamente a chave primária (e estrangeira) da classe de entidade filha. Um relacionamento totalmente identificador também é às vezes chamado categórico, porque um relacionamento totalmente identificador identifica entidades filhas em todas as categorias; 2) não identificando totalmente. Um relacionamento de identificação é chamado de identificação incompleta se e somente se os atributos da chave primária migrante da classe de entidade pai formam apenas parcialmente a chave primária (e ao mesmo tempo estrangeira) da classe de entidade filha. Assim, além da chave com o marcador PFK também terá uma chave marcada como PK. Nesse caso, a chave estrangeira PFK da classe da entidade filha será completamente determinada pela chave primária PK da classe da entidade pai, mas simplesmente a chave primária PK desse relacionamento filho não será determinada pela chave primária PK do pai classe de entidade, ele estará por conta própria. 2. Esquema de migração ∃PK (PK |→ FC); Tal esquema de migração deve ser lido da seguinte forma: existem tais atributos de chave primária da classe de entidade pai que, durante a migração, são transferidos para os atributos não-chave obrigatórios da classe de entidade filha. Assim, neste caso, estamos falando do fato de que alguns, e não todos, como no caso anterior, os atributos de chave primária da classe da entidade pai são transferidos para a classe da entidade filha. Além disso, se o esquema de migração anterior definiu a migração para a chave primária da relação filha, que ao mesmo tempo também se tornou uma chave estrangeira, então o último tipo de migração determina que os atributos de chave primária da classe de entidade pai migrem para ordinária , inicialmente atributos não-chave, que depois disso adquirem o status de chave estrangeira. Este tipo de conexão é chamado não identificador, porque, de fato, a chave pai não está totalmente envolvida na formação das entidades filhas, ela simplesmente não as identifica. Entre os relacionamentos não identificadores, dois tipos possíveis de relacionamentos também são distinguidos. Assim, os relacionamentos não identificadores são dos dois tipos a seguir: 1) necessariamente não identificador. Relacionamentos não identificadores são considerados necessariamente não identificadores se e somente se Valores nulos para todos os atributos de chave de migração de uma classe de entidade filha são proibidos; 2) opcionalmente não identificador. Relacionamentos não identificadores são considerados não necessariamente não identificadores se e somente se valores nulos forem permitidos para alguns atributos de chave de migração da classe de entidade filha. Resumimos tudo isso na forma da tabela a seguir, a fim de facilitar a tarefa de sistematização e compreensão do material apresentado. Também nesta tabela incluiremos informações sobre quais tipos de relacionamentos ("não mais que um para um", "muitos para um", "muitos para não mais que um") correspondem a quais tipos de relacionamentos (totalmente identificador, não totalmente identificando, necessariamente não identificando, não necessariamente não identificando). Assim, entre as classes de entidade pai e filho, é estabelecido o seguinte tipo de relacionamento, dependendo do tipo de relacionamento.
Assim, vemos que em todos os casos, exceto no último, a referência não é vazia (não é nula) → 1. Observe a tendência de que, na extremidade pai da conexão, em todos os casos, exceto no último, a multiplicidade é definida como "um". Isso porque o valor da chave estrangeira nos casos desses relacionamentos (a saber, identificando totalmente, não identificando totalmente e necessariamente não identificando tipos de relacionamentos) deve necessariamente corresponder (e, além disso, o único) valor da chave primária de a classe de entidade pai. E no último caso, devido ao fato de que o valor da chave estrangeira pode ser igual ao valor nulo (o FK: sinalizador de validade nula), a multiplicidade é definida como "não mais que um" no final pai do relação. Continuamos nossa análise. No filho da conexão, em todos os casos, exceto no primeiro, a multiplicidade é definida como "muitos". Isso ocorre porque, devido à identificação incompleta, como no segundo caso, (ou nenhuma identificação, no segundo e terceiro casos), o valor da chave primária da classe da entidade pai pode ocorrer repetidamente entre os valores da chave estrangeira da classe filha. E no primeiro caso, o relacionamento é totalmente identificador, então os atributos da chave primária da classe da entidade pai só podem ocorrer uma vez entre os atributos das chaves da classe da entidade filha. Aula nº 12. Relacionamentos de classes de entidades Assim, todos os conceitos pelos quais passamos, nomeadamente diagramas e seus tipos, multiplicidades e tipos de relações, bem como tipos de migração de chaves, vão agora ajudar-nos a percorrer o material sobre as mesmas relações, mas já entre classes específicas de entidades. Entre eles, como veremos, também existem conexões de vários tipos. 1. Relacionamento recursivo hierárquico O primeiro tipo de relacionamento entre classes de entidade, que iremos considerar, é o chamado relacionamento recursivo hierárquico. Em geral recursão (ou link recursivo) é a relação de uma classe de entidade consigo mesma. Às vezes, por analogia com as situações da vida, essa conexão também é chamada de "anzol". Relacionamento recursivo hierárquico (ou simplesmente recursão hierárquica) é qualquer relacionamento recursivo do tipo "no máximo um para muitos". A recursão hierárquica é mais comumente usada para armazenar dados em uma estrutura de árvore. Ao especificar um relacionamento recursivo hierárquico, a chave primária da classe de entidade pai (que neste caso específico também atua como uma classe de entidade filha) deve ser migrada como uma chave estrangeira para os atributos não chave obrigatórios da mesma classe de entidade. Tudo isso é necessário para manter a integridade lógica do próprio conceito de "recursão hierárquica". Assim, levando em consideração tudo o que foi dito acima, podemos concluir que um relacionamento recursivo hierárquico só pode ser não necessariamente não identificador e nenhum outro, pois se fosse utilizado qualquer outro tipo de relacionamento, os valores Null para a chave estrangeira seriam inválidos e a recursão seria infinita. Também é importante lembrar que os atributos não podem aparecer duas vezes na mesma classe de entidade com o mesmo nome. Portanto, os atributos da chave migrada devem receber o chamado nome da função. Assim, em um relacionamento recursivo hierárquico, os atributos de um nó são estendidos com uma chave estrangeira que é uma referência opcional à chave primária do nó que é seu ancestral imediato. Vamos construir uma apresentação e diagramas-chave que implementam a recursão hierárquica em um modelo de dados relacional e dar um exemplo de um formulário tabular. Vamos criar um diagrama de apresentação primeiro:
Agora vamos construir um diagrama chave mais detalhado:
Considere um exemplo que ilustra claramente um tipo de relacionamento como um relacionamento recursivo hierárquico. Vamos receber a seguinte classe de entidade, que, como no exemplo anterior, consiste nos atributos "Código Antepassado" e "Código do Nó". Primeiro, vamos mostrar uma representação tabular dessa classe de entidade:
Agora vamos construir um diagrama representando esta classe de entidades. Para isso, selecionamos na tabela todas as informações necessárias para isso: o ancestral do nó com o código "um" não existe ou não está definido, a partir disso concluímos que o nó "um" é um vértice. O mesmo nó "um" é o ancestral dos nós com o código "dois" e "três". Por sua vez, o nó com o código “dois” tem dois filhos: o nó com o código “quatro” e o nó com o código “cinco”. E o nó com o código "três" tem apenas um filho - o nó com o código "seis". Então, levando em consideração tudo o que foi dito acima, vamos construir uma estrutura em árvore que reflita as informações sobre os dados contidos na tabela anterior:
Assim, vimos que é realmente conveniente representar estruturas de árvore usando um relacionamento recursivo hierárquico. 2. Comunicação recursiva de rede A conexão recursiva de rede de classes de entidade entre si é, por assim dizer, um análogo multidimensional da conexão recursiva hierárquica pela qual já passamos. Somente se a recursão hierárquica for definida como um relacionamento recursivo "no máximo um para muitos", então recursão de rede representa o mesmo relacionamento recursivo, apenas do tipo "muitos para muitos". Devido ao fato de que muitas classes de entidades participam dessa conexão em cada lado, ela é chamada de conexão de rede. Como você já pode imaginar por analogia com a recursão hierárquica, os links do tipo recursão de rede são projetados para representar estruturas de dados grafos (enquanto os links hierárquicos são usados, como lembramos, exclusivamente para a implementação de estruturas de árvore). Mas, como na conexão do tipo de recursão de rede, as conexões do tipo "muitos para muitos" são especificadas, é impossível prescindir de seu detalhamento adicional. Portanto, para refinar todos os relacionamentos muitos-para-muitos no esquema, torna-se necessário criar uma nova classe de entidade independente que contenha todas as referências ao pai ou descendente do relacionamento Antepassado-Descendente. Tal classe é geralmente chamada classe de entidade associativa. Em nosso caso particular (nos bancos de dados a serem considerados em nosso curso), a entidade associativa não possui atributos adicionais próprios e é chamada chamando, porque nomeia os relacionamentos Antepassado-Descendente fazendo referência a eles. Assim, a chave primária da classe de entidade que representa os hosts deve ser migrada duas vezes para as classes de entidade associativa. Nesta classe, as chaves migradas juntas devem formar uma chave primária composta. Do exposto, podemos concluir que o estabelecimento de links ao usar a recursão de rede não deve ser totalmente identificador e nada mais. Assim como ao usar um relacionamento recursivo hierárquico, ao usar a recursão de rede como um relacionamento, nenhum atributo pode aparecer duas vezes na mesma classe de entidade com o mesmo nome. Portanto, como da última vez, é estipulado especificamente que todos os atributos da chave de migração devem receber o nome da função. Para ilustrar a operação da comunicação recursiva de rede, vamos construir uma apresentação e os principais diagramas que implementam a recursão de rede em um modelo de dados relacional. Vamos começar com um diagrama de apresentação:
Agora vamos construir um diagrama chave mais detalhado:
O que vemos aqui? E vemos que ambas as ligações neste diagrama chave são ligações “muitos para um”. Além disso, a multiplicidade “0... ∞” ou a multiplicidade “muitos” está no final da conexão voltada para a classe de nomenclatura de entidades. Na verdade, existem muitos links, mas todos eles se referem a um código de nó, que é a chave primária da classe de entidade “Nodes”. E, finalmente, vamos considerar um exemplo ilustrando a operação de tal tipo de conexão por uma classe de entidade como recursão de rede. Vamos receber uma representação tabular de alguma classe de entidade, bem como uma classe de entidade de nomenclatura contendo informações sobre links. Vamos dar uma olhada nessas tabelas. Nós:
Links:
De fato, a representação acima é exaustiva: ela fornece todas as informações necessárias para reproduzir facilmente a estrutura do grafo aqui codificada. Por exemplo, podemos ver sem obstáculos que o nó com o código "um" tem três filhos, respectivamente, com os códigos "dois", "três" e "quatro". Também vemos que os nós com os códigos "dois" e "três" não têm descendentes, e um nó com o código "quatro" tem (assim como o nó "um") três descendentes com os códigos "um", "dois" e três". Vamos desenhar um gráfico dado pelas classes de entidade dadas acima:
Assim, o gráfico que acabamos de construir são os dados para os quais as classes de entidade foram vinculadas usando uma conexão do tipo recursão de rede. 3. Associação De todos os tipos de conexões incluídos na consideração de nosso curso particular de palestras, apenas duas são conexões recursivas. Já conseguimos considerá-los, são links hierárquicos e recursivos de rede, respectivamente. Todos os outros tipos de relacionamentos que temos que considerar não são recursivos, mas, via de regra, representam um relacionamento de várias classes de entidades pai e várias classes de entidades filhas. Além disso, como você pode imaginar, as classes de entidade pai e filho agora nunca coincidirão (na verdade, não estamos mais falando sobre recursão). A conexão, que será discutida nesta seção da palestra, é chamada de associação e refere-se justamente às conexões do tipo não recursivo. Então a conexão chamada Associação, é implementado como um relacionamento entre várias classes de entidade pai e uma classe de entidade filha. E ao mesmo tempo, o que é curioso, essa relação é descrita por relações de vários tipos. Também é importante notar que pode haver apenas uma classe de entidade pai durante a associação, como na recursão de rede, mas mesmo em tal situação, o número de relacionamentos provenientes da classe de entidade filha deve ser pelo menos dois. Curiosamente, em associação, assim como na recursão de rede, existem tipos especiais de classes de entidade. Um exemplo de tal classe é uma classe de entidade filha. De fato, no caso geral, em uma associação, uma classe de entidade filha é chamada classe de entidade associativa. No caso especial em que uma classe de entidade associativa não possui seus próprios atributos adicionais e contém apenas atributos que migram junto com as chaves primárias das classes de entidade pai, essa classe é chamada classe de nomeação de entidades. Como você pode ver, há uma analogia quase absoluta com o conceito de entidades associativas e de nomenclatura em uma conexão recursiva de rede. Na maioria das vezes, uma associação é usada para refinar (resolver) relacionamentos muitos-para-muitos. Vamos ilustrar esta afirmação. Deixe-nos, por exemplo, o seguinte diagrama de apresentação, que descreve o esquema de recepção de um determinado médico em um determinado hospital:
Este diagrama significa literalmente que há muitos médicos e muitos pacientes no hospital, e não há outro relacionamento e correspondência entre médicos e pacientes. Assim, é claro, com tal banco de dados, nunca ficaria claro para a administração do hospital como marcar consultas com diferentes médicos para diferentes pacientes. É claro que as relações muitos-para-muitos aqui utilizadas precisam apenas ser detalhadas para concretizar a relação entre os vários médicos e pacientes, ou seja, para organizar racionalmente a agenda de consultas de todos os médicos e seus pacientes em o hospital. E agora vamos construir um diagrama de chaves mais detalhado, no qual já detalhamos todos os relacionamentos muitos-para-muitos existentes. Para fazer isso, vamos introduzir uma nova classe de entidade, vamos chamá-la de "Receber", que funcionará como uma classe de entidade associativa (mais adiante veremos porque esta será uma classe de entidade associativa, e não apenas uma classe de nomenclatura entidades, sobre as quais falamos anteriormente). Portanto, nosso diagrama de chaves ficará assim:
Então, agora você pode ver claramente porque a nova classe "Receive" não é uma classe de nomeação de entidades. Afinal, esta classe possui seu próprio atributo adicional "Data - Hora", portanto, de acordo com a definição, a classe recém-introduzida "Recepção" é uma classe de entidades associativas. Esta classe "associa" as classes de entidades "Médicos" e "Pacientes" entre si por meio do horário em que esta ou aquela consulta é realizada, o que torna muito mais conveniente trabalhar com esse banco de dados. Assim, ao introduzir o atributo "Data - Hora", organizamos literalmente o tão necessário horário de trabalho de vários médicos. Também vemos que a chave primária externa "Código do médico" da classe de entidade "Recepção" refere-se à chave primária de mesmo nome da classe de entidade "Médicos". Da mesma forma, a chave primária externa "Código do Paciente" da classe de entidade "Recepção" refere-se à chave primária de mesmo nome na classe de entidade "Paciente". Neste caso, naturalmente, as classes de entidade "Médicos" e "Paciente" são as pai, e a classe de entidade associativa "Recepção", por sua vez, é a única filha. Podemos ver que o relacionamento muitos-para-muitos no diagrama de apresentação anterior agora está totalmente detalhado. Em vez do relacionamento muitos-para-muitos que vemos no diagrama de apresentação acima, temos dois relacionamentos muitos-para-um. O filho final do primeiro relacionamento tem a multiplicidade "muitos", o que significa literalmente que a classe da entidade "Acolhimento" tem muitos médicos (todos eles no hospital). E no final desse relacionamento está a multiplicidade de "um", o que isso significa? Isso significa que na classe de entidade "Recepção", cada um dos códigos disponíveis de cada médico em particular pode ocorrer indefinidamente muitas vezes. De fato, no agendamento no hospital, o código do mesmo médico ocorre várias vezes, em dias e horários diferentes. E aqui está o mesmo código, mas já na classe de entidade "Médicos", pode ocorrer uma vez e apenas uma vez. De fato, na lista de todos os médicos do hospital (e a classe de entidade "Médicos" nada mais é do que essa lista), o código de cada médico em particular pode estar presente apenas uma vez. Algo semelhante acontece com o relacionamento entre a classe pai "Patient" e a classe filha "Patient". Na lista de todos os pacientes do hospital (na classe de entidade "Pacientes"), o código de cada paciente específico pode ocorrer apenas uma vez. Mas por outro lado, no agendamento de consultas (na classe de entidade "Recepção"), cada código de um determinado paciente pode ocorrer arbitrariamente muitas vezes. É por isso que as multiplicidades nas extremidades do vínculo são dispostas dessa maneira. Como exemplo da implementação de uma associação em um modelo de dados relacional, vamos construir um modelo que descreva o cronograma de reuniões entre o cliente e o contratante com a participação opcional de consultores. Não vamos nos deter no diagrama de apresentação, porque precisamos considerar a construção de diagramas em todos os detalhes, e o diagrama de apresentação não pode fornecer essa oportunidade. Então, vamos construir um diagrama chave que reflita a essência do relacionamento entre o cliente, o contratante e o consultor.
Então, vamos começar uma análise detalhada do diagrama chave acima. Primeiramente, a classe "Graph" é uma classe de entidades associativas, mas, como no exemplo anterior, não é uma classe de entidades nomeadas, pois possui um atributo que não migra para ela junto com as chaves, mas é seu próprio atributo. Este é o atributo "Data - Hora". Em segundo lugar, vemos que os atributos da classe de entidade filha "Gráfico" "Código do cliente", "Código do executor" e "Data - Hora" formam uma chave primária composta dessa classe de entidade. O atributo "Advisor Code" é simplesmente uma chave estrangeira da classe de entidade "Chart". Observe que este atributo permite valores Nulos entre seus valores, pois conforme a condição não é necessária a presença de consultor na reunião. Além disso, em terceiro lugar, notamos que os dois primeiros links (dos três links disponíveis) não são totalmente identificáveis. Ou seja, não identificando totalmente, porque a chave de migração em ambos os casos (chaves primárias "Código do cliente" e "Código do executor") não formam completamente a chave primária da classe de entidade "Gráfico". De fato, o atributo "Data - Hora" permanece, que também faz parte da chave primária composta. Nas extremidades desses dois vínculos de identificação incompleta, as multiplicidades "um" e "muitos" são marcadas. Isso é feito para mostrar (como no exemplo sobre médicos e pacientes) a diferença entre mencionar o código do cliente ou do executor em diferentes classes de entidade. De fato, na classe de entidade "Gráfico", qualquer código de cliente ou contratante pode ocorrer quantas vezes desejar. Portanto, nesta extremidade da conexão, filho, há uma multiplicidade de "muitos". E na classe de entidade "Clientes" ou "Empreiteiros", cada um dos códigos do cliente ou contratante, respectivamente, pode ocorrer uma vez e apenas uma vez, porque cada uma dessas classes de entidade nada mais é do que uma lista completa de todos os clientes e executores. Portanto, nesta extremidade principal da conexão, há uma multiplicidade de "um". E, finalmente, observe que o terceiro relacionamento, ou seja, o relacionamento da classe de entidade "Gráfico" com a classe de entidade "Consultores", não é necessariamente não identificador. De fato, neste caso, estamos falando sobre a transferência do atributo-chave "Código do consultor" da classe de entidade "Consultores" para o atributo não-chave da classe de entidade "Gráfico" de mesmo nome, ou seja, a chave primária de a classe de entidade "Consultores" na classe de entidade "Gráfico" não identifica a chave primária já desta classe. Além disso, como mencionado anteriormente, o atributo "Advisor Code" permite valores Null, então aqui é precisamente o relacionamento de não identificação que é usado. Assim, o atributo "Advisor Code" adquire o status de chave estrangeira e nada mais. Prestemos atenção também às multiplicidades de links colocados nas extremidades pai e filho desse link incompletamente não identificador. Sua extremidade pai tem uma multiplicidade de "não mais que um". Com efeito, se recordarmos a definição de uma relação que não é completamente não identificadora, então entenderemos que o atributo "Código do consultor" da classe de entidade "Gráfico" não pode corresponder a mais de um código do consultor da lista de todos os consultores (que é a classe de entidade "Consultores"). E, em geral, pode acontecer que não corresponda a nenhum código de consultor (lembre-se da caixa de seleção para a admissibilidade de valores nulos Código do consultor: nulo), porque de acordo com a condição, a presença de um consultor em um reunião entre o cliente e o contratante, de um modo geral, não é necessária. 4. Generalizações Outro tipo de relacionamento entre classes de entidade, que iremos considerar, é um relacionamento da forma generalização. É também um tipo de relacionamento não recursivo. Assim, um relacionamento como generalização é implementado como um relacionamento de uma classe de entidade pai com várias classes de entidade filha (em contraste com o relacionamento de Associação anterior, que lidava com várias classes de entidade pai e uma classe de entidade filha). Ao formular regras de representação de dados usando o relacionamento de Generalização, deve-se dizer imediatamente que esse relacionamento de uma classe de entidade pai e várias classes de entidade filha é descrito por relacionamentos de identificação total, ou seja, relacionamentos categóricos. Relembrando a definição de identificar totalmente os relacionamentos, concluímos que ao usar a Generalização, cada atributo da chave primária da classe da entidade pai é transferido para a chave primária das classes da entidade filha, ou seja, os atributos da chave primária de migração da classe pai classe de entidade formam completamente as chaves primárias de todas as classes de entidades filhas, elas as identificam. É curioso notar que a Generalização implementa o chamado hierarquia de categorias ou hierarquia de herança. Nesse caso, a classe da entidade pai define classe de entidade genérica, caracterizada por atributos comuns a entidades de todas as classes filhas ou chamadas entidades categóricas ou seja, uma classe de entidade pai é uma generalização literal de todas as suas classes de entidade filha. Como exemplo da implementação da generalização em um modelo de dados relacional, construiremos o seguinte modelo. Este modelo será baseado no conceito generalizado de “Estudantes” e descreverá os seguintes conceitos categóricos (ou seja, generalizará as seguintes classes de entidades filhas): “Alunos”, “Alunos” e “Alunos de Pós-Graduação”. Então, vamos construir um diagrama chave que reflita a essência do relacionamento entre a classe de entidade pai e as classes de entidade filha, descrita por uma conexão do tipo Generalização.
Então, o que vemos? Primeiramente, cada uma das relações básicas (ou de classes de entidade, que é a mesma) "Alunos", "Estudantes" e "Alunos de Pós-Graduação" corresponde a atributos próprios, como "Turma", "Curso" e "Ano Cursado". " . Cada um desses atributos caracteriza os membros de sua própria classe de entidade. Também vemos que a chave primária da classe de entidade pai "Estudantes" migra para cada classe de entidade filha e forma a chave estrangeira primária lá. Com a ajuda dessas conexões, podemos determinar pelo código de qualquer aluno seu nome, sobrenome e patronímico, informações sobre as quais não encontraremos nas próprias classes de entidades filhas correspondentes. Em segundo lugar, como estamos falando de um relacionamento totalmente identificador (ou categórico) de classes de entidade, prestaremos atenção à multiplicidade de relacionamentos entre a classe de entidade pai e suas classes filhas. A extremidade pai de cada um desses links tem uma multiplicidade de "um" e cada extremidade filha dos links tem uma multiplicidade de "no máximo um". Se recordarmos a definição de um relacionamento totalmente identificador de classes de entidade, fica claro que o código realmente único do aluno, que é a chave primária da classe de entidade "Estudantes", especifica no máximo um atributo com tal código em cada entidade filha classe "Estudante", "Estudantes" e Pós-graduados. Portanto, todos os vínculos têm exatamente essas multiplicidades. Vamos escrever um fragmento dos operadores para criar as relações básicas "Alunos" e "Alunos" com a definição de regras para manter a integridade referencial do tipo cascata. Então nós temos: Criar tabela Alunos ... chave primária (código do aluno) chave estrangeira (Student ID) referencia Alunos (Student ID) na atualização em cascata em excluir cascata Criar mesa Alunos ... chave primária (código do aluno) chave estrangeira (Student ID) referencia Alunos (Student ID) na atualização em cascata na cascata de exclusão; Assim, vemos que na classe da entidade filha (ou relacionamento) "Estudante" é especificada uma chave estrangeira primária que se refere à classe da entidade pai (ou relacionamento) "Estudantes". A regra de cascata para manter a integridade referencial determina que, quando os atributos da classe da entidade pai "Estudantes" forem excluídos ou atualizados, os atributos correspondentes da relação filha "Estudante" serão atualizados ou excluídos automaticamente (em cascata). Da mesma forma, quando os atributos da classe de entidade pai "Estudantes" são excluídos ou atualizados, os atributos correspondentes da relação filha "Estudantes" também serão atualizados ou excluídos automaticamente. Refira-se que é esta regra de integridade referencial que aqui se utiliza, pois neste contexto (lista de alunos) não é racional proibir a eliminação e atualização de informação, e também atribuir um valor indefinido em vez de informação real . Agora vamos dar um exemplo das classes de entidade descritas no diagrama anterior, apresentadas apenas em forma de tabela. Assim, temos as seguintes tabelas de relacionamento: Alunos - relacionamento pai que combina informações sobre os atributos de todos os outros relacionamentos:
Crianças em idade escolar - relação infantil:
Alunos - relação de segundo filho:
alunos de doutorado - relação de terceiro filho:
Então, de fato, vemos que as classes filhas de entidades não contêm informações sobre o sobrenome, nome e patronímico dos alunos, ou seja, alunos, alunos e alunos de pós-graduação. Essas informações só podem ser obtidas por meio de referências à classe da entidade pai. Também vemos que diferentes códigos de alunos na classe de entidade "Estudantes" podem corresponder a diferentes classes de entidades filhas. Assim, sobre o aluno com o código "1" Nikolai Zabotin, nada se sabe na relação parental, exceto seu nome, e todas as outras informações (quem ele é, estudante, aluno ou aluno de pós-graduação) só podem ser encontradas referindo-se à classe de entidade filha correspondente (determinada pelo código). Da mesma forma, você precisa trabalhar com o restante dos alunos, cujos códigos são especificados na classe "Estudantes" da entidade pai. 5. Composição O relacionamento de classes de entidade do tipo composição, como os dois anteriores, não pertence ao tipo de relacionamento recursivo. Composição (ou, como às vezes é chamado, agregação composta) é um relacionamento de uma única classe de entidade pai com várias classes de entidade filha, assim como o relacionamento que discutimos acima. Generalização. Mas se a generalização foi definida como um relacionamento de classes de entidades descritas por relacionamentos de identificação completa, então a composição, por sua vez, é descrita por relacionamentos de identificação incompleta, ou seja, durante a composição, cada atributo da chave primária da classe de entidade pai migra para o atributo chave da classe entidade filho. E, ao mesmo tempo, os atributos de chave de migração formam apenas parcialmente a chave primária da classe de entidade filha. Assim, com agregação composta (com composição), a classe de entidade pai (ou agregado) está associado a várias classes de entidades filhas (ou componentes). Nesse caso, os componentes do agregado (ou seja, os componentes da classe da entidade pai) referem-se ao agregado por meio de uma chave estrangeira que faz parte da chave primária e, portanto, não pode existir fora do agregado. Em geral, a agregação composta é uma forma aprimorada de agregação simples (sobre a qual falaremos um pouco mais adiante). Uma composição (ou agregação composta) é caracterizada pelo fato de que: 1) a referência ao conjunto está envolvida na identificação dos componentes; 2) esses componentes não podem existir fora do agregado. Uma agregação (um relacionamento que consideraremos mais adiante) com relacionamentos necessariamente não identificadores também não permite que componentes existam fora do agregado e, portanto, tem um significado próximo à implementação da agregação composta descrita acima. Vamos construir um diagrama chave que descreva o relacionamento entre uma classe de entidade pai e várias classes de entidade filha, ou seja, descrevendo o relacionamento de classes de entidade do tipo de agregação composta. Seja este um diagrama-chave representando a composição dos edifícios de um determinado campus, incluindo edifícios, suas salas de aula e elevadores. Portanto, este diagrama ficará assim:
Então, vamos dar uma olhada no diagrama que acabamos de criar. O que vemos nele? Primeiro, vemos que o relacionamento usado nessa agregação composta é de fato identificador e não totalmente identificador. Afinal, a chave primária da classe de entidade pai "Edifícios" está envolvida na formação da chave primária das classes de entidade filha "Públicos" e "Elevadores", mas não a define completamente. A chave primária "Case No" da classe da entidade pai migra para as chaves primárias estrangeiras "Case No" de ambas as classes filhas, mas, além dessa chave migrada, ambas as classes da entidade filha também possuem sua própria chave primária, respectivamente "Audience Não" e "Nº do elevador", ou seja, as chaves primárias compostas das classes de entidades filhas são apenas atributos parcialmente formados da chave primária da classe de entidade pai. Agora vamos ver as multiplicidades de links que conectam as classes pai e ambas as classes filhas. Como se trata de vínculos identificadores incompletos, as multiplicidades estão presentes: "um" e "muitos". A multiplicidade "um" está presente na extremidade pai de ambos os relacionamentos e simboliza que na lista de todos os corpora disponíveis (e a classe de entidade "Corpus" é exatamente essa lista), cada número pode ocorrer apenas uma vez (e não mais do que isso) vezes. E, por sua vez, dentre os atributos das classes “Público” e “Elevadores”, cada número de prédio pode ocorrer muitas vezes, pois há mais públicos (ou elevadores) do que prédios, e em cada prédio há vários auditórios e elevadores. Assim, ao listar todas as salas de aula e elevadores, inevitavelmente repetiremos os números dos prédios. E, finalmente, como no caso do tipo de conexão anterior, vamos anotar os fragmentos dos operadores para criar relações básicas (ou, o que é a mesma coisa, classes de entidade) "Audiências" e "Elevadores", e vamos fazer isso com a definição de regras para manter a integridade referencial do tipo cascata. Portanto, esta declaração ficaria assim: Criar audiências de tabela ... chave primária (número do corpus, número da audiência) chave estrangeira (número do caso) referências Padrões (número do caso) na atualização em cascata em excluir cascata Criar Tabela Elevações ... chave primária (número do caso, número do elevador) chave estrangeira (número do caso) referências Padrões (número do caso) na atualização em cascata na cascata de exclusão; Assim, definimos todas as chaves primárias e estrangeiras necessárias das classes de entidades filhas. Tomamos novamente a regra de manter a integridade referencial como cascata, pois já a descrevemos como a mais racional. Agora daremos um exemplo em forma de tabela de todas as classes de entidades que acabamos de considerar. Vamos descrever essas relações básicas que refletimos com a ajuda de um diagrama na forma de tabelas e, para maior clareza, introduziremos ali uma certa quantidade de dados indicativos. Conchas O relacionamento pai se parece com isso:
Públicos-alvo - classe de entidade filha:
Elevadores - a segunda classe de entidade filha da classe pai "Enclosures":
Assim, podemos ver como as informações são organizadas para todos os prédios, suas salas de aula e elevadores neste banco de dados, que pode ser usado por qualquer instituição educacional da vida real. 6. Agregação A agregação é o último tipo de relacionamento entre classes de entidade que será considerado como parte de nosso curso. Também não é recursivo, e um de seus dois tipos é bastante próximo em significado à agregação composta considerada anteriormente. Assim, agregação é o relacionamento de uma classe de entidade pai com várias classes de entidade filha. Neste caso, a relação pode ser descrita por dois tipos de relações: 1) links necessariamente não identificáveis; 2) links não identificáveis opcionais. Lembre-se de que, com relacionamentos necessariamente não identificadores, alguns atributos da chave primária da classe da entidade pai são transferidos para um atributo não chave da classe filha, e valores nulos para todos os atributos da chave de migração são proibidos. E com relacionamentos não necessariamente não identificadores, a migração de chaves primárias ocorre exatamente de acordo com o mesmo princípio, mas valores nulos para alguns atributos da chave de migração são permitidos. Ao agregar, a classe de entidade pai (ou agregado) está associado a várias classes de entidades filhas (ou componentes). Os componentes do agregado (ou seja, a classe da entidade pai) referem-se ao agregado por meio de uma chave estrangeira que não faz parte da chave primária e, portanto, no caso não necessariamente relacionamentos de não identificação, os componentes agregados podem existir fora do agregado. No caso da agregação com relacionamentos necessariamente não identificadores, os componentes do agregado não podem existir fora do agregado e, nesse sentido, a agregação com relacionamentos necessariamente não identificadores se aproxima da agregação composta. Agora que ficou claro o que é um relacionamento do tipo agregação, vamos construir um diagrama chave que descreva a operação desse relacionamento. Deixe nosso diagrama futuro descrever os componentes marcados dos carros (ou seja, o motor e o chassi). Ao mesmo tempo, assumiremos que a desativação do carro implica a desativação do chassi junto com ele, mas não implica a desativação simultânea do motor. Portanto, nosso diagrama de chaves fica assim:
Então, o que vemos neste diagrama chave? Primeiramente, o relacionamento da classe da entidade pai “Carros” com a classe da entidade filha “Motores” não é necessariamente não identificador, pois o atributo “car #” permite valores nulos entre seus valores. Por sua vez, este atributo permite valores nulos pelo motivo de que a desativação do motor, por condição, não depende da desativação de todo o veículo e, portanto, não ocorre necessariamente na desativação de um carro. Também vemos que a chave primária "Motor #" da classe de entidade "Carros" migra para o atributo não-chave "Motor #" da classe de entidade "Motores". E, ao mesmo tempo, esse atributo adquire o status de chave estrangeira. E a chave primária nesta classe de entidade Engines é o atributo Engine Marker, que não se refere a nenhum atributo do relacionamento pai. Em segundo lugar, a relação entre a classe da entidade pai “Motores” e a classe da entidade filha “Chassis” é necessariamente uma relação não identificadora, pois o atributo chave estrangeira “Car #” não permite valores Nulos entre seus valores. Esta, por sua vez, ocorre porque se sabe pela condição que a desativação da viatura implica a desativação simultânea obrigatória do chassis. Aqui, assim como no caso do relacionamento anterior, a chave primária da classe de entidade pai "Motores" é migrada para o atributo não-chave "Número do carro" da classe de entidade filha "Chassis". Ao mesmo tempo, a chave primária desta classe de entidade é o atributo "Chassis Marker", que não se refere a nenhum atributo do relacionamento pai "Motores". Ir em frente. Para melhor assimilação do tema, vamos anotar novamente os fragmentos dos operadores para criar as relações básicas "Motores" e "Chassis" com a definição de regras para manter a integridade referencial. Criar motores de tabela ... chave primária (marcador do motor) chave estrangeira (nº do veículo) referencia Carros (nº do veículo) na atualização em cascata ao excluir definir nulo Criar mesa Chassis ... chave primária (marcador do chassi) chave estrangeira (nº do veículo) referencia Carros (nº do veículo) na atualização em cascata na cascata de exclusão; Vemos que usamos a mesma regra para manter a integridade referencial em todos os lugares - cascata, pois mesmo antes a reconhecemos como a mais racional de todas. No entanto, desta vez usamos (além da regra em cascata) a regra de integridade referencial nula definida. Além disso, nós o usamos sob a seguinte condição: se algum valor da chave primária "Número do carro" da classe da entidade pai "Carros" for excluído, o valor da chave estrangeira "Número do carro" da relação filha "Motores" referindo-se a ele será atribuído um valor nulo . 7. Unificação de atributos Se, durante a migração de chaves primárias de uma determinada classe de entidade pai, atributos de diferentes classes pais que coincidem em significado forem para a mesma classe filha, então esses atributos devem ser "mesclados", ou seja, é necessário realizar o procedimento -chamado unificação de atributos. Por exemplo, no caso em que um funcionário pode trabalhar em uma organização, sendo listado em não mais de um departamento, após unificar o atributo "Código da organização", obtemos o seguinte diagrama de chaves:
Ao migrar a chave primária das classes de entidade pai "Organização" e "Departamentos" para a classe filha "Funcionários", o atributo "ID da organização" fica na classe de entidade "Funcionários". E duas vezes: 1) primeira vez com marcador PFK da classe de entidade "Organização" ao estabelecer um relacionamento de identificação incompleta; 2) e a segunda vez, com o marcador FK com a condição de aceitar valores nulos da classe de entidade "Departamentos" ao estabelecer um relacionamento não necessariamente não identificador. Quando unificado, o atributo "ID da organização" assume o status de atributo de chave primária/estrangeira, absorvendo o status do atributo de chave estrangeira. Vamos construir um novo diagrama chave que demonstre o próprio processo de unificação:
Assim, ocorreu a unificação de atributos. Aula nº 13. Sistemas especialistas e modelo de produção de conhecimento 1. Nomeação de sistemas especialistas Para conhecer um conceito tão novo para nós como sistemas especializados nós, para começar, percorreremos a história da criação e desenvolvimento da direção de "sistemas especialistas" e, a seguir, definiremos o próprio conceito de sistemas especialistas. No início dos anos 80. século XNUMX na pesquisa sobre a criação de inteligência artificial, uma nova direção independente foi formada, chamada sistemas especializados. O objetivo desta nova pesquisa em sistemas especialistas é desenvolver programas especiais projetados para resolver tipos específicos de problemas. Qual é esse tipo especial de problema que exigiu a criação de toda uma nova engenharia do conhecimento? Este tipo especial de tarefas pode incluir tarefas de absolutamente qualquer área de assunto. A principal coisa que os distingue dos problemas comuns é que parece ser uma tarefa muito difícil para um especialista humano resolvê-los. Então o primeiro assim chamado sistema inteligente (onde o papel do especialista não era mais uma pessoa, mas uma máquina), e o sistema especialista recebe resultados que não são inferiores em qualidade e eficiência às soluções obtidas por uma pessoa comum - um especialista. Os resultados do trabalho dos sistemas especialistas podem ser explicados ao usuário em um nível muito alto. Essa qualidade dos sistemas especialistas é garantida por sua capacidade de raciocinar sobre seus próprios conhecimentos e conclusões. Sistemas especialistas podem reabastecer seu próprio conhecimento no processo de interação com um especialista. Assim, eles podem ser colocados com total confiança no mesmo nível de uma inteligência artificial totalmente formada. Pesquisadores no campo de sistemas especialistas para o nome de sua disciplina também costumam usar o termo "engenharia do conhecimento", mencionado anteriormente, introduzido pelo cientista alemão E. Feigenbaum como "trazendo os princípios e ferramentas de pesquisa do campo da inteligência artificial para a solução problemas aplicados difíceis que requerem conhecimento especializado”. No entanto, o sucesso comercial das empresas de desenvolvimento não veio imediatamente. Por um quarto de século, de 1960 a 1985. Os sucessos da inteligência artificial têm sido relacionados principalmente ao desenvolvimento de pesquisas. No entanto, começando por volta de 1985 e em grande escala de 1987 a 1990. sistemas especialistas têm sido usados ativamente em aplicações comerciais. Os méritos dos sistemas especialistas são bastante amplos e são os seguintes: 1) a tecnologia de sistemas especialistas expande significativamente a gama de tarefas praticamente significativas resolvidas em computadores pessoais, cuja solução traz benefícios econômicos significativos e simplifica muito todos os processos relacionados; 2) a tecnologia de sistemas especialistas é uma das ferramentas mais importantes na solução dos problemas globais da programação tradicional, como a duração, a qualidade e, conseqüentemente, o alto custo do desenvolvimento de aplicações complexas, com o que o efeito econômico foi significativamente reduzido ; 3) existe um alto custo de operação e manutenção de sistemas complexos, que muitas vezes excede em várias vezes o custo do próprio desenvolvimento, bem como um baixo nível de reutilização de programas, etc.; 4) a combinação da tecnologia de sistemas especialistas com a tecnologia de programação tradicional agrega novas qualidades aos produtos de software ao, em primeiro lugar, proporcionar modificação dinâmica de aplicações por um usuário comum, e não por um programador; em segundo lugar, maior "transparência" da aplicação, melhores gráficos, interface e interação dos sistemas especialistas. De acordo com usuários comuns e especialistas líderes, em um futuro próximo, os sistemas especialistas encontrarão as seguintes aplicações: 1) os sistemas especialistas desempenharão um papel de liderança em todos os estágios de projeto, desenvolvimento, produção, distribuição, depuração, controle e entrega de serviços; 2) a tecnologia de sistemas especialistas, que recebeu ampla distribuição comercial, fornecerá um avanço revolucionário na integração de aplicativos de módulos interativos inteligentes prontos. Em geral, os sistemas especialistas são projetados para os chamados tarefas informais, ou seja, os sistemas especialistas não rejeitam e não substituem a abordagem tradicional de desenvolvimento de programas com foco na resolução de problemas formalizados, mas os complementam, ampliando significativamente as possibilidades. Isso é exatamente o que um mero especialista humano não pode fazer. Tais tarefas não formalizadas complexas são caracterizadas por: 1) falácia, imprecisão, ambiguidade, bem como incompletude e inconsistência dos dados de origem; 2) falácia, ambigüidade, imprecisão, incompletude e inconsistência de conhecimento sobre a área do problema e o problema a ser resolvido; 3) grande dimensão do espaço de soluções de um problema específico; 4) variabilidade dinâmica de dados e conhecimento diretamente no processo de resolução de um problema tão informal. Sistemas especialistas são baseados principalmente na busca heurística de uma solução, e não na execução de um algoritmo conhecido. Essa é uma das principais vantagens da tecnologia de sistemas especialistas em relação à abordagem tradicional de desenvolvimento de software. É isso que lhes permite lidar tão bem com as tarefas que lhes são atribuídas. A tecnologia de sistemas especialistas é usada para resolver uma variedade de problemas. Listamos as principais dessas tarefas. 1. Interpretação. Os sistemas especialistas que executam a interpretação geralmente usam as leituras de vários instrumentos para descrever o estado das coisas. Sistemas especialistas interpretativos são capazes de processar uma variedade de tipos de informação. Um exemplo é o uso de dados de análise espectral e mudanças nas características das substâncias para determinar sua composição e propriedades. Também um exemplo é a interpretação das leituras dos instrumentos de medição na sala das caldeiras para descrever o estado das caldeiras e a água nelas contida. Os sistemas interpretativos geralmente lidam diretamente com indicações. Nesse sentido, surgem dificuldades que outros tipos de sistemas não possuem. Quais são essas dificuldades? Essas dificuldades surgem devido ao fato de que os sistemas especialistas têm que interpretar informações supérfluas, incompletas, não confiáveis ou incorretas. Portanto, erros ou um aumento significativo no processamento de dados são inevitáveis. 2. Predição. Os sistemas especialistas que realizam uma previsão de algo determinam as condições probabilísticas de determinadas situações. São exemplos a previsão de prejuízos causados à safra de grãos por condições climáticas adversas, a avaliação da demanda de gás no mercado mundial, a previsão do tempo por meio de estações meteorológicas. Os sistemas de previsão às vezes usam modelagem, ou seja, programas que exibem alguns relacionamentos no mundo real para recriá-los em um ambiente de programação e, em seguida, projetar situações que possam surgir com determinados dados iniciais. 3. Diagnóstico de vários dispositivos. Os sistemas especialistas realizam tais diagnósticos usando descrições de qualquer situação, comportamento ou dados sobre a estrutura de vários componentes, a fim de determinar as possíveis causas de um sistema diagnosticável com defeito. Exemplos são o estabelecimento das circunstâncias da doença pelos sintomas que são observados nos pacientes (na medicina); identificação de falhas em circuitos eletrônicos e identificação de componentes defeituosos nos mecanismos de vários dispositivos. Os sistemas de diagnóstico muitas vezes são assistentes que não apenas fazem um diagnóstico, mas também ajudam na solução de problemas. Nesses casos, esses sistemas podem interagir com o usuário para ajudar na solução de problemas e fornecer uma lista de ações necessárias para resolvê-los. Atualmente, muitos sistemas de diagnóstico estão sendo desenvolvidos como aplicações para engenharia e sistemas de computação. 4. Planejando vários eventos. Sistemas especialistas projetados para planejar várias operações. Os sistemas predeterminam uma sequência quase completa de ações antes de sua implementação começar. Exemplos desse planejamento de eventos são a criação de planos para operações militares, tanto defensivas quanto ofensivas, predeterminadas por um determinado período, a fim de obter vantagem sobre as forças inimigas. 5. Projeto. Os sistemas especialistas que executam o design desenvolvem várias formas de objetos, levando em consideração as circunstâncias predominantes e todos os fatores relacionados. Um exemplo é a engenharia genética. 6. Controlar. Sistemas especialistas que exercem controle comparam o comportamento atual do sistema com seu comportamento esperado. A observação de sistemas especialistas detecta comportamento controlado que confirma suas expectativas versus comportamento normal ou suposição de possíveis desvios. Os sistemas especialistas de controle, por sua própria natureza, devem funcionar em tempo real e implementar uma interpretação dependente do tempo e do contexto do comportamento do objeto controlado. Exemplos incluem monitorar as leituras de instrumentos de medição em reatores nucleares para detectar emergências ou avaliar dados de diagnóstico de pacientes na unidade de terapia intensiva. 7. Управление. Afinal, é amplamente conhecido que os sistemas especialistas que exercem controle, gerenciam de forma muito eficaz o comportamento do sistema como um todo. Um exemplo é a gestão de várias indústrias, bem como a distribuição de sistemas de computador. Sistemas especialistas de controle devem incluir componentes de observação para controlar o comportamento de um objeto por um longo período de tempo, mas também podem precisar de outros componentes dos tipos de tarefas já analisadas. Os sistemas especialistas são usados em diversas áreas: transações financeiras, indústria de petróleo e gás. A tecnologia de sistemas especialistas também pode ser aplicada em energia, transporte, indústria farmacêutica, desenvolvimento espacial, indústrias metalúrgicas e de mineração, química e muitas outras áreas. 2. Estrutura de sistemas especialistas O desenvolvimento de sistemas especialistas tem uma série de diferenças significativas em relação ao desenvolvimento de um produto de software convencional. A experiência de criação de sistemas especialistas mostrou que a utilização da metodologia adotada na programação tradicional em seu desenvolvimento aumenta muito o tempo gasto na criação de sistemas especialistas, ou mesmo leva a um resultado negativo. Os sistemas especialistas são geralmente divididos em estático и dinâmico. Primeiro, considere um sistema especialista estático. padrão sistema especialista estático consiste nos seguintes componentes principais: 1) memória de trabalho, também chamada de banco de dados; 2) bases de conhecimento; 3) um solucionador, também chamado de interpretador; 4) componentes de aquisição de conhecimento; 5) componente explicativa; 6) componente de diálogo. Vamos agora considerar cada componente com mais detalhes. memória de trabalho (por analogia absoluta com o trabalho, ou seja, RAM do computador) é projetado para receber e armazenar os dados iniciais e intermediários da tarefa que está sendo resolvida no momento atual. Base de Conhecimento é projetado para armazenar dados de longo prazo que descrevem uma área de assunto específica e regras que descrevem a transformação racional de dados nesta área do problema que está sendo resolvido. Solvertambém chamado intérprete, funciona da seguinte forma: a partir dos dados iniciais da memória de trabalho e dos dados de longo prazo da base de conhecimento, forma as regras, cuja aplicação aos dados iniciais leva à solução do problema. Em uma palavra, ele realmente "resolve" o problema colocado diante dele; Componente de Aquisição de Conhecimento automatiza o processo de preenchimento do sistema especialista com conhecimento especializado, ou seja, é esse componente que fornece à base de conhecimento todas as informações necessárias dessa área de assunto específica. Explicar o componente explica como o sistema obteve uma solução para este problema, ou porque não recebeu esta solução, e que conhecimento utilizou para fazê-lo. Em outras palavras, o componente de explicação gera um relatório de andamento. Este componente é muito importante em todo o sistema especialista, pois facilita muito o teste do sistema por um especialista, além de aumentar a confiança do usuário no resultado obtido e, portanto, agilizar o processo de desenvolvimento. Componente de Diálogo serve para fornecer uma interface de usuário amigável tanto no curso da resolução de um problema quanto no processo de aquisição de conhecimento e declaração dos resultados do trabalho. Agora que sabemos em quais componentes um sistema especialista estatístico geralmente consiste, vamos construir um diagrama que reflita a estrutura desse sistema especialista. Se parece com isso:
Os sistemas especialistas estáticos são mais frequentemente usados em aplicações técnicas onde é possível não levar em consideração as mudanças no ambiente que ocorrem durante a solução de um problema. É curioso saber que os primeiros sistemas especialistas que receberam aplicação prática eram precisamente estáticos. Então, com isso terminaremos a consideração do sistema especialista estatístico por enquanto, vamos passar para a análise do sistema especialista dinâmico. Infelizmente, o programa do nosso curso não inclui uma consideração detalhada deste sistema especialista, então nos limitaremos a analisar apenas as diferenças mais básicas entre um sistema especialista dinâmico e um estático. Ao contrário de um sistema especialista estático, a estrutura sistema especialista dinâmico Além disso, os dois componentes a seguir são introduzidos: 1) um subsistema para modelar o mundo exterior; 2) um subsistema de relações com o ambiente externo. Subsistema de relações com o ambiente externo Apenas faz conexões com o mundo exterior. Ela faz isso por meio de um sistema de sensores e controladores especiais. Além disso, alguns componentes tradicionais de um sistema especialista estático sofrem mudanças significativas para refletir a lógica temporal dos eventos que ocorrem atualmente no ambiente. Esta é a principal diferença entre sistemas especialistas estáticos e dinâmicos. Um exemplo de sistema especialista dinâmico é o gerenciamento da produção de vários medicamentos na indústria farmacêutica. 3. Participantes no desenvolvimento de sistemas especialistas Representantes de várias especialidades estão envolvidos no desenvolvimento de sistemas especialistas. Na maioria das vezes, um sistema especialista específico é desenvolvido por três especialistas. Isso geralmente é: 1) especialista; 2) engenheiro do conhecimento; 3) um programador para o desenvolvimento de ferramentas. Vamos explicar as responsabilidades de cada um dos especialistas listados aqui. especialista é um especialista na área do assunto, cujas tarefas serão resolvidas com a ajuda desse sistema especialista específico que está sendo desenvolvido. Engenheiro do conhecimento é um especialista no desenvolvimento de um sistema especialista diretamente. As tecnologias e métodos utilizados por ele são chamados de tecnologias e métodos de engenharia do conhecimento. Um engenheiro do conhecimento ajuda um especialista a identificar, a partir de todas as informações da área de assunto, as informações necessárias para trabalhar com um determinado sistema especialista que está sendo desenvolvido e, a seguir, estruturá-lo. É curioso que a ausência de engenheiros do conhecimento entre os participantes do desenvolvimento, ou seja, sua substituição por programadores, ou leve ao fracasso de todo o projeto de criação de um sistema especialista específico, ou aumente significativamente o tempo para seu desenvolvimento. E, finalmente, programador desenvolve ferramentas (se as ferramentas forem desenvolvidas recentemente) projetadas para acelerar o desenvolvimento de sistemas especialistas. Essas ferramentas contêm, no limite, todos os principais componentes de um sistema especialista; o programador também faz a interface de suas ferramentas com o ambiente em que será utilizado. 4. Modos de operação de sistemas especialistas O sistema especialista opera em dois modos principais: 1) no modo de adquirir conhecimento; 2) no modo de resolução do problema (também chamado de modo de consultas ou modo de uso do sistema especialista). Isso é lógico e compreensível, porque primeiro é necessário, por assim dizer, carregar o sistema especialista com informações da área de assunto em que ele deve trabalhar, esse é o modo "treinamento" do sistema especialista, o modo quando ele recebe conhecimento. E depois de carregar todas as informações necessárias para o trabalho, segue o próprio trabalho. O sistema especialista fica pronto para operação, podendo ser utilizado para consultas ou resolução de problemas. Vamos considerar com mais detalhes modo de aquisição de conhecimento. Na modalidade de aquisição de conhecimento, o trabalho com o sistema especialista é realizado por um especialista por meio de um engenheiro do conhecimento. Nesse modo, o especialista, utilizando o componente de aquisição de conhecimento, preenche o sistema com conhecimento (dados), que, por sua vez, permite que o sistema resolva problemas dessa área temática no modo solução sem a participação de um especialista. Deve-se notar que o modo de aquisição de conhecimento na abordagem tradicional de desenvolvimento de programas corresponde às etapas de algoritmização, programação e depuração realizadas diretamente pelo programador. Conclui-se que, ao contrário da abordagem tradicional, no caso dos sistemas especialistas, o desenvolvimento de programas é realizado não por um programador, mas por um especialista, claro, com o auxílio de sistemas especialistas, ou seja, em geral , uma pessoa que não sabe programar. E agora vamos considerar o segundo modo de funcionamento do sistema especialista, ou seja. modo de resolução de problemas. No modo de solução de problemas (ou o chamado modo de consulta), a comunicação com os sistemas especialistas é realizada diretamente pelo usuário final, que está interessado no resultado final do trabalho e, às vezes, no método de obtenção. Deve-se observar que, dependendo da finalidade do sistema especialista, o usuário não precisa ser um especialista nessa área problemática. Nesse caso, ele recorre a sistemas especialistas para obter o resultado, não tendo conhecimento suficiente para obter resultados. Ou, o usuário ainda pode ter um nível de conhecimento suficiente para atingir o resultado desejado por conta própria. Nesse caso, o próprio usuário pode obter o resultado, mas recorre aos sistemas especialistas para acelerar o processo de obtenção do resultado ou para atribuir um trabalho monótono aos sistemas especialistas. No modo de consulta, os dados sobre a tarefa do usuário, após serem processados pelo componente de diálogo, entram na memória de trabalho. O solucionador, com base nos dados de entrada da memória de trabalho, dados gerais sobre a área do problema e regras do banco de dados, gera uma solução para o problema. Ao resolver um problema, os sistemas especialistas não apenas executam a sequência prescrita de uma operação específica, mas também a formam preliminarmente. Isso é feito para o caso em que a reação do sistema não é totalmente clara para o usuário. Nesta situação, o usuário pode exigir uma explicação de por que este ou aquele sistema especialista faz esta ou aquela pergunta ou porque este sistema especialista não pode realizar esta operação, como este ou aquele resultado fornecido por este sistema especialista é obtido. 5. Modelo de produção do conhecimento Na sua essência, modelos de produção de conhecimento próximo a modelos lógicos, o que permite organizar procedimentos muito eficazes para inferência lógica de dados. Isso é por um lado. Porém, por outro lado, se considerarmos os modelos de produção de conhecimento em comparação com os modelos lógicos, os primeiros apresentam mais claramente o conhecimento, o que é uma vantagem indiscutível. Portanto, sem dúvida, o modelo de produção de conhecimento é um dos principais meios de representação do conhecimento em sistemas de inteligência artificial. Então, vamos começar uma consideração detalhada do conceito de um modelo de produção de conhecimento. O modelo tradicional de produção de conhecimento inclui os seguintes componentes básicos: 1) um conjunto de regras (ou produções) representando a base de conhecimento do sistema de produção; 2) memória de trabalho, que armazena os fatos originais, bem como os fatos derivados dos fatos originais usando o mecanismo de inferência; 3) o próprio mecanismo de inferência lógica, que permite, a partir dos fatos disponíveis, de acordo com as regras de inferência existentes, derivar novos fatos. E, curiosamente, o número dessas operações pode ser infinito. Cada regra que representa a base de conhecimento do sistema de produção contém uma parte condicional e uma parte final. A parte condicional da regra contém um único fato ou vários fatos conectados por uma conjunção. A parte final da regra contém fatos que precisam ser reabastecidos com memória de trabalho se a parte condicional da regra for verdadeira. Se tentarmos esquematizar o modelo de produção do conhecimento, então a produção é entendida como uma expressão da seguinte forma: (i) Q; P; A→B; N; Aqui i é o nome do modelo de produção do conhecimento ou seu número de série, com o qual essa produção se distingue de todo o conjunto de modelos de produção, recebendo algum tipo de identificação. Alguma unidade lexical que reflita a essência deste produto pode atuar como um nome. Na verdade, nomeamos produtos para melhor percepção pela consciência, a fim de simplificar a busca do produto desejado na lista. Tomemos um exemplo simples: comprar um caderno" ou "um conjunto de lápis de cor. Obviamente, cada produto costuma ser referido por palavras adequadas ao momento. Em outras palavras, chame uma pá de pá. Ir em frente. O elemento Q caracteriza o escopo desse modelo particular de produção de conhecimento. Tais esferas são facilmente distinguidas na mente humana, portanto, via de regra, não há dificuldades com a definição desse elemento. Vamos dar um exemplo. Consideremos a seguinte situação: digamos que em uma área de nossa consciência esteja armazenado o conhecimento de como cozinhar alimentos, em outra, como começar a trabalhar, na terceira, como operar corretamente a máquina de lavar. Uma divisão semelhante também está presente na memória do modelo de produção do conhecimento. Essa divisão do conhecimento em áreas separadas pode economizar significativamente o tempo gasto na busca de alguns modelos específicos de produção de conhecimento necessários no momento e, assim, simplificar muito o processo de trabalho com eles. Obviamente, o principal elemento da produção é o chamado núcleo, que em nossa fórmula acima foi denotado como A → B. Essa fórmula pode ser interpretada como "se a condição A for atendida, a ação B deve ser executada". Se estivermos lidando com construções de kernel mais complexas, a seguinte escolha alternativa é permitida no lado direito: "se a condição A for satisfeita, então a ação B deve ser executada1, caso contrário, você deve executar a ação B2". No entanto, a interpretação do núcleo do modelo de produção de conhecimento pode ser diferente e depende do que estará à esquerda e à direita do sinal seqüencial "→". Com uma das interpretações do núcleo do modelo de produção de conhecimento, o seqüente pode ser interpretado no sentido lógico usual, ou seja, como signo da consequência lógica da ação B a partir da verdadeira condição A. No entanto, outras interpretações do cerne do modelo de produção do conhecimento também são possíveis. Assim, por exemplo, A pode descrever alguma condição, cujo cumprimento é necessário para que alguma ação B seja executada. Em seguida, consideramos um elemento do modelo de produção de conhecimento R. Elemento Р é definido como condição para a aplicabilidade do núcleo do produto. Se a condição P for verdadeira, então o núcleo de produção é ativado. Caso contrário, se a condição P não for satisfeita, ou seja, falsa, o núcleo não pode ser ativado. Como exemplo ilustrativo, considere o seguinte modelo de produção de conhecimento: "Disponibilidade de dinheiro"; "Se você deseja comprar a coisa A, deve pagar seu custo ao caixa e apresentar o cheque ao vendedor." Olhamos, se a condição P for verdadeira, ou seja, a compra for paga e o cheque for apresentado, então o núcleo é acionado. Compra concluída. Se nesse modelo de produção de conhecimento a condição de aplicabilidade do núcleo for falsa, ou seja, se não houver dinheiro, então é impossível aplicar o núcleo do modelo de produção de conhecimento, e ele não é acionado. E finalmente vá para o elemento N. O elemento N é chamado de pós-condição do modelo de dados de produção. A pós-condição define as ações e procedimentos que devem ser executados após a implementação do núcleo de produção. Para uma melhor percepção, vamos dar um exemplo simples: depois de comprar uma coisa em uma loja, é necessário reduzir a quantidade de coisas desse tipo em um no estoque de mercadorias dessa loja, ou seja, se a compra for feita (daí , o núcleo é vendido), então a loja tem uma unidade deste determinado produto a menos. Daí a pós-condição "Riscar a unidade do item comprado". Resumindo, podemos dizer que a representação do conhecimento como um conjunto de regras, ou seja, através da utilização de um modelo de produção de conhecimento, tem as seguintes vantagens: 1) é a facilidade de criar e entender regras individuais; 2) é a simplicidade do mecanismo de escolha lógica. No entanto, na representação do conhecimento na forma de um conjunto de regras, também existem desvantagens que ainda limitam o alcance e a frequência de aplicação dos modelos de produção de conhecimento. A principal dessas desvantagens é a ambigüidade das relações mútuas entre as regras que compõem um modelo específico de produção do conhecimento, bem como as regras de escolha lógica. Notas 1. A fonte sublinhada na edição impressa do livro corresponde a negrito itálico nesta versão (eletrônica) do livro. (Aprox. e. ed.)
▪ Teoria do Governo e Direitos. Berço ▪ Terapia da Faculdade. Notas de aula
Couro artificial para emulação de toque
15.04.2024 Areia para gatos Petgugu Global
15.04.2024 A atratividade de homens atenciosos
14.04.2024
▪ Os militares doaram dois telescópios espaciais para a NASA ▪ Flash embutido de 28nm para microcontroladores ▪ Nanopartículas criadas que reduzem o inchaço do cérebro
▪ seção do site Equipamento de soldagem. Seleção de artigos ▪ artigo de Solomon Gessner. Aforismos famosos ▪ artigo Santalum branco. Lendas, cultivo, métodos de aplicação ▪ artigo Quem é mais rápido? Enciclopédia de rádio eletrônica e engenharia elétrica ▪ artigo Comutador de antena de 144 MHz. Enciclopédia de rádio eletrônica e engenharia elétrica
Página principal | Biblioteca | Artigos | Mapa do Site | Revisões do site
www.diagrama.com.ua |



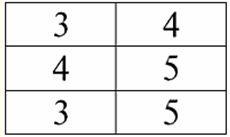
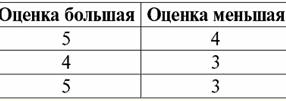

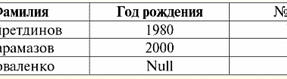

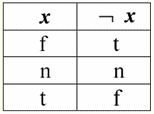

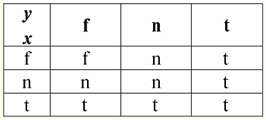
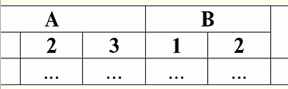


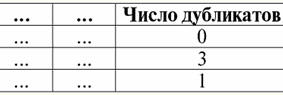
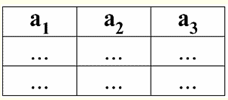






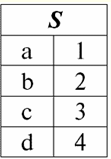
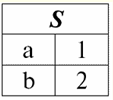

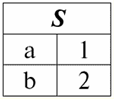

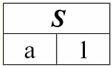
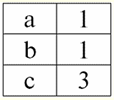

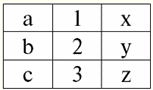









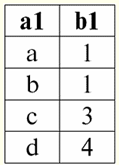






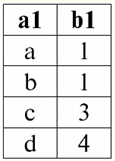



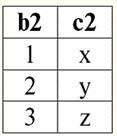

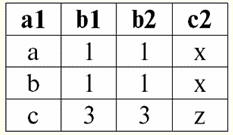
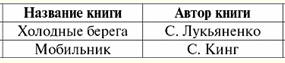




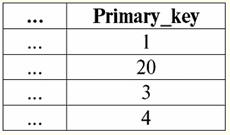

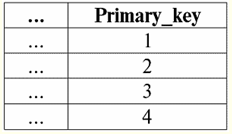

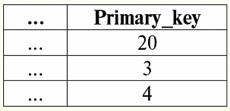
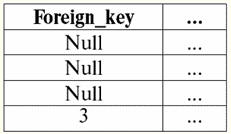

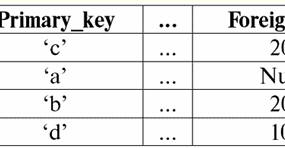











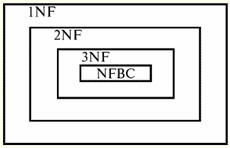

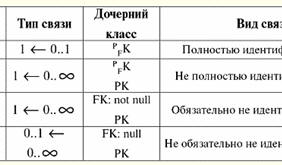









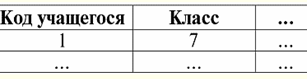
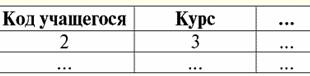





 Veja outros artigos seção
Veja outros artigos seção 